Understanding AI, Machine Learning, Neural Networks, and Deep Learning
인공지능, 머신러닝, 인공신경망과 딥러닝: 컴퓨터학개론 13주
Contents
1️⃣인공지능 (Artificial Intelligence)
2️⃣머신러닝 (Machine Learning)
3️⃣인공신경망 (Artificial Neural Networks)
4️⃣딥러닝 (Deep Learning)
📍인공지능은 언제부터 나타났을까?
(When Did Artificial Intelligence First Appear?)
Recently, artificial intelligence has been applied across all aspects of life and business, becoming pervasive in society. While it may seem like a new concept, artificial intelligence has been around since the development of computers. The idea that "computers might be able to replace humans" existed in the past, and the efforts made towards this goal have started to show results.
최근에 인공지능은 모든 생활, 비니지스등 사회 전반에 적용되고 있다. 새로운 개념이라고 볼 수 있겠지만 인공지능은 컴퓨터가 개발되면서부터 나타난 개념이다. "컴퓨터가 사람을 대체할 수 있지 않을까" 라는 생각은 과거에도 존재했고 노력해온 효과가 나타나기 시작하였다.
1️⃣인공지능 (Artificial Intelligence)
개요 (Overview of AI)
위키피디아에서는 "기계(컴퓨터)에 의해 표출되는 지능 ” 즉 컴퓨터가 지능을 갖는다라고 정의하고 있다.
'지능'이란 무엇일까? 사람이 문제에 대해 합리적으로 사고하고 해결하는 인지적인 능력(Cognitive ability)과 학습 능력(learning ability)을 포함하는 총체적인 능력이다.
결론적으로 인공지능이란 인간의 사고, 학습, 자기 개발 등을 컴퓨터가 할 수 있도록 하는 것이라고 할 수 있다.
목표 (Goal of AI)
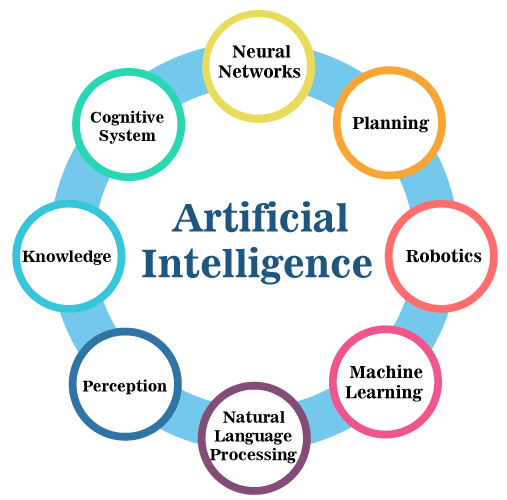
사람처럼 생각하고 행동할 수 있는 기계를 개발하는 것이다. 컴퓨터가 인간의 지능적인 행동을 모방할 수 있도록 하는 기술을 구현한다. 요즘에는 모방을 넘어서 창작의 범위까지 늘어나고 있다. 인간의 지능으로 수행할 수 있는 다양한 인식, 사고, 학습 활동 등을 컴퓨터가 할 수 있도록 하는 방법을 연구하는 분야이다.
AI의 성능을 측정하는 방법
(The methods for evaluating AI performance)
튜링테스트(Turing test)
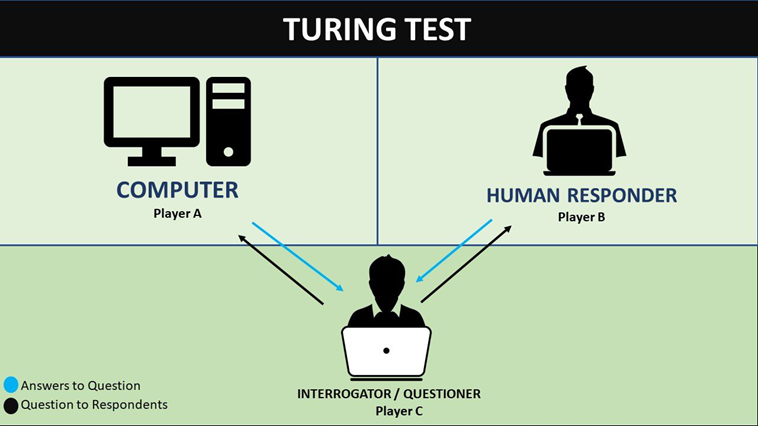
1950년 앨런 튜링이 제시하였다. 기계가 얼마나 인간과 비슷하게 대화할 수 있는지 판단한다. 누가 컴퓨터고, 사람인지 모르는 상태에서 사람(C)이 기계(A)와 사람(B)과 번갈아 대화하여 어느 쪽이 사람인지 판단하기 힘들다면 인공지능이라고 판단하는 테스트
아직까지 튜링테스트를 통과한 사례는 1건이 있다.
Eugene Goostman (유진 구스트만)
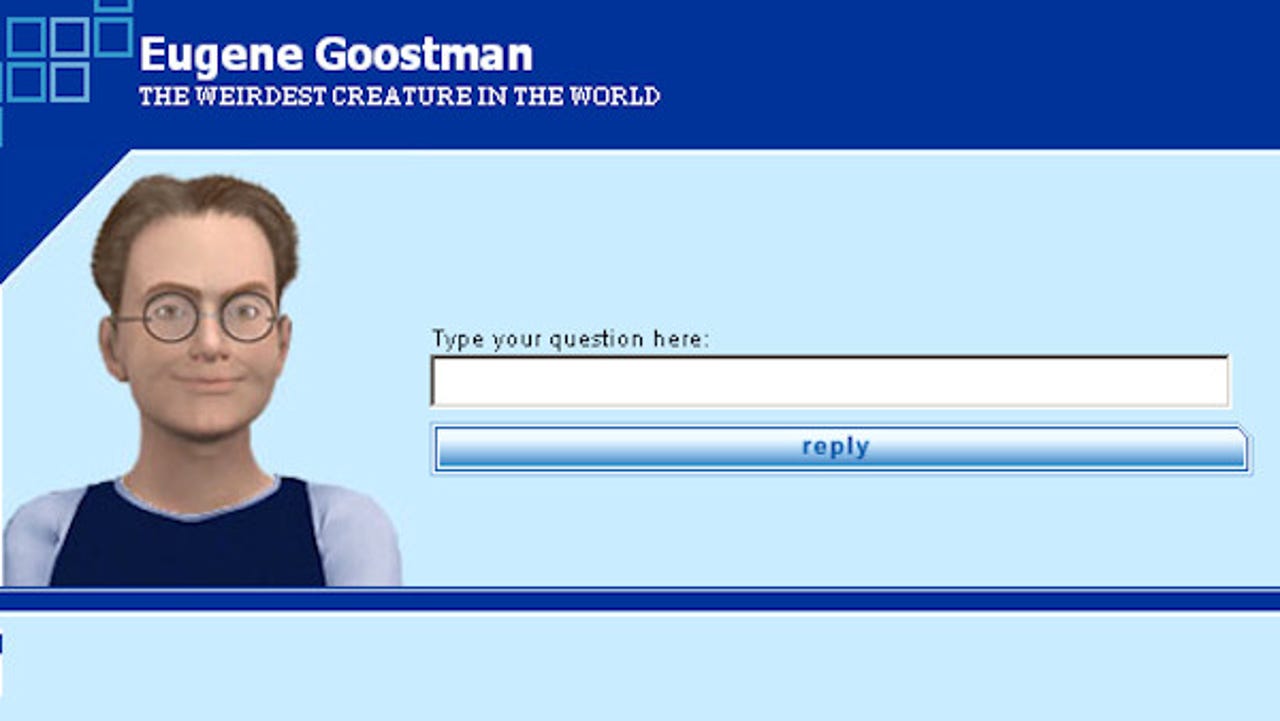
2014년 영국 레딩 대학에서 개발하였다. 우크라이나에 사는 13세 소년으로 가정하고 대화하였다. 판정단 중 30%를 통과하면 합격인데 33%로 통과하였다고 한다. 하지만 나중에 기자들이 다시 테스트해보니 더 낮은 결과가 나온 케이스이다.
인간과 같이 생각하는 컴퓨터는 아직 미완성이라고 할 수 있다.
인공지능 세분화(Classification of AI)

강한 인공지능 (Strong AI)
인간의 지능을 구현하는 기술이다. 사람처럼 생각하는 기계를 만드는 기술을 칭한다. 말도 잘 이해하고, 인지능력도 높아 창의적인 아이디어를 내고 문제 해결하는 인공지능이다. 아직 미완성 단계이고 매우 어려운 일인데 이 기술을 구현하기 위해 많은 국가/대기업들이 노력하고 있다.
약한 인공지능 (Weak AI)
일상생활에서 자주 사용된다. 인간의 지능을 모방하여 특정한 문제를 푸는 기술이다. 무인자동차, 공장에서의 오류탐지, 콜센터 등이 있다. 때로는 인간 보다 우수할 수 있는 영역이기도 한다.
생활속의 인공지능(AI in daily life)
1️⃣보안: 지문인식기술, 얼굴인식기술

2️⃣언어 : 번역기술과 음성인식 기술

인공지능의 성장과정 (Development of AI)

컴퓨터가 등장하면서 AI의 개념은 정립되었다.
생활속에 적용하려니 구현이 어려워 암흑기가 찾아왔다.
2010년 딥러닝 기술의 등장으로 쭉 성장해왔다.
2016년: 이전에 바둑은 컴퓨터가 뛰어넘을 수 없는 영역이었다.
2023, 2024: ChatGPT의 등장
인공지능의 역사 (History of AI)

연구성과는 좋았지만 실생활에 적용하는 것이 불가능해 첫번째 암흑기가 찾아왔다.
2024년 기준 기계학습과 딥러닝으로 3번째 전성기를 겪고 있다.

ChatGPT의 등장으로 위의 사건들이 당연하다고? 생각할 수도 있겠지만 그 당시에는 큰 사건이었다. 인공지능이 침범할 수 없을것 이라고 인식되었던 바둑도 성공적이었다.
인공지능 발전의 핵심 요소(Core of AI progress)

컴퓨터의 발전과 함께 현재 데이터가 엄청난 속도로 쌓여지고 있다. 이 쌓여진 데이터를 기반으로 학습하기 때문에 사람을 따라잡을 수 있게 되었다.
Improving Artificial Intelligence Performance

아까 언급된 튜링테스트는 컴퓨터의 인지기능을 테스트하는 것이고 이미지 인식의 성능을 측정하는 '이미지넷' 이라는 곳이 있다. 과정은 튜링테스트와 비슷하다.
2010년만해도 인식률이 낮았지만 딥러닝의 등장이후로 이미지 인식의 결과가 시간이 갈수록 늘어나고 있음을 확인할 수 있다. 사람의 인식률은 94.9%로 2015년에 사람의 능력을 추월하였다.
The pace of artificial intelligence development

📍인공지능은 어떻게 학습할까?
(How Does Artificial Intelligence Learn?)
One of the core technologies of artificial intelligence is 'learning.' This involves a computer discovering knowledge and patterns from data through learning. The computer learns based on 'learning models' created by humans. As a result, when presented with a new situation, the computer makes decisions based on these learning models.
인공지능의 핵심 기술중 하나는 '학습'이다. 컴퓨터가 데이터로부터 학습을 통해서 지식, 패턴을 찾아내는 것이다. 컴퓨터는 인간이 만들어놓은 '학습모델'을 기반으로 컴퓨터가 학습을 한다. 이로인해 컴퓨터는 새로운 상황이 주어졌을때, 학습모델을 기준으로 결정을 내리게 된다.
2️⃣머신러닝 (Machine Learning)
개요(Overview of Machine Learning)
아래 사진에서 볼 수 있듯이 인공지능의 분야는 아주 넓다.
머신러닝은 인공지능에 포함한다. 딥러닝은 머신러닝의 일부분이다.

많은 양의 데이터를 기반으로 컴퓨터가 직접 규칙을 찾고 복잡한 문제를 잘 해결한다. 단점으로는 규칙을 찾게 된 이유를 설명하지는 못한다.

사람은 사물을 보고 무엇인지 판단한다. 볼펜을 보면 볼펜이라고 판단하듯이 말이다. 왜 볼펜이냐고 물으면 끝이 뾰족해서, 볼펜처럼 생겨서 와같이 규칙적인 이유는 언급하지 않듯이 인공지능도 마찬가지이다. 데이터로부터 새로운 볼펜의 이미지를 학습하면 새로운 볼펜의 이미지 모델이 생긴다. 기존의 볼펜과 다르더라도 '새로운 데이터'로 받아들여 몇 %까지 비슷한지 판단하여 결과를 내놓는다. '왜' %인지는 설명하지 못한다.
접근 방법 2가지
(How Machine Learning approach to solve a problem - 2 methods)
아래 2가지 모두 지능형 시스템(인공지능)에 해당한다.

💡규칙 기반 방법: 확률과 정해진 규칙으로 결정을 내린다. (일기예보 등)
💡데이터 기반 방법: 데이터로부터 컴퓨터가 스스로 학습하여 지식과 모델을 가지고 있다.
💡 규칙 기반 인공지능
기본적인 동작원리

추론의 예는 아래와 같다.

규칙 기반 방법을 이용한 제품: 전문가 시스템(Expert System)
위의 원리를 바탕으로 많은 지식, 추론을 넣어놓은 것을 '전문가 시스템'이라고한다. 전문가의 행동, 사고과정을 모방하는 방식이다. 특정 부분에서는 잘 동작하는 경향을 보인다.

지식 베이스를 기반으로 추론 기구 (추론 알고리즘)을 이용해 문제를 해결한다.
입력된 지식이나 판단을 통해 새로운 지식을 구축하는 구조이다.
인간의 지식을 추출하여 컴퓨터에 입력하는 과정이 중요하다.
단순한 문제는 비교적 정확한 분류 및 예층이 가능하지만
복잡한 문제, 현실 문제는 단순하지 않으므로 규칙이 점점 길고 복잡해지는 한계가 있다. 이 한계를 극복하지 못한다면 제2의 인공지능 암흑기가 올 가능성이 높았다.
💡데이터(학습) 기반 인공지능
때마침 등장한 개념이다. 사람이 규칙과 지식을 입력하는 것의 한계를 딛고 컴퓨터가 능동적으로 학습하도록 시도한 것이 머신러닝의 시작이었다.

머신러닝은 컴퓨터가 데이터를 통해 스스로 규칙을 학습하는데 의사결정트리, 서포트백터머신, 선형회귀, 인공신경망 등이 사용되고 자세한 내용은 인공지능 과목에서 배울 수 있다.
딥러닝 : 인공신경망을 여러 층으로 만들어 복잡한 문제를 해결하고 CNN, RNN, RBM으로 나뉘어진다.
머신러닝의 종류 (Type of Machine learning)
머신러닝의 방법에 따라 지도학습, 비지도학습, 강화학습 모델로 구분된다. 레이블(명시적인 정답)의 여부에 따라 구분한다. (예: 빨간 볼펜, 형광펜, 파란 볼펜 등)

💡 지도학습 (Supervised Leaning)
사전에 정답 데이터를 제공한다. 컴퓨터는 규칙과 패턴을 스스로 학습하고 목적에 따라 분류(Classification)와 회귀(Regression)로 구분한다.

분류(Classification) 데이터에 레이블(Label)을 지정하여 학습 시키는 방법이다. 즉 데이터가 특정 클래스에 속하는지는 판단하는 학습모델이다. 스무고개와 유사한 의사결정트리 알고리즘 및 그외 알고리즘 이용하여 구현한다. 실제 생활에서는 스팸메일 필터가 해당한다.

회귀(Regression) 기존에 알고 있는 데이터를 바탕으로 앞으로 일어날 사건을 예측한다. 수학적인 분석 방법에 속한다. 선형 회귀, 의사결정 트리 알고리즘 등을 이용해서 구현한다.
지도학습에서 사용되는 알고리즘들 3가지 소개
✅선형 회귀 (Linear Regression) 수많은 점들로 이루어진 데이터의 분포에서 오차를 최소화 하는 일차식의 기울기(a)와 절편(b)을 찾는다.

✅ 의사결정 트리(Decision Tree) 마치 스무고개 처럼 데이터에 레이블(Label)을 지정하여 학습 시킨다.

✅ 서포트 백터 머신 (Support Vector Machine, SVM) 데이터 분포를 나누는 기준을 결정하는 알고리즘이다. 선형이 될수도 있고 비선형이 될수도 있다. 2개의 클래스에 속한 데이터 사이의 거리를 최대화 하면서 그 사이를 통화하는 선형 또는 비선형 함수를 식별한다.

2개의 데이터 그룹을 가장 잘 나누어주는 함수를 찾는것이고, 서포트 백터와 식별 함수사이의 공간을 마진(Margin)이라고한다.

다양한 모델로 분석이 가능하다.
💡비지도학습 (Unsupervised Learning)
데이터에 레이블(정답)을 제공하지 않고 학습시키는 방식 전체 데이터를 주어진 수의 그룹으로 분류(군집화)하는 것이 목적이다. 목적에 따라 군집(Clustering), 연관(Association)으로 구분된다.

군집(Clustering) 클러스터링은 가장 인기 있는 비지도 학습 방법 중 하나이다. 여기서 사용되는 여러 유형의 비지도 학습 알고리즘에는 배타적, 계층적 클러스터링등이 있다.
배타적 클러스터링 (Exclusive Clustering): 주어진 데이터를 k개의 클러스터로 묶는
비지도학습 알고리즘
계층적 클러스터링 (Hierarchical Clustering): 계층적 트리 모형을 이용해 개별 개체들을 순차적, 계층적으로 유사한 그룹과 통합하여 군집화를 수행하는 알고리즘
연관(Association) 특정 사건이 발생하였을 때 함께 자주 발생하는 다른 사건 규칙을 발견하는 알고리즘이다. 주로 소매점의 장바구니나 거래 데이터 세트를 분석하는 데 사용되어 특정 항목들이 얼마나 자주 함께 구매되는지를 나타낸다. 예로는 즐겨 찾는 온라인 소매점의 "함께 자주 구매한 상품"과 "이 상품을 구매한 사람들은 또한 구매한 상품" 섹션이 있다. 일반적으로 Apriori 알고리즘이 연관 규칙 학습을 위해 가장 널리 사용되어 관련 항목 또는 항목 집합을 식별한다.
배타적 클러스터링의 K-평균(K-means) 알고리즘 소개
✅K-평균(K-means)

주어진 데이터를 k개의 클러스터로 묶는 비지도학습 알고리즘이다. 데이터의 특징만으로 비슷한 데이터끼리 모아 군집화 된 클래스로 분류하는 방식이다.

데이터가 섞여있는 상황에서 중심을 정하고, 데이터를 중심부터 가까운 순으로 할당한다. K = 3으로 정의, 3개의 중심 선택한뒤 데이터를 가장 가까운 중심이 있는 군집에 할당하는 방식이다. (그림참조)

위의 예제도 마찬가지이다. 새로운 중심을 임의로 선택한 후 반복적인 실행을 통해 최적의 모델을 만들어낸다. 새로운 군집의 중심을 계산후 재정의된 중심값 기준으로 다시 거리기반의 군집 재분류한다.
K-평균 알고리즘의 활용분야로는 트랜드 또는 성향이 불분명한 시장을 분석하는 경우사용 할 수 있다. 그 예로는 시장과 고객분석, 패턴인식, 공간데이터 분석, 텍스트 마이닝 등이 있다. 패턴인식, 음성인식의 기본 알고리즘으로 활용한다. 개체가 불규칙적이고, 개체간 관련성을 정확히 알 수 없는 분류 초기 단계 분석 방법으로 많이 사용하는 알고리즘이다.
💡강화학습(Reinforcement Learning)
데이터에 레이블(정답)을 제공하지 않고 학습하는 것은 비지도학습이다. 강화학습은 여기에 더 얹어서 일련 행동의 결과에 대해 보상이 주어지는 방식이다. 현재 상태에서 보상을 많이 받는 쪽으로 행동을 취하게 학습한다. 예로는 게임 등의 규칙을 학습하는데 특히 효과적이다.
📍인공지능은 어떻게 강아지와 고양이 이미지를 분류할까?
머신러닝의 알고리즘은 주로 데이터를 기반으로 작동하기 때문에 숫자의 개념은 작동이 잘 된지만 이미지 데이터같은 경우에는 수많은 픽셀로 이루어져있기 때문에 그 많은 데이터를 분류하기엔 한계점이 있었. 특히 멀티미디어데이터와 같은 경우엔 기존의 알고리즘으로는 구현이 힘들었다. 이 한계점은 딥러닝의 등장으로 해결되었는데 자세히 알아보자

3️⃣인공신경망 (Artificial Neural Networks)
개요
인공신경망을 이해하려면 뉴런(Neuron)에 대한 이해가 필요하다. 뉴런이란 인간의 뇌를 구성하는 기본단위이다. 전기적 신호를 통해 정보를 전달하거나 처리하는 신경세포를 뜻한다. 여러가지 종류의 뉴런이 있는데 신호가 전달 될때는 신호가 수상돌기에서 들어와서 축삭말단으로 나가는 패턴이 있다. 이러한 패턴이 인간의 뇌속엔 수십억개가 있고 이것은 '정보'의 형태라고 할 수 있다. 사람은 이러한 뉴런의 동작으로 사물을 인식한다.

인간 두뇌의 생물학적 뉴런의 작용을 모방한 모델을 '인공신경망'이라고 한다. 예전에는 컴퓨터 용량 부족으로 구현이 불가능했지만 현재에는 가능해졌기 때문에 딥러닝의 발전도 가능하게 되었다.

뉴런으로부터의 입력을 일정한 함수를 거쳐 출력한다. 각 뉴런이 독립적으로 작동하는 처리기의 역할을 수행하게 된다. 실제로는 저런 패턴이 무수히 존재한다.
연결주의 인공지능의 대표적인 모델이다. 컴퓨터상의 프로그램으로 인공신경망을 만든뒤 만들어진 인공신경망을 이용해서 학습시킨다. 예) 입력 부분에 고양이 이미지 1만장, 강아지 이미지 1만장 등으로 학습
인공신경망 모델의 발전

"딥러닝 알고리즘" 이전의 알고리즘들 소개
✅퍼셉트론 알고리즘(Perceptron Algorithm) 1957년 프랭크 로젠블럿이 제안, 뉴런을 모방한 구조이다. 여러 개의 입력값 X를 받아서 처리하여 하나의 결과 값을 출력한다.

1️⃣입력값의 중요도에 따라 서로 다른 가중치(W)를 할당한다.
2️⃣입력값에 가중치를 곱해서 모두 더함
3️⃣그 값이 일정 수준(임계값)을 넘기면 1, 그렇지 않으면 0을 출력 (이진법)

선형 분류(이진 분류) 알고리즘의 특성으로 위와같은 상황에서는 퍼셉트론 알고리즘이 효과적이다.

한 직선에 의해 두 개 영역으로 분리되는 것 - AND와 OR함수는 한 직선에 의해 분리 가능하지만 XOR 문제는 퍼셉트론 알고리즘으론 해결이 불가능하다.
✅다층 퍼셉트론 (Multi-Layer Perceptron) 모델
위의 문제 해결법으로 나온 퍼셉트론 알고리즘의 상위 버전인 1980년대 중반 다층 퍼셉트론 모델이 제안되었다. 단층 퍼셉트론 모델에 하나 이상의 은닉층을 추가해서 구성된다. 이로인해 XOR문제를 해결하고 성능을 향상시켰다.

이를 통해 노드의 갯수를 컴퓨터가 해결할수 있는 최대수로 늘렸을 경우 성능이 높아진 다는 걸 알게된 후 본격적인 실험에 들어왔다. 이 와중에 인공 신경망의 깊이가 깊어질수록원하는 결과를 얻을 수 없는 경우가 발생하기 시작했다. 아래와 같은 문제점이 있었다.
❶ 지역최소점(local Maxima) 문제: 특정 지점을 최적이라고 판단하여 더 이상 학습을 진행하지 않는 점
❷ 인공신경망이 복잡해질수록 학습 시간이 매우 오래 걸렸다
❸ 가중치 최적화 결과를 설명하기 어려웠다.
이로인해 갈수록 성능이 더 떨어졌다. 90년대 후반부터 두 번째 인공지능 침체기를 맞게된다.
✅심층신경망(Deep Neural Network) 모델
여러 개의 은닉층을 가진 인공신경망 계열 모델이다. 기존 인공신경망에서 은닉층의 개수를 늘려 좀 더 정교한 학습이 가능한 원리이다. 다층 퍼셉트론 모델에서 겪던 지역최소점 문제와 컴퓨팅문제를 돌아보면, 컴퓨팅문제는 컴퓨터의 발전으로 자연스럽게 해결되었다. 그리고 지역최소점문제도 이 심층신경망 모델에서 해결되었다.


2006년 인공지능의 처음 개척을 한 분으로 인식되고있는 제프리 힌튼 교수사진이다.
가중치의 초기값을 제대로 설정하면, 심층 신경망 학습도 가능하다고 하였다. 예전 방식으로는 초기값을 랜덤으로 지정해서 반복학습하는 시스템이었다. local Maxima의 해결책으로 심층신경망을 학습시키기 전에 적은 층으로 사전학습을 진행하여 이로 얻어진 초기값으로 전체 심층신경망에 적용해서 본 학습 진행하는 두개의 단계로 나누어 진행하였다. 결과는 성공이었다. 이것이 바로 딥러닝 알고리즘이다.
4️⃣딥러닝 (Deep Learning)

딥러닝 알고리즘은 머신러닝의 한 분야로 위에 언급된 심층신경망(Deep Neural Network) 모델을 기반으로 학습하는 방법이다. 이미지, 음성, 영상 등의 패턴 인식에 좋은 성과를 보여준다.
딥러닝의 성장배경
은닉층의 개수를 늘려 정교한 학습이 가능해졌다. 왜냐하면 CPU와 GPU의 성능이 월등히 빨라졌고, 값도 저렴해서 대규모 서버 네트워크 구성이 가능해졌기 때문이다. 인터넷의 발달로 학습에 사용하는 데이터를 쉽게 확보할 수 있다는 점도 딥러닝의 성장배경으로 꼽힌다. 강의 처음 부분에서 언급되었던 인공지능 발전의 핵심요소인 데이터, 알고리즘, 컴퓨팅 파워와 동일하다.
2012년 구글의 딥러닝 프로젝트(Google Deep learning project, 2012)
앤드류 응(Andrew Ng, 스탠포드대학) + 구글의 딥러닝 프로젝트
유튜브 1,000만 개 동영상 중 고양이 영상 추출 성공하였다. 16,000개 컴퓨터 프로세서와 10억 개 이상으로 구성된 심층신경망을 이용하여 얻어낸 성과였다.
2012년 이미지넷 챌린지(ImageNet challenge, 2012)
이미지 인식 기술 향상을 위해 매년 개최되는 대회이다. 2011년까지 인식률이 75%에 머물렀지만 2012년 제프리 힌튼 교수의 알렉스넷(Alex Net)은 84.7%를 기록했다.

대표적인 딥러닝 알고리즘들 3가지 소개
(Three Representative Deep Learning Algorithms)

✅ 전통적인 CNN (Deep Neural Networks) 여러 개의 은닉층을 가진 인공신경망 계열 모델 CNN은 다층 퍼셉트론의 한계를 극복한 구조이다. 컴퓨팅문제와 지역 최소점 문제를 해결하였다.
✅합성곱 신경망 CNN (Convolutional Neural Networks) 동물의 시신경 구조를 모방하였다. 뉴런 사이의 연결 패턴을 형성하는 모델이다. 이미지, 음성, 영상 인식 등 컴퓨터 비전에 적합하다. 예를 들면 자율주행, 얼굴인식, 의료영상, 음성인식, 합성 데이터 생성등이 응용 분야에 속한다.

- 쉽게 설명하면 멀리있는 물체를 인식할 때 거리가 가까워지면서 정확히 인식을 하게된다. 이렇듯 합성곱 신경망은 초기의 아웃라인을 세팅 후에 더 깊은 학습을 통해 결과를 도출하는 과정을 거친다.


- 윤곽데이터만 사용하여 윤곽을 추출한다.


- Fully Connected Layer를 이용해 최종 결과를 출력한다.
딥러닝에선 Convolutional Neural Networks를 대표적으로 꼽는다. 요약하자면 데이터가 워낙 크기 때문에 그것의 특징 (윤곽 등)을 추출하여 네트워크로 만들어준다고 이해하면 쉽다.
✅ 순환신경망 RNN (Recurrent Neural Networks) 여러 개의 데이터가 순서대로 입력되었을 때 CNN은 이미지 그대로 사용한다. 하지만 RNN은 앞서 학습된 받은 데이터를 기억하고 있다가 학습에 활용하는 방법이다. 주로 순차데이터를 대상으로 학습한다.

기후가 갑자기 변할수도 있지만 대부분의 경우 1시간뒤의 온도는 비슷하다
문맥상으로 새가 어디에 있는지 판단이 가능하다.
위에 언급된 예제를 판단하는 것이 RNN이다. 텍스트 분석과 자연어 처리에 효과적이다. 구체적인 알고리즘 방식은 이번시간엔 생략한다.

위의 사진을 보고 컴퓨터가 설명해주는 기능을 RNN을 이용한 것이다.
이렇듯 이미지 캡션 생성, 시계열 데이터 예측 자동 번역, 음악 작사 및 작곡, 감성 분석등에서 RNN이 활용가능하다. 시퀀스와 맥락을 고려하는 상황에 적합하다.
머신러닝과 딥러닝 비교

숫자와 관련된 정형데이터, 작은 데이터 집합에 활용가능하다. 비지니스, 상품, 매출 데이터 분석에서 머신러닝 기법을 많이 활용한다.
딥러닝은 주로 멀티미디어이미지, 사운드, 동영상 등의 데이터에 활용시 더 좋은 결과를 얻을 수 있다. 일반 PC에서는 수행이 어렵고 서버급PC에서 수행을 해야한다. 특히 GPU 연산을 많이 필요로 한다.
처리시간이란 학습하는데 소요되는 시간을 의미한다.

학습정리(Summary)







