Git Basics: Version Control, Configuration, and Commits

소프트웨어 버전과 버전 관리 (Software Version & Version Control)
소프트웨어에서 버전(Version) 은 특정 소프트웨어나 코드의 상태를 구분하기 위해 붙이는 식별자(Identifier) 이다. 우리가 스마트폰 앱이나 운영체제를 업데이트할 때 “현재 버전”, “최신 버전”, “업데이트 버전”이라는 표현을 자주 접하는데, 이때의 버전은 단순한 숫자가 아니라 해당 소프트웨어가 어느 시점의 상태인지 알려주는 기준이 된다.
예를 들어 어떤 프로그램에 문제가 생겨 고객센터에 문의하면, 보통 “어떤 버전을 사용하고 있나요?”라는 질문을 받는다. 이는 같은 프로그램이라도 버전에 따라 기능, 오류, 동작 방식이 다를 수 있기 때문이다. 따라서 버전은 소프트웨어를 구분하고 문제를 추적하기 위한 중요한 정보가 된다.
버전을 이해하기 위해 먼저 식별자(Identifier) 의 개념을 볼 필요가 있다. 식별자는 어떤 대상을 다른 대상과 구분하기 위해 붙이는 이름이나 번호를 말한다. 사람에게는 이름이나 학번, 사물에는 제품 번호나 모델명 등이 식별자가 될 수 있다. 이름만으로도 대상을 구분할 수 있지만, 번호를 사용하면 더 정확하고 세부적으로 구분할 수 있다. 그래서 소프트웨어 버전에서는 보통 숫자를 많이 사용한다. 숫자는 순서를 나타내기 쉽고, 변경 이력을 관리하기에도 편리하기 때문이다.
코드를 작성할 때도 버전의 개념이 필요하다. 아주 짧고 단순한 코드는 수정하거나 변경할 일이 거의 없을 수도 있다. 하지만 실제 소프트웨어 개발에서는 코드가 계속 수정되고 확장된다. 기능이 추가되거나 오류가 고쳐지고, 구조가 바뀌는 일이 반복된다. 이때 변경된 코드들을 모두 같은 것으로 볼 것인지, 아니면 서로 다른 상태로 구분할 것인지가 중요해진다.
컴퓨터 입장에서는 줄바꿈이나 빈칸 같은 변화가 실행 결과에 영향을 주지 않을 수도 있다. 예를 들어 일부 프로그래밍 언어에서는 공백이나 줄바꿈이 프로그램의 동작에 큰 영향을 주지 않는다. 하지만 사람 입장에서는 코드의 가독성, 구조, 이해도에 큰 차이를 만들 수 있다. 따라서 어떤 변경을 버전으로 구분할 것인지, 어떤 변경은 단순한 편집으로 볼 것인지도 버전 관리에서 생각해야 할 부분이다.
버전이라는 개념은 디지털 시대에만 생긴 것은 아니다. 컴퓨터가 널리 사용되기 전에도 문서, 서류, 설계도, 계약서 등은 종이 형태로 관리되었다. 같은 문서라도 작성 날짜가 다르거나 서식이 바뀌거나 내용이 수정되면 서로 다른 문서로 구분해야 했다. 이때도 “완전히 다른 문서로 볼 것인가?”, “같은 문서의 수정본으로 볼 것인가?”와 같은 판단이 필요했다. 이러한 개념이 소프트웨어 개발에서도 이어져, 변경된 내용을 기록하고 이전 상태와 비교하며 필요할 때 재사용할 수 있도록 발전한 것이 버전 관리(Version Control) 이다.
소프트웨어에서는 버전을 보통 숫자로 표시한다. 예를 들어 1.0, 1.1, 2.0과 같은 형태가 대표적이다. 숫자 버전은 소프트웨어의 변경 정도나 출시 순서를 표현하기 쉽다. 그러나 숫자만으로는 사람이 기억하거나 부르기 어려울 때도 있다. 그래서 소프트웨어나 프로젝트에 코드명(Code Name) 또는 프로젝트명(Project Name) 을 붙이기도 한다.
예를 들어 어떤 소프트웨어의 공식 버전은 숫자로 관리하되, 개발 과정이나 출시 단계에서는 사람이 부르기 쉬운 이름을 함께 사용할 수 있다. 숫자 버전은 정확한 식별에 유리하고, 코드명이나 프로젝트명은 의사소통과 기억에 유리하다. 즉, 버전 번호와 코드명은 서로 다른 목적을 가진다. 버전 번호는 정확한 구분을 위한 것이고, 코드명은 사람이 쉽게 이해하고 부르기 위한 이름에 가깝다.
결국 소프트웨어 버전은 단순히 숫자를 붙이는 작업이 아니라, 소프트웨어의 변화 과정을 기록하고 구분하는 체계이다. 어떤 기능이 추가되었는지, 어떤 오류가 수정되었는지, 어떤 시점의 코드가 사용되었는지를 알기 위해 버전이 필요하다. 이러한 버전 정보가 체계적으로 관리되어야 여러 사람이 함께 개발할 때 혼란을 줄이고, 문제가 발생했을 때 원인을 추적할 수 있다.
따라서 버전 관리(Version Control) 는 소프트웨어 개발에서 매우 중요한 개념이다. 버전 관리를 통해 개발자는 변경 이력을 남기고, 이전 상태로 되돌아가거나, 여러 개발자가 동시에 작업한 내용을 비교하고 통합할 수 있다. 소프트웨어가 계속 변화하는 대상이라는 점에서, 버전은 그 변화를 기록하고 관리하기 위한 기본 단위라고 할 수 있다.

버전 표기 방식 (Version Numbering)
소프트웨어의 버전 표기 방식(Version Numbering) 은 소프트웨어의 변경 정도를 쉽게 구분하기 위해 사용된다. 기본적으로는 숫자를 사용하며, 숫자를 어떻게 배치하느냐에 따라 소프트웨어가 얼마나 크게 바뀌었는지, 어떤 성격의 변경이 있었는지를 파악할 수 있다.
대표적인 방식으로 시맨틱 버저닝(Semantic Versioning, SemVer) 이 있다. 시맨틱 버저닝은 보통 MAJOR.MINOR.PATCH 형식으로 버전을 표기한다. 예를 들어 2.1.3이라는 버전이 있다면, 2는 메이저 버전(Major Version), 1은 마이너 버전(Minor Version), 3은 패치 버전(Patch Version) 을 의미한다.
메이저 버전(Major Version) 은 기존 버전과 호환되지 않을 정도로 큰 변화가 있을 때 증가한다. 예를 들어 기존에 사용하던 API(Application Programming Interface) 가 크게 바뀌어 이전 방식으로는 더 이상 정상적으로 사용할 수 없다면 메이저 버전이 올라간다.
마이너 버전(Minor Version) 은 기존 버전과 호환성을 유지하면서 새로운 기능이 추가되었을 때 증가한다. 즉, 기존 사용자는 큰 문제 없이 계속 사용할 수 있지만, 새로운 기능이 더해진 경우이다.
패치 버전(Patch Version) 은 기존 버전과 호환성을 유지하면서 버그를 수정했을 때 증가한다. 새로운 기능을 추가하기보다는 오류를 고치거나 안정성을 개선하는 변경에 해당한다.
따라서 MAJOR.MINOR.PATCH 형식의 번호만 보아도 소프트웨어가 완전히 크게 바뀐 것인지, 기능이 조금 추가된 것인지, 단순히 오류가 수정된 것인지 어느 정도 파악할 수 있다. 예를 들어 1.2.3에서 1.2.4로 바뀌었다면 보통 작은 버그 수정으로 이해할 수 있고, 1.2.3에서 2.0.0으로 바뀌었다면 기존과 호환되지 않는 큰 변화가 있었을 가능성이 높다.
하지만 모든 소프트웨어가 반드시 이 규칙을 따르는 것은 아니다. 시맨틱 버저닝은 널리 사용되는 규칙이지만, 프로젝트의 성격이나 개발 문화에 따라 버전 번호를 다르게 정하는 경우도 많다. 어떤 프로젝트는 날짜를 버전으로 사용하기도 하고, 어떤 프로젝트는 내부 기준에 따라 메이저 번호를 올리기도 한다.
숫자 뒤에는 문자나 단어가 추가되기도 한다. 대표적으로 알파(Alpha), 베타(Beta), 릴리스 후보(Release Candidate, RC) 가 있다. 시맨틱 버저닝에서는 정식 릴리스 전 버전을 1.0.0-alpha, 1.0.0-beta, 1.0.0-rc.1과 같은 방식으로 표기할 수 있다. 이러한 표기는 아직 최종 배포 전 단계라는 의미를 가진다.
알파 버전(Alpha Version) 은 개발 초기 테스트 단계에 가깝다. 프로그램의 주요 기능이 어느 정도 만들어졌더라도 아직 안정성이 부족할 수 있고, 개발자나 내부 테스트 인원이 문제를 찾는 단계라고 볼 수 있다.
베타 버전(Beta Version) 은 알파보다 더 완성도 있는 테스트 단계이다. 기능이 어느 정도 마무리된 상태에서 실제 사용자 환경에 가깝게 테스트하는 경우가 많다. 프로젝트에 따라 일반 사용자에게 공개되기도 하고, 제한된 사용자에게만 제공되기도 한다.
릴리스 후보(Release Candidate, RC) 는 정식 배포 직전 단계의 버전이다. 큰 문제가 발견되지 않으면 이 버전이 최종 릴리스로 이어질 수 있다. 즉, “이 정도면 배포해도 될 것 같다”라고 판단되는 후보 버전이라고 이해할 수 있다.
다만 알파, 베타, 릴리스 후보의 의미도 프로젝트마다 조금씩 다를 수 있다. 어떤 프로젝트에서는 베타 단계에서도 기능이 추가될 수 있고, 어떤 프로젝트에서는 베타 이후부터는 새 기능을 넣지 않고 버그 수정만 진행하기도 한다. 따라서 이러한 용어는 일반적인 흐름을 이해하는 기준으로 보면 된다.
리눅스 커널(Linux Kernel) 도 버전 번호를 사용하지만, 현재의 리눅스 커널 버전 방식은 시맨틱 버저닝을 엄격하게 따르는 방식이라고 보기는 어렵다. 과거 리눅스 커널은 버전 번호에서 안정 버전과 개발 버전을 구분하는 규칙을 사용한 적이 있다. 예를 들어 2.x 시기에는 짝수 마이너 버전을 안정 버전, 홀수 마이너 버전을 개발 버전으로 구분하는 방식이 사용되었다. 그러나 2.6 커널 이후에는 이러한 방식이 더 이상 사용되지 않게 되었다.
최근의 리눅스 커널에서는 메이저 버전이 올라간다고 해서 반드시 API가 크게 깨지거나, 엄청난 기능 변화가 있었다는 뜻은 아니다. 리누스 토르발스(Linus Torvalds)는 리눅스 커널의 큰 버전 번호 변경이 기능 기반이나 안정/불안정 구분을 의미하지 않으며, 큰 숫자를 피하기 위한 성격도 있다고 설명한 바 있다. 따라서 리눅스 커널의 버전 번호는 시맨틱 버저닝의 MAJOR.MINOR.PATCH 의미와 그대로 대응시키기보다는, 리눅스 커널 프로젝트 고유의 릴리스 흐름으로 이해하는 것이 더 정확하다.
결국 버전 표기 방식은 소프트웨어의 변경 이력을 간단하고 명확하게 전달하기 위한 약속이다. 시맨틱 버저닝(Semantic Versioning) 은 그중 가장 널리 알려진 방식이지만, 모든 프로젝트가 반드시 같은 방식으로 버전을 관리하는 것은 아니다. 따라서 버전 번호를 볼 때는 숫자의 형식뿐만 아니라, 해당 프로젝트가 어떤 버전 정책을 사용하는지도 함께 확인해야 한다.

리눅스 라이브러리 버전 표기 방식 (Linux Library Versioning)
소프트웨어 버전 표기 방식에는 앞서 살펴본 시맨틱 버저닝(Semantic Versioning) 외에도 여러 방식이 존재한다. 특히 리눅스/유닉스 계열에서 사용되는 공유 라이브러리(Shared Library) 의 버전 표기에는 일반적인 MAJOR.MINOR.PATCH 방식과 다른 기준이 사용되기도 한다.
그 예로 Libtool 버전 정보(Libtool Version Info) 에서 사용하는 current:revision:age 형식이 있다. 여기서 current, revision, age는 단순히 “큰 변경, 작은 변경, 버그 수정”을 의미하는 것이 아니라, 라이브러리의 인터페이스(Interface) 와 호환성(Compatibility) 을 기준으로 해석된다. GNU Libtool 문서에 따르면 current는 해당 라이브러리가 구현하는 가장 최신 인터페이스 번호이고, revision은 현재 인터페이스의 구현 번호이며, age는 최신 인터페이스와 가장 오래된 호환 인터페이스 사이의 차이를 의미한다.
이 방식은 특히 라이브러리의 ABI(Application Binary Interface) 호환성을 관리하기 위해 사용된다. 프로그램이 어떤 공유 라이브러리를 사용할 때, 단순히 기능이 추가되었는지만 중요한 것이 아니라 기존 프로그램이 새 라이브러리와 함께 실행되어도 문제가 없는지가 중요하다. 그래서 current:revision:age 방식은 라이브러리가 어떤 인터페이스 범위까지 호환되는지를 표현하기 위한 목적을 가진다.
예를 들어 current는 라이브러리가 제공하는 최신 인터페이스 번호를 나타내고, age는 그 라이브러리가 과거의 몇 단계 인터페이스까지 호환되는지를 나타낸다. 따라서 current - age부터 current까지의 인터페이스를 지원한다고 볼 수 있다. 만약 current와 age가 같은 두 라이브러리가 있다면, 동적 링커(Dynamic Linker)는 보통 더 높은 revision 값을 가진 라이브러리를 선택한다.
이 점에서 current:revision:age는 시맨틱 버저닝(Semantic Versioning) 과 구분된다. 시맨틱 버저닝의 MAJOR.MINOR.PATCH는 일반적으로 API 변경 정도를 사람이 이해하기 쉽게 표현하는 방식이다. 반면 current:revision:age는 라이브러리 인터페이스와 바이너리 호환성을 관리하기 위한 도구적 성격이 강하다. 즉, 숫자가 세 부분으로 나뉘어 있다는 점은 비슷하지만, 각 숫자가 의미하는 바는 서로 다르다.
또한 이 방식은 보통 사람이 직접 보는 제품 버전이라기보다는, 빌드 도구나 운영체제의 라이브러리 로딩 과정에서 의미를 가지는 경우가 많다. Libtool 은 current:revision:age 정보를 바탕으로 각 플랫폼에 맞는 공유 라이브러리 버전 이름을 생성한다. 따라서 이 숫자들을 일반적인 소프트웨어 출시 버전처럼 해석하면 혼동이 생길 수 있다.
최근에는 모든 프로젝트가 이러한 기준을 엄격하게 따르지는 않는다. 소프트웨어 규모가 커지고 개발 주기가 빨라지면서, 버전 번호를 어떤 기준으로 올릴 것인지가 프로젝트마다 달라졌기 때문이다. 실제로 Libtool 문서에서도 버전 정보를 너무 자주 갱신하면 current 인터페이스 번호가 빠르게 커질 수 있으므로, 공개 릴리스 직전에만 업데이트하라고 설명한다.
예전에는 버전 번호가 한 자리나 두 자리 수준인 경우가 많아 비교적 단순하게 느껴졌지만, 시간이 지나면서 .20, .30을 넘어 .110, .111처럼 세 자리 숫자가 등장하는 경우도 생겼다. 이렇게 숫자가 커지면 사용자가 버전 번호만 보고 변경 의미를 직관적으로 파악하기 어려워질 수 있다. 그래서 어떤 프로젝트는 시맨틱 버저닝을 따르고, 어떤 프로젝트는 날짜 기반 버전(Date-based Versioning)을 사용하며, 또 어떤 프로젝트는 자체적인 릴리스 정책에 따라 버전을 붙인다.
결국 버전 표기 방식은 하나의 고정된 정답이 아니라, 프로젝트의 목적과 관리 방식에 따라 선택되는 약속이다. 시맨틱 버저닝(Semantic Versioning) 은 사람이 변경 정도를 이해하기 쉽게 만드는 데 유용하고, Libtool의 current:revision:age 방식 은 리눅스/유닉스 계열 공유 라이브러리의 인터페이스와 바이너리 호환성을 관리하는 데 유용하다. 따라서 버전 번호를 볼 때는 숫자의 형식만 보고 판단하기보다, 해당 프로젝트가 어떤 버전 정책을 사용하는지 함께 확인해야 한다.

버전 관리와 소프트웨어 개발의 핵심 도구 (Version Control & Core Tool for Software Development)
소프트웨어 개발에서 버전(Version) 을 숫자로 표기하는 것도 중요하지만, 실제 개발 과정에서는 그 버전을 어떻게 기록하고 관리할 것인지가 더 중요하다. 단순히 1.0, 2.1.3과 같은 숫자를 붙이는 것만으로는 충분하지 않다. 누가 그 버전을 결정했는지, 어떤 파일들이 그 버전에 포함되는지, 이전 버전과 무엇이 달라졌는지를 함께 관리해야 하기 때문이다.
초기에는 별도의 버전 관리 도구(Version Control Tool) 없이 파일 안에 직접 버전 정보를 적는 방식이 사용되었다. 예를 들어 코드 파일의 주석(Comment)에 “이 파일은 1.0 버전이다”, “현재 버전은 2.1.3이다”와 같은 내용을 남기는 식이었다. 파일 수가 적고 개발자가 한 명이거나 소규모인 경우에는 이런 방식도 어느 정도 효과가 있었다. 이는 종이 문서를 관리하던 방식과 비슷하다. 종이 문서에서도 작성일, 수정일, 문서 번호, 개정 번호 등을 표시하여 어떤 문서가 최신인지 구분했는데, 이러한 관리 방식이 초기 소프트웨어 개발에도 이어진 것이다.
하지만 소프트웨어의 규모가 커지면서 상황이 달라졌다. 코드 파일이 10개, 100개, 1000개로 늘어나고, 여러 개발자가 동시에 프로젝트에 참여하게 되면서 단순히 파일 안에 주석으로 버전 정보를 적는 방식은 한계가 생겼다. 어떤 파일이 언제 수정되었는지, 누가 수정했는지, 어떤 이유로 바뀌었는지, 이전 상태로 되돌릴 수 있는지 등을 사람이 직접 관리하기 어려워졌기 때문이다.
이러한 문제를 해결하기 위해 등장한 것이 버전 관리 시스템(Version Control System, VCS) 이다. 버전 관리 시스템은 프로젝트의 변경 이력을 추적하고, 파일의 상태를 관리하며, 여러 개발자가 협업할 수 있도록 도와주는 소프트웨어 개발의 핵심 도구이다.
버전 관리 시스템을 사용하면 개발자는 코드의 변경 내용을 기록할 수 있다. 어떤 파일이 수정되었는지, 어떤 줄이 추가되거나 삭제되었는지, 누가 언제 변경했는지 확인할 수 있다. 또한 문제가 발생했을 때 이전 상태로 되돌아가거나, 특정 시점의 코드를 다시 확인할 수도 있다. 이러한 기능은 개인 개발뿐만 아니라 팀 개발에서도 매우 중요하다.
과거에는 소규모 팀이나 개인 프로젝트에서는 이력 추적이 크게 중요하지 않다고 생각할 수도 있었다. 하지만 현대 소프트웨어 개발 환경에서는 코드의 양이 많든 적든 버전 관리 도구를 사용하는 것이 거의 기본이 되었다. 작은 프로젝트라도 시간이 지나면 수정 내용이 누적되고, 실수로 코드를 잘못 변경할 수 있으며, 이전 상태를 확인해야 할 일이 생기기 때문이다. 따라서 오늘날에는 개인 프로젝트에서도 Git 과 같은 버전 관리 도구를 사용하는 것이 일반적이다.
대표적인 버전 관리 도구로는 Git 이 있다. Git은 현재 가장 널리 사용되는 분산 버전 관리 시스템(Distributed Version Control System) 중 하나이다. 특히 리눅스 커널(Linux Kernel) 소스 코드는 Git을 사용해 관리된다. 리눅스 커널은 매우 큰 규모의 오픈소스 프로젝트이며, 전 세계의 많은 개발자가 참여한다. 이런 프로젝트에서는 변경 이력을 정확하게 추적하고, 여러 개발자의 작업을 조율하는 것이 매우 중요하기 때문에 Git과 같은 도구가 필수적이다.
버전 관리 도구는 특히 텍스트 파일(Text File) 로 작성된 소스 코드를 관리하는 데 강점을 가진다. 소스 코드는 대부분 문자로 이루어져 있고, 줄(Line) 단위로 구성되어 있기 때문에 이전 버전과 현재 버전을 비교하기 쉽다. 예를 들어 어떤 줄이 추가되었는지, 어떤 줄이 삭제되었는지, 어떤 함수가 수정되었는지를 비교할 수 있다. 이러한 비교 결과를 차이 비교(Diff) 라고 한다.
반면 바이너리 파일(Binary File) 은 텍스트 파일처럼 줄 단위로 비교하기 어렵다. 바이너리 파일은 실행 파일, 이미지, 영상, 압축 파일, 오디오 파일처럼 사람이 직접 읽는 문자 구조가 아니라 연속된 바이트(Byte) 데이터로 구성된다. 텍스트 파일은 줄바꿈 문자(Newline Character)인 \n 또는 \r\n을 기준으로 줄을 나눌 수 있지만, 바이너리 파일에는 이런 줄 구조가 명확하지 않다.
따라서 바이너리 파일은 텍스트 소스 코드처럼 “몇 번째 줄이 바뀌었다”라고 비교하기 어렵다. 물론 Git 같은 도구도 바이너리 파일 자체를 저장하고 관리할 수는 있지만, 텍스트 파일처럼 세부 변경 내용을 보기 좋게 비교하는 데에는 한계가 있다. 예를 들어 이미지 파일이 수정되었다면 Git은 “파일이 변경되었다”는 사실은 알 수 있지만, 일반적인 텍스트 코드처럼 “어떤 줄이 추가되었다”라고 보여주기는 어렵다.
결국 버전 관리 시스템은 소프트웨어 개발에서 변경 이력을 체계적으로 관리하기 위한 도구이다. 과거에는 파일 안에 버전 정보를 직접 적는 방식도 사용되었지만, 현대 개발 환경에서는 Git과 같은 전문적인 버전 관리 도구를 사용하는 것이 표준에 가깝다. 특히 여러 사람이 협업하거나 프로젝트가 장기적으로 유지되는 경우, 버전 관리는 선택이 아니라 필수적인 개발 과정이라고 할 수 있다.

버전 관리 유형: 분산 관리와 중앙 관리 (Types of Version Control: Distributed & Centralized)
버전 관리 시스템(Version Control System, VCS) 은 프로젝트의 변경 이력을 관리하는 방식에 따라 크게 분산 버전 관리(Distributed Version Control) 와 중앙 집중식 버전 관리(Centralized Version Control) 로 나눌 수 있다. 이 구분은 우리가 일상에서 접하는 여러 시스템과도 비슷하다. 예를 들어 정부나 조직 운영 방식에서도 권한과 정보가 여러 곳에 나뉘어 있는 분산 구조(Distributed Structure) 가 있고, 한 곳에 모여 있는 중앙집중 구조(Centralized Structure) 가 있다. 버전 관리도 이와 비슷하게, 변경 이력을 어디에 저장하고 어떻게 공유하느냐에 따라 방식이 달라진다.
분산 버전 관리 (Distributed Version Control)
분산 버전 관리(Distributed Version Control) 는 말 그대로 프로젝트의 저장소가 여러 곳에 나뉘어 존재하는 방식이다. 각 개발자는 단순히 파일 일부만 내려받는 것이 아니라, 프로젝트의 변경 이력까지 포함한 거의 완전한 저장소 사본을 자신의 컴퓨터에 보관한다.
즉, 개발자 A, B, C가 같은 프로젝트를 작업한다면 각자의 컴퓨터에는 단순한 코드 파일뿐만 아니라, 과거 변경 이력과 커밋 기록까지 포함된 저장소가 존재한다. 그래서 중앙 서버에 항상 접속하지 않아도 자신의 컴퓨터에서 변경 이력을 확인하거나, 새로운 변경 내용을 기록할 수 있다.
이 방식에서는 “원본 저장소가 어디인가?”라는 질문이 생길 수 있다. 분산 방식에서는 기술적으로 각 저장소가 독립적인 이력을 가지고 있기 때문에, 반드시 하나의 원본만 존재해야 하는 것은 아니다. 다만 실제 협업에서는 보통 팀이 기준이 되는 저장소를 정한다. 예를 들어 GitHub, GitLab, Bitbucket 같은 원격 저장소(Remote Repository)를 기준 저장소로 삼고, 개발자들은 자신의 로컬 저장소(Local Repository)에서 작업한 뒤 변경 내용을 주고받는다.
대표적인 분산 버전 관리 도구로는 Git 과 Mercurial 이 있다. 특히 Git은 오늘날 가장 널리 사용되는 버전 관리 도구 중 하나이며, 리눅스 커널(Linux Kernel)을 비롯한 많은 오픈소스 프로젝트와 실무 개발 환경에서 사용된다.
분산 버전 관리의 장점은 중앙 서버에 문제가 생겨도 각 개발자의 로컬 저장소에 이력이 남아 있다는 점이다. 인터넷 연결이 없거나 중앙 서버에 접속할 수 없는 상황에서도 커밋(Commit), 로그 확인(Log), 브랜치 생성(Branch) 같은 작업을 할 수 있다. 또한 여러 저장소끼리 변경 내용을 주고받을 수 있기 때문에 유연한 협업 구조를 만들 수 있다.
하지만 분산 방식도 단점이 있다. 저장소 구조와 브랜치, 병합(Merge), 충돌 해결(Conflict Resolution) 같은 개념을 이해해야 하므로 처음 배우는 입장에서는 복잡하게 느껴질 수 있다. 또한 팀의 기준 저장소를 명확히 정하지 않으면 어떤 버전이 공식 버전인지 혼란이 생길 수 있다.
중앙 집중식 버전 관리 (Centralized Version Control)
중앙 집중식 버전 관리(Centralized Version Control) 는 프로젝트의 저장소와 변경 이력이 중앙 서버 한 곳에 모여 있는 방식이다. 개발자들은 중앙 저장소(Central Repository)에 접속하여 파일을 내려받고, 수정한 뒤 다시 중앙 저장소에 반영한다.
이 방식에서는 원본이 비교적 명확하다. 프로젝트의 공식 이력과 파일은 중앙 서버에 있고, 개발자들은 그 중앙 서버를 기준으로 작업한다. 예를 들어 개발자 A, B, C, D가 있든, 천 명이나 만 명의 개발자가 있든 모두 같은 중앙 저장소를 바라보게 된다.
대표적인 중앙 집중식 버전 관리 도구로는 SVN(Subversion) 과 Perforce 가 있다. SVN은 과거부터 많이 사용된 중앙 집중식 버전 관리 시스템이고, Perforce는 대규모 프로젝트나 게임 개발처럼 대용량 파일과 엄격한 파일 잠금(File Locking)이 필요한 환경에서 사용되는 경우가 많다.
중앙 집중식 버전 관리의 장점은 구조가 비교적 단순하다는 점이다. 원본 저장소가 중앙에 있으므로 어떤 저장소가 기준인지 명확하고, 권한 관리나 접근 제어를 중앙에서 통제하기 쉽다. 회사나 조직 입장에서는 누가 어떤 파일에 접근할 수 있는지, 어떤 변경을 반영할 수 있는지 관리하기 편리하다.
하지만 단점도 분명하다. 중앙 서버나 스토리지에 접근할 수 없으면 개발자들이 주요 작업을 진행하기 어렵다. 특히 커밋이나 최신 이력 확인처럼 중앙 저장소와 연결이 필요한 작업이 제한될 수 있다. 또한 중앙 저장소에 장애가 발생하면 전체 팀의 작업 흐름이 영향을 받을 수 있다.
중앙 집중식 버전 관리에서도 개발자 컴퓨터에 파일이 잠시 저장될 수는 있다. 하지만 이것은 보통 캐싱(Caching) 이나 작업 사본(Working Copy)에 가깝다. 프로젝트의 공식 변경 이력과 원본 저장소는 중앙 서버에 보관된다. 이 점이 분산 버전 관리와의 큰 차이이다.
공유 디스크와 버전 관리 시스템의 차이 (Shared Disk vs Version Control System)
중앙 집중식 버전 관리를 보면 NFS(Network File System) 같은 공유 디스크를 사용하는 것과 비슷해 보일 수 있다. 예를 들어 하나의 서버에 있는 디렉토리를 개발자 A와 B가 함께 사용한다면, 모두 같은 파일을 보는 구조이므로 중앙 저장소와 비슷하게 느껴질 수 있다.
하지만 공유 디스크와 버전 관리 시스템은 목적과 기능이 다르다. 공유 디스크는 기본적으로 파일을 여러 사람이 함께 접근할 수 있게 해주는 저장 공간이다. 모든 개발자가 같은 디렉토리의 파일을 열고 수정할 수 있다. 그러나 이것만으로는 변경 이력을 체계적으로 관리하기 어렵다.
반면 버전 관리 시스템(Version Control System) 은 단순히 파일을 공유하는 것을 넘어, 누가 언제 어떤 내용을 수정했는지 기록한다. 이전 버전과 현재 버전을 비교할 수 있고, 특정 시점으로 되돌아갈 수도 있으며, 여러 사람이 동시에 작업한 내용을 병합하거나 충돌을 해결할 수도 있다. 또한 커밋 메시지(Commit Message)를 통해 변경 이유를 남길 수 있고, 브랜치(Branch)를 사용해 기능 개발과 안정 버전을 분리할 수도 있다.
따라서 공유 디스크는 “같은 파일을 함께 쓰는 공간”에 가깝고, 버전 관리 시스템은 “변경 이력을 추적하고 협업을 체계적으로 관리하는 도구”에 가깝다. 겉으로 보기에는 둘 다 중앙 서버에 파일이 있다는 점에서 비슷해 보일 수 있지만, 실제 개발 관리 측면에서는 버전 관리 시스템이 훨씬 엄격하고 편리한 기능을 제공한다.
결국 분산 방식과 중앙 집중 방식은 어느 한쪽이 항상 더 좋다고 말하기 어렵다. 분산 버전 관리(Distributed Version Control) 는 각 개발자가 완전한 이력을 가지고 독립적으로 작업할 수 있다는 장점이 있고, 중앙 집중식 버전 관리(Centralized Version Control) 는 기준 저장소가 명확하고 중앙 통제가 쉽다는 장점이 있다. 프로젝트의 규모, 협업 방식, 보안 요구사항, 파일의 종류에 따라 적절한 방식을 선택하는 것이 중요하다.

버전 관리의 특징 (Features of Version Control)
버전 관리(Version Control) 는 단순히 파일을 공유하는 것에서 끝나지 않는다. 앞에서 NFS(Network File System) 같은 공유 디스크와 비교했을 때, “공유한다”는 관점에서는 비슷해 보일 수 있다. 하지만 버전 관리 시스템은 단순 공유보다 훨씬 더 엄격하고 체계적인 기준과 기능을 제공한다. 핵심은 파일을 저장하는 것뿐만 아니라, 파일의 변경 이력을 관리하고, 이전 상태로 되돌리고, 여러 사람이 함께 작업할 수 있게 해준다는 점이다.
초기에는 별도의 버전 관리 도구(Version Control Tool) 없이 매우 원시적인 방식으로 파일을 관리하기도 했다. 예를 들어 문서 파일이나 코드 파일을 수정할 때 기존 파일과 같은 이름으로 저장하면 이전 내용은 사라진다. 어제 작성한 내용과 오늘 수정한 내용의 차이를 알기 어렵고, 실수로 덮어쓰면 이전 상태로 돌아가기도 어렵다.
그래서 가장 단순한 방법으로 파일 이름을 바꾸어 저장하는 방식이 사용되었다. 예를 들어 원본 파일이 일기장.hwp라면, 수정본을 일기장1.hwp, 일기장2.hwp처럼 저장하는 식이다. 코드 파일도 마찬가지로 main.c, main_old.c, main_v2.c처럼 이름을 바꾸어 여러 개의 파일로 보관할 수 있다. 이렇게 하면 특정 기능이 이전 버전에서는 잘 작동했는데 현재 버전에서는 작동하지 않을 때, 예전 파일을 다시 열어보거나 복사해서 되돌릴 수 있다.
이 방식은 혼자 작업하거나 아주 작은 규모의 프로젝트에서는 어느 정도 사용할 수 있다. 파일 수가 적고 변경 내용이 단순하다면, 파일 이름만으로도 대략적인 버전 구분이 가능하기 때문이다. 하지만 이 방식은 곧 한계에 부딪힌다. 파일이 많아지고, 수정 횟수가 늘어나고, 여러 사람이 동시에 작업하면 어떤 파일이 최신인지, 어떤 파일이 안정적인 버전인지, 누가 무엇을 바꾸었는지 알기 어려워진다.
현업에서도 처음에는 사람 이름이나 아이디를 파일명에 붙이는 방식으로 구분할 수 있다고 생각할 수 있다. 예를 들어 main_heesu.c, main_john.c, report_final_v3.hwp처럼 저장하는 방식이다. 하지만 이런 방식은 체계적인 버전 관리라고 보기 어렵다. 파일 이름은 많아지지만, 변경 이유나 정확한 수정 내용은 알기 어렵고, 여러 사람이 수정한 내용을 하나로 합치는 것도 어렵다.
문서 프로그램의 경우에는 자체적으로 수정 이력을 저장하는 기능이 있기도 하다. 예를 들어 한글 문서나 워드 문서에서는 변경 내용 추적, 자동 저장, 이전 버전 복원 같은 기능을 제공할 수 있다. 하지만 이런 방식은 문서 내부에 수정 이력이 함께 저장되기 때문에 파일 크기가 커질 수 있다. 실제 문서 내용은 짧아도, 수정 이력과 부가 정보가 많이 쌓이면 파일 크기가 커지는 문제가 생길 수 있다. 따라서 소프트웨어 개발처럼 많은 파일과 긴 변경 이력을 다루는 환경에서는 단순 문서 이력 기능만으로는 충분하지 않다.
결국 파일 이름을 바꾸어 보관하는 방식은 기본적인 버전 구분에는 사용할 수 있지만, 실제 개발 환경에서는 한계가 크다. 혼자 작업하거나 몇 명이 간단히 작업할 때는 가능하지만, 인원이 늘어나고 코드의 양이 많아지면 관리가 어려워진다. 이때 필요한 것이 전문적인 버전 관리 시스템(Version Control System, VCS) 이다.
버전 관리 시스템이 제공하는 중요한 특징은 크게 되돌림(Rollback/Revert), 협업(Collaboration), 추적(Tracking), 파생(Branching) 으로 정리할 수 있다.
첫 번째 특징은 되돌림(Rollback/Revert) 이다. 버전 관리 시스템을 사용하면 언제든지 이전 버전의 상태로 돌아갈 수 있다. 새로운 기능을 추가하다가 문제가 생기거나, 수정한 코드가 예상과 다르게 동작할 경우 과거의 안정적인 상태를 확인하거나 복원할 수 있다. 이 기능은 실수를 줄이고, 개발자가 더 안전하게 코드를 수정할 수 있도록 도와준다.
두 번째 특징은 협업(Collaboration) 이다. 여러 개발자가 같은 프로젝트를 동시에 작업할 때, 단순히 같은 폴더를 공유하는 방식만으로는 충돌을 피하기 어렵다. 버전 관리 시스템은 각 개발자의 변경 내용을 기록하고, 서로 다른 작업 내용을 비교하고 병합할 수 있도록 도와준다. 따라서 다수의 개발자가 같은 프로젝트를 작업하더라도 변경 내용을 체계적으로 공유할 수 있다.
세 번째 특징은 추적(Tracking) 이다. 버전 관리 시스템은 언제, 누가, 무엇을, 왜 변경했는지 기록한다. 단순히 파일의 최신 상태만 저장하는 것이 아니라, 변경 이력 전체를 남긴다. 이를 통해 문제가 발생했을 때 어떤 변경이 원인이 되었는지 찾아볼 수 있고, 특정 기능이 언제 추가되었는지도 확인할 수 있다.
네 번째 특징은 파생(Branching) 이다. 버전 관리 시스템에서는 기존 코드에서 별도의 흐름을 만들어 새로운 버전을 개발할 수 있다. 이를 브랜치(Branch) 라고 한다. 예를 들어 안정적인 버전은 그대로 유지하면서, 새로운 기능을 실험하는 별도의 개발 흐름을 만들 수 있다. 이후 기능이 안정되면 다시 원래 흐름에 합칠 수 있는데, 이를 병합(Merge) 이라고 한다.
이러한 기능들은 단순히 특정 버전 관리 프로그램만의 기능이라기보다, 소프트웨어 개발에서 자연스럽게 필요해진 기능들이다. 파일 이름을 바꾸어 저장하는 방식도 작은 규모에서는 일종의 버전 관리처럼 사용할 수 있지만, 되돌림, 협업, 추적, 파생을 체계적으로 제공하지는 못한다. 그래서 현대 소프트웨어 개발에서는 Git, SVN(Subversion), Perforce 같은 버전 관리 도구를 사용하여 변경 이력을 관리한다.
결국 버전 관리의 핵심은 “파일을 여러 개 저장하는 것”이 아니라 “변경의 흐름을 관리하는 것”이다. 어떤 상태로 되돌아갈 수 있어야 하고, 누가 무엇을 바꾸었는지 알 수 있어야 하며, 여러 사람이 동시에 작업할 수 있어야 한다. 또한 필요할 때는 기존 버전에서 새로운 개발 흐름을 만들어갈 수 있어야 한다. 이러한 이유로 버전 관리는 소프트웨어 개발의 핵심 도구가 되었다.

버전 관리를 위한 처리 단계 (Version Control Workflow)
버전 관리(Version Control) 는 단순히 파일을 저장하는 것이 아니라, 원본을 보관하고, 복사본에서 작업하고, 수정 내용을 기록하며, 필요할 때 새로운 흐름으로 분기하고 다시 통합하는 과정을 포함한다. 이러한 과정을 이해하면 Git 같은 버전 관리 도구가 왜 필요한지 더 쉽게 이해할 수 있다.
가장 먼저 생각할 수 있는 것은 저장고(Repository) 이다. 저장고는 파일과 변경 이력이 보관되는 공간이다. 일반적으로 디스크(Disk)나 서버 저장소(Storage)에 위치하며, 프로젝트의 소스 코드, 문서, 설정 파일, 그리고 그동안의 변경 기록이 함께 저장된다. 단순히 현재 파일만 보관하는 것이 아니라, 누가 언제 어떤 내용을 변경했는지에 대한 이력도 함께 관리한다는 점이 중요하다. 그래서 저장고는 단순한 폴더라기보다, 프로젝트의 기록을 담고 있는 데이터베이스(Database)에 가깝다고 볼 수 있다.
다음은 복사본(Working Copy / Working Tree) 이다. 사용자는 보통 저장고의 원본 파일을 직접 수정하지 않고, 자신의 작업 공간에 복사본을 만들어 작업한다. 원본을 직접 수정하면 기존 상태가 훼손될 수 있고, 어떤 내용이 어떻게 바뀌었는지 관리하기 어렵다. 그래서 원본은 저장고에 보관해두고, 사용자는 복사본에서 파일을 수정한다. 이렇게 하면 원본과 현재 작업 중인 파일을 비교하여 어떤 차이가 생겼는지 확인할 수 있다.
예를 들어 저장고에 있는 파일을 기준으로 개발자가 자신의 컴퓨터에 복사본을 가져온 뒤 코드를 수정한다고 생각할 수 있다. 이때 수정한 내용은 아직 저장고에 반영된 것이 아니다. 단지 작업자의 복사본에서만 바뀐 상태이다. 이 단계에서는 변경 내용을 확인하고, 테스트하고, 필요한 경우 다시 수정할 수 있다.
그다음 단계는 수정본(Commit / Revision) 이다. 사용자가 작업을 완료하고 변경 내용을 저장고에 기록하면, 그 내용은 하나의 수정본이 된다. Git에서는 이 과정을 보통 커밋(Commit) 이라고 부른다. 커밋은 단순히 파일을 저장하는 것이 아니라, 특정 시점의 변경 내용을 하나의 기록으로 남기는 것이다. 이 기록에는 변경된 파일, 변경 내용, 작성자, 시간, 설명 메시지 등이 포함될 수 있다.
수정본이 저장고에 기록되면, 그 상태는 이후 작업의 새로운 기준이 될 수 있다. 즉, 이전 원본에서 출발해 새로운 변경 내용이 반영된 또 하나의 기준 상태가 만들어지는 것이다. 그래서 버전 관리는 단순히 “파일을 덮어쓰기” 하는 방식이 아니라, 변경된 상태들을 순서대로 기록하면서 프로젝트의 흐름을 만들어가는 방식이라고 할 수 있다.
이후에는 분기(Branch) 라는 개념이 등장한다. 분기는 기존의 코드 흐름에서 갈라져 나온 새로운 작업 흐름이다. 새로운 기능을 실험하거나, 기존 버전은 안정적으로 유지하면서 다른 방향의 개발을 진행하고 싶을 때 사용한다. 예를 들어 현재 안정 버전은 그대로 두고, 새로운 기능을 추가하는 별도의 브랜치를 만들 수 있다. 이 브랜치에서는 기존 원본을 기준으로 새로운 개발을 이어가지만, 원래 흐름에는 바로 영향을 주지 않는다.
분기는 “새로운 원본”처럼 생각할 수도 있다. 기존 저장고의 특정 시점을 기준으로 새로운 작업 흐름을 만들고, 그 안에서 독립적으로 수정과 테스트를 진행하기 때문이다. 만약 새로운 기능이 실패하면 해당 분기를 버릴 수도 있고, 성공하면 원래 흐름에 합칠 수도 있다. 이처럼 분기는 새로운 기능을 안전하게 점검하거나, 여러 버전을 동시에 관리하기 위한 중요한 기능이다.
마지막으로 통합(Merge / Integration) 이 있다. 통합은 수정본이나 분기된 작업 내용을 하나로 합치는 과정이다. 여러 사람이 각자 작업한 내용을 하나의 코드 흐름으로 합치거나, 새로운 기능 브랜치에서 작업한 내용을 안정 브랜치에 반영할 때 통합이 이루어진다.
예를 들어 새로운 기능을 개발하기 위해 별도의 브랜치를 만들었다고 하자. 그 기능이 충분히 테스트되고 안정적이라고 판단되면, 해당 브랜치의 변경 내용을 기존 메인 브랜치(Main Branch)에 합친다. 이 과정이 병합(Merge)이다. 통합을 통해 여러 갈래로 나뉘어 있던 변경 내용을 하나의 프로젝트 상태로 정리할 수 있다.
하지만 통합 과정이 항상 자동으로 깔끔하게 끝나는 것은 아니다. 서로 다른 작업자가 같은 파일의 같은 부분을 수정했다면 충돌(Conflict) 이 발생할 수 있다. 이 경우 버전 관리 도구는 충돌이 발생한 위치를 알려주고, 개발자가 어떤 내용을 남길지 직접 결정해야 한다. 따라서 통합은 단순히 “파일을 합치는 일”이 아니라, 여러 변경 흐름을 비교하고 조정하는 과정이라고 볼 수 있다.
정리하면, 버전 관리를 위한 기본 처리 단계는 저장고(Repository), 복사본(Working Copy), 수정본(Commit / Revision), 분기(Branch), 통합(Merge / Integration) 으로 이해할 수 있다. 저장고는 원본과 이력을 보관하는 곳이고, 복사본은 사용자가 실제로 작업하는 공간이다. 수정본은 변경 내용을 저장고에 기록한 결과이며, 분기는 새로운 작업 흐름을 만드는 과정이다. 통합은 나뉘어진 변경 내용을 다시 하나로 합치는 단계이다.
이러한 흐름 덕분에 버전 관리 시스템은 단순한 파일 저장소를 넘어서, 소프트웨어 개발의 변경 이력을 체계적으로 관리하고 협업을 가능하게 하는 핵심 도구가 된다.
📌
Repository → 프로젝트 이력 전체가 저장되는 공간Working Tree → 사용자가 실제 파일을 수정하는 공간Staging Area → 커밋하기 전에 변경 내용을 잠시 올려두는 공간Commit → 변경 내용을 하나의 기록으로 저장하는 것Branch → 독립적인 작업 흐름Merge → 브랜치의 변경 내용을 합치는 것

버전 관리 프로그램의 종류: SCCS (Types of Version Control Systems: SCCS)
버전 관리 프로그램의 종류를 살펴볼 때 가장 초기 사례 중 하나로 SCCS(Source Code Control System) 를 들 수 있다. SCCS는 Bell Labs 에서 개발된 초기 버전 관리 시스템으로 알려져 있으며, 1970년대 초반에 등장했다. 당시 컴퓨터와 소프트웨어 개발 환경은 지금처럼 대중화되지 않았지만, 이미 소스 코드의 변경 이력을 관리해야 할 필요성은 존재했다.
SCCS는 1972년 무렵 Marc Rochkind 가 Bell Labs에서 개발을 시작한 것으로 알려져 있다. 초기에는 IBM System/370 환경에서 사용되었고, 이후 UNIX 환경에서도 사용되었다. 이는 버전 관리가 최근에 생긴 개념이 아니라, 컴퓨터와 소프트웨어 개발이 본격적으로 발전하던 시기부터 이미 중요한 문제였다는 것을 보여준다.
SCCS의 목적은 소스 코드와 같은 텍스트 파일의 변경 이력을 관리하는 것이었다. 여러 버전의 파일을 따로따로 계속 복사해두는 대신, 하나의 관리 체계 안에서 파일의 여러 버전을 보관하고, 필요할 때 과거 버전을 다시 꺼내 사용할 수 있게 해주었다. IBM 문서에서도 SCCS는 하나의 파일에 여러 버전이 동시에 존재할 수 있도록 하며, 변경 사항을 추적할 수 있게 해주는 시스템으로 설명된다.
SCCS의 특징 중 하나는 각 소스 파일 안에 SCCS ID 문자열(SCCS ID String) 을 넣는 관습이다. C 언어 코드에서는 보통 sccsid라는 문자열 변수를 만들어 그 안에 파일 이름, 버전, 날짜, 작성자 또는 설명 같은 정보를 넣었다. 예를 들면 다음과 같은 형태이다.
static char sccsid[] = "@(#)example.c 1.0 2026-05-24";
이 방식은 단순한 주석(Comment)과는 조금 다르다. 주석은 컴파일 과정에서 보통 제거되기 때문에 실행 파일이나 오브젝트 파일(Object File)에 남지 않는다. 반면 sccsid처럼 문자열 변수로 작성하면, 컴파일된 결과물 안에도 해당 문자열이 포함될 수 있다. 그래서 나중에 바이너리 파일(Binary File)이나 오브젝트 파일 안에서 특정 문자열을 검색하여, 어떤 소스 파일의 어떤 버전이 사용되었는지 확인할 수 있다.
정리하면, SCCS(Source Code Control System) 는 초기 버전 관리 시스템 중 하나로, 소스 코드의 변경 이력을 관리하고 과거 버전을 다시 꺼내 사용할 수 있도록 도와주었다. 또한 sccsid 문자열을 통해 컴파일된 프로그램 안에서도 소스 파일의 버전 정보를 확인할 수 있게 했다. 이 방식은 오늘날의 Git과는 다르지만, 소프트웨어 변경 이력을 체계적으로 관리하려는 초기 시도였다는 점에서 중요한 의미를 가진다.
추가적으로 SCCS는 현대적인 Git과 비교하면 오래된 방식이지만, 버전 관리의 기본 문제를 이미 다루고 있었다는 점에서 중요하다. 즉, “어떤 파일이 언제 어떻게 바뀌었는가”, “과거 버전을 다시 가져올 수 있는가”, “컴파일된 결과물이 어떤 소스에서 만들어졌는가”라는 문제는 1970년대에도 이미 중요했다.
또한 sccsid 방식은 오늘날에도 개념적으로는 이해할 가치가 있다. 현대 소프트웨어에서도 실행 파일 안에 빌드 번호(Build Number), 커밋 해시(Commit Hash), 빌드 날짜(Build Date)를 포함시키는 경우가 있기 때문이다. 이는 문제가 발생했을 때 해당 프로그램이 정확히 어떤 소스 코드에서 만들어졌는지 추적하기 위한 목적이다.

버전 관리 프로그램의 종류: RCS (Types of Version Control Systems: RCS)
RCS(Revision Control System) 는 SCCS 이후에 등장한 초기 버전 관리 시스템 중 하나이다. RCS는 주로 텍스트 형식의 파일, 특히 소스 코드(Source Code), 문서(Documentation), 테스트 데이터(Test Data)처럼 자주 수정되는 파일의 변경 이력을 추적하고 관리하기 위해 사용되었다. GNU RCS 문서에서도 RCS는 여러 개의 파일 리비전(Revision)을 저장, 검색, 기록, 식별, 병합할 수 있는 시스템으로 설명된다.
RCS의 중요한 특징은 수정된 전체 파일을 매번 모두 저장하는 것이 아니라, 변경된 부분만 저장하는 델타 저장 방식(Delta Storage) 을 사용한다는 점이다. 여기서 델타(Delta) 는 이전 버전과 비교했을 때 달라진 부분, 즉 차이점(Difference)을 의미한다. 예를 들어 A라는 파일이 있고, 그다음 버전에서 몇 줄만 수정되었다면 파일 전체를 다시 저장하는 대신 “어떤 줄이 바뀌었는가”만 기록하는 방식이다. RCS 논문에서도 저장 공간을 절약하기 위해 연속된 리비전 사이의 차이, 즉 델타를 저장한다고 설명한다.
RCS의 또 다른 특징은 기본적으로 한 파일에 대해 한 사용자만 수정하도록 하는 잠금 방식(Locking Mechanism) 이다. 여러 사용자가 같은 파일을 동시에 수정하면 서로의 변경 내용이 충돌할 수 있다. 그래서 RCS에서는 사용자가 파일을 수정하기 전에 해당 파일을 체크아웃(Check-out)하고 잠금(Lock)을 걸어, 다른 사용자가 동시에 같은 파일을 수정하지 못하도록 관리했다. 이는 “동시에 수정 불가”라는 방식으로 이해할 수 있다.
이 방식은 당시의 개발 환경에서는 매우 자연스러운 선택이었다. 여러 사람이 같은 파일을 동시에 고치면 어느 변경을 살릴 것인지, 어떤 내용이 최신인지, 서로의 작업이 어떻게 섞여야 하는지 판단하기 어렵다. 특히 현대의 Git처럼 강력한 병합(Merge) 기능이 일반화되기 전에는, 충돌을 나중에 해결하기보다는 처음부터 동시에 수정하지 못하도록 막는 방식이 더 안전하게 느껴질 수 있었다.
물론 파일을 동시에 수정하는 것이 기술적으로 완전히 불가능한 것은 아니다. 현대의 버전 관리 시스템에서는 여러 사람이 같은 파일을 각자 수정한 뒤, 나중에 변경 내용을 비교하고 병합할 수 있다. 하지만 같은 부분을 서로 다르게 수정하면 충돌(Conflict) 이 발생한다. RCS의 잠금 방식은 이런 충돌 상황을 미리 줄이기 위해 “한 번에 한 사람만 수정”하도록 제한한 구조라고 볼 수 있다.
운영체제 관점에서 보면, 이것은 공유 자원(Shared Resource)을 여러 사용자가 동시에 접근할 때 발생할 수 있는 문제와도 연결된다. 하나의 파일을 여러 사용자가 동시에 수정하면 데이터 일관성(Data Consistency)이 깨질 수 있고, 마지막에 저장한 사람이 이전 사람의 작업을 덮어쓰는 문제가 생길 수 있다. 따라서 RCS의 잠금 방식은 공유 파일을 안전하게 관리하기 위한 초기 버전 관리 시스템의 접근법이라고 할 수 있다.
정리하면, RCS(Revision Control System) 는 텍스트 파일의 변경 이력을 관리하기 위한 초기 버전 관리 시스템이다. RCS는 전체 파일을 매번 저장하기보다 변경된 부분만 저장하는 델타 저장 방식(Delta Storage) 을 사용하여 저장 공간을 절약했다. 또한 하나의 파일에 대해 한 사용자만 수정할 수 있도록 하는 잠금 방식(Locking) 을 통해 협업 중 발생할 수 있는 충돌을 줄이려 했다. 이러한 특징은 이후 버전 관리 시스템이 발전하는 데 중요한 기반이 되었다.
RCS의 방식은 오늘날 Git과 다르게 느껴질 수 있다. Git은 보통 여러 사람이 각자의 브랜치(Branch)에서 자유롭게 수정한 뒤, 나중에 병합(Merge)하면서 충돌을 해결하는 방식에 가깝다.
반면 RCS는 파일 단위 잠금(File Locking)을 통해 애초에 동시에 수정하는 상황을 줄이려는 방식이었다. 그래서 RCS는 “충돌이 생기면 나중에 해결하자”보다는 “충돌이 생기지 않도록 먼저 잠그자”에 가까운 사고방식을 가진 버전 관리 시스템이라고 볼 수 있다.

버전 관리 프로그램의 종류: CVS (Concurrent Versions System)
CVS(Concurrent Versions System) 는 RCS 이후에 널리 사용된 버전 관리 시스템 중 하나이다. 이름에 들어 있는 Concurrent 는 “동시에 진행되는”, “병행하는”이라는 의미를 가진다. 즉, CVS는 여러 사용자가 같은 프로젝트를 함께 작업할 수 있도록 만든 버전 관리 시스템이다.
CVS는 기본적으로 서버-클라이언트 방식(Server-Client Model) 으로 동작한다. 여기서 서버(Server) 는 프로젝트의 원본 저장소(Repository)를 보관하는 중앙 공간이고, 클라이언트(Client) 는 개발자가 실제로 작업하는 개인 컴퓨터나 작업 환경을 의미한다. 개발자는 서버에 있는 프로젝트를 자신의 컴퓨터로 가져와 수정하고, 수정이 끝나면 다시 서버에 반영한다.
이 점에서 CVS는 이전의 RCS와 차이가 있다. RCS는 기본적으로 개별 파일 단위의 버전 관리에 가깝고, 하나의 파일을 한 사용자가 잠그고 수정하는 방식이 중심이었다. 반면 CVS는 여러 파일로 이루어진 프로젝트 전체를 관리하고, 여러 사용자가 동시에 작업하는 환경을 더 적극적으로 지원했다. 그래서 CVS는 초기의 중앙 집중식 협업 버전 관리 도구로 이해할 수 있다.
CVS에서도 서버에 저장된 프로젝트를 클라이언트가 가져오는 과정을 체크아웃(Check-out) 이라고 한다. 말 그대로 서버에 있는 파일들을 사용자의 작업 공간으로 “가져오는” 과정이다. 사용자는 체크아웃한 복사본(Working Copy)을 자신의 컴퓨터에서 수정한다. 이때 서버의 원본 저장소가 바로 바뀌는 것은 아니고, 클라이언트의 작업 복사본만 수정된다.
수정이 끝난 뒤에는 변경 내용을 서버에 반영해야 한다. 이 과정을 체크인(Check-in) 또는 CVS에서는 보통 커밋(Commit) 이라고 부른다. 사용자가 커밋하면, 클라이언트에서 수정한 내용이 중앙 서버의 저장소에 기록된다. 이때 서버에는 새로운 리비전(Revision)이 만들어지고, 변경 이력도 함께 남는다.
CVS는 내부적으로 RCS와 관련이 깊다. 초기 CVS는 파일별 이력 관리를 위해 RCS 파일 형식을 활용했다. 그래서 CVS도 텍스트 파일의 변경 이력을 추적하고, 어느 부분이 수정되었는지 관리할 수 있었다. 다만 RCS가 파일 하나를 중심으로 관리했다면, CVS는 여러 파일과 디렉토리로 이루어진 프로젝트를 중앙 저장소에서 함께 관리할 수 있도록 확장한 방식이라고 볼 수 있다.
강의에서 언급된 심볼릭 링크(Symbolic Link) 부분은 조심해서 이해할 필요가 있다. CVS는 일반 파일과 달리 심볼릭 링크를 완전한 파일 시스템 객체로 깔끔하게 버전 관리하는 데 한계가 있었다. 그래서 심볼릭 링크가 프로젝트 안에 있을 때, 그것을 그대로 보존하거나 추적하는 방식이 현대적인 Git과는 다르게 제한적일 수 있다. 즉, CVS는 텍스트 기반 소스 코드 관리에는 적합했지만, 파일 시스템의 다양한 속성이나 특수 파일을 완벽하게 다루는 도구는 아니었다.
CVS에서 중요한 점은 여러 사용자가 동시에 작업할 수 있다는 것이다. 예를 들어 개발자 A, B, C가 같은 프로젝트를 체크아웃해서 각자 수정할 수 있다. RCS처럼 한 파일을 반드시 한 사람만 잠그고 수정해야 하는 구조와 비교하면, CVS는 더 유연한 협업을 가능하게 했다.
하지만 여러 사람이 동시에 작업할 수 있다는 것은 충돌 가능성도 생긴다는 뜻이다. 예를 들어 세 명의 개발자가 같은 파일을 가져가서 각자 수정했다고 하자. 개발자 A가 먼저 서버에 커밋하면, 서버의 최신 버전은 A의 수정 내용이 반영된 상태가 된다. 이후 개발자 B가 자신의 수정본을 그대로 커밋하려고 하면 문제가 생길 수 있다. 왜냐하면 B가 작업을 시작했을 때의 파일 버전과 서버의 현재 최신 버전이 달라졌기 때문이다.
이때 CVS는 단순히 B의 파일로 서버의 최신 파일을 덮어쓰는 방식으로 처리하지 않는다. 서버는 보통 사용자의 작업 복사본이 최신 버전을 기준으로 하고 있는지 확인한다. 만약 서버에 이미 다른 사용자의 변경 내용이 반영되어 있다면, B는 먼저 업데이트(Update) 를 통해 서버의 최신 변경 내용을 자신의 작업 복사본에 가져와야 한다. 그 후 자신의 수정 내용과 서버의 최신 수정 내용을 합친 뒤 다시 커밋해야 한다.
만약 A, B, C가 서로 다른 부분을 수정했다면 CVS가 자동으로 병합(Merge)할 수 있는 경우도 있다. 예를 들어 A는 함수 a를 수정하고, B는 함수 b를 수정하고, C는 함수 c를 수정했다면 서로 수정 위치가 다르기 때문에 비교적 쉽게 합쳐질 수 있다. 하지만 세 사람이 같은 함수의 같은 부분을 수정했다면 충돌(Conflict) 이 발생할 수 있다. 이 경우 CVS는 충돌이 발생한 부분을 표시하고, 개발자가 직접 어떤 내용을 남길지 결정해야 한다.
따라서 “서버는 최신 버전의 수정본만 인정한다”는 표현은 “가장 마지막에 커밋한 사람의 내용만 무조건 남는다”는 뜻으로 이해하면 안 된다. 더 정확하게는, CVS는 서버의 최신 리비전을 기준으로 변경 내용을 반영하려고 하며, 사용자의 작업 복사본이 오래된 상태라면 먼저 최신 변경 내용을 가져와 병합하도록 요구한다고 이해하는 것이 좋다.
정리하면, CVS(Concurrent Versions System) 는 중앙 서버에 저장소를 두고, 여러 클라이언트가 프로젝트를 체크아웃하여 수정한 뒤 다시 커밋하는 방식의 버전 관리 시스템이다. RCS의 파일 이력 관리 개념을 확장하여 여러 사람이 하나의 프로젝트를 함께 개발할 수 있도록 만든 도구이며, 충돌을 완전히 없애지는 못하지만 업데이트, 병합, 충돌 표시 기능을 통해 협업을 가능하게 했다.
CVS는 오늘날 Git만큼 많이 사용되지는 않지만, RCS에서 SVN, Git으로 이어지는 버전 관리 시스템 발전 과정에서 중요한 위치를 가진 도구이다.

버전 관리 프로그램의 종류: Apache Subversion (SVN)
Apache Subversion(SVN) 은 CVS 이후에 등장한 대표적인 중앙 집중식 버전 관리 시스템(Centralized Version Control System) 이다. Subversion은 보통 명령어 이름을 따서 SVN 이라고도 부른다. Apache Subversion 공식 사이트에서도 SVN을 오픈소스 버전 관리 시스템이며, 기업 환경에서도 사용할 수 있는 중앙 집중식 버전 관리 도구로 설명하고 있다.
SVN은 Apache License 에 따라 배포되는 오픈소스 소프트웨어이다. 여기서 중요한 점은 오픈소스(Open Source) 라는 말이 단순히 “코드를 볼 수 있다”는 뜻만은 아니라는 것이다. 오픈소스 소프트웨어는 라이선스 조건에 따라 사용, 수정, 배포가 허용된다. 다만 어떤 조건으로 사용할 수 있는지는 라이선스마다 다르기 때문에, 실제 프로젝트나 상업적 제품에 사용할 때는 반드시 라이선스 내용을 확인해야 한다.
특히 소프트웨어를 이용해 제품을 만들거나 수익을 얻고자 한다면 라이선스(License) 를 이해하는 것이 매우 중요하다. 오픈소스라고 해서 모든 조건이 같은 것은 아니다. 어떤 라이선스는 비교적 자유롭게 상업적 사용을 허용하고, 어떤 라이선스는 수정한 소스 코드 공개나 저작권 표시 유지 같은 조건을 요구한다. 따라서 “오픈소스니까 아무렇게나 사용해도 된다”라고 생각하면 위험하다.
다만 Apache License 2.0 은 비교적 허용적인 퍼미시브 라이선스(Permissive License) 에 속한다. Apache License 2.0은 사용, 복제, 수정, 배포, 2차 저작물 작성 등을 허용하며, 특허 라이선스 조항도 포함한다. Apache License의 원문에서도 저작권 라이선스가 무상, 전 세계적, 비독점적, 영구적으로 부여된다고 설명한다.
따라서 “오픈소스는 누구나 볼 수 있지만, 돈을 벌려면 반드시 원저작자에게 허가를 받거나 돈을 지불해야 한다”라고 일반화하는 것은 정확하지 않다. 라이선스에 따라 다르다. Apache License 2.0처럼 상업적 사용을 허용하는 라이선스도 있고, GPL처럼 배포 시 소스 코드 공개 의무가 강하게 붙는 라이선스도 있다. 핵심은 오픈소스마다 조건이 다르므로, 사용 전에 해당 라이선스를 확인해야 한다는 점이다.
SVN은 기능적으로 CVS(Concurrent Versions System) 의 한계를 개선하고 강화하기 위해 만들어졌다. CVS도 중앙 서버에 저장소를 두고 여러 사용자가 작업하는 방식이었지만, 파일 이름 변경, 디렉토리 이동, 원자적 커밋(Atomic Commit) 등에서 한계가 있었다. SVN은 이러한 문제를 개선하기 위해 설계되었다. Subversion은 2000년에 CollabNet에서 시작되었고, CVS와 비슷하게 동작하면서 CVS의 버그와 부족한 기능을 보완하는 것을 목표로 만들어졌다.
SVN의 중요한 특징 중 하나는 파일 이름 변경(Rename) 이나 파일 이동(Move), 그리고 디렉토리 구조의 변경을 버전 관리 이력 안에서 다룰 수 있다는 점이다. CVS는 주로 개별 파일 단위의 이력 관리에 초점이 있었기 때문에, 파일 이름을 바꾸거나 위치를 옮겼을 때 이력을 자연스럽게 보존하는 데 어려움이 있었다. 반면 SVN은 파일뿐만 아니라 디렉토리(Directory) 자체도 버전 관리 대상으로 다룬다. 그래서 파일이나 디렉토리를 옮기거나 복사할 때도 변경 이력을 추적하기가 더 쉬워졌다.
SVN은 오늘날 Git만큼 주류로 사용되지는 않지만, 여전히 일부 조직이나 오래된 프로젝트에서는 유지보수 목적으로 사용될 수 있다. 특히 오래전에 개발된 시스템은 전체 버전 관리 도구를 Git으로 옮기는 비용이 크거나, 기존 업무 흐름이 SVN에 맞춰져 있는 경우가 있다. 이런 경우에는 치명적인 문제가 없다면 기존 틀을 유지하면서 SVN을 계속 사용하는 경우도 있다.
따라서 SVN은 “지금 새 프로젝트에서 반드시 배워야 하는 최신 도구”라기보다는, 버전 관리 시스템의 발전 과정에서 CVS의 한계를 보완한 중요한 도구로 이해하면 좋다. RCS, CVS, SVN을 거쳐 Git 같은 분산 버전 관리 시스템이 널리 사용되기 시작했으며, 이 흐름을 이해하면 오늘날 Git이 왜 강력한 도구로 자리 잡았는지도 더 잘 이해할 수 있을 것이다.
📌SVN과 CVS의 차이를 간단히 정리하면 다음과 같다.
CVS 는 파일 단위 관리 성격이 강하고, 디렉토리 이동이나 파일 이름 변경 이력 관리가 불편했다.
SVN 은 디렉토리까지 버전 관리 대상으로 다루며, 여러 파일 변경을 하나의 리비전으로 묶어 관리할 수 있다.
SVN 은 원자적 커밋(Atomic Commit)을 지원하여 여러 파일 변경이 모두 반영되거나 모두 실패하도록 처리할 수 있다.
Git 은 SVN과 달리 분산 버전 관리 시스템(Distributed Version Control System)이므로, 각 개발자가 로컬에 전체 이력을 가진 저장소를 둘 수 있다.

버전 관리 프로그램의 종류: Git
Git 은 현재 가장 대표적인 분산 버전 관리 시스템(Distributed Version Control System, DVCS) 이다. Git은 리눅스 커널(Linux Kernel)을 만든 리누스 토르발스(Linus Torvalds) 가 2005년에 만들었다. Git이 만들어진 배경에는 리눅스 커널 개발 과정에서 사용하던 기존 버전 관리 도구인 BitKeeper 와 관련된 문제가 있었다.
리눅스 커널 개발자들은 한동안 BitKeeper 라는 버전 관리 시스템을 사용했다. BitKeeper는 분산 버전 관리 기능을 가진 도구였지만, 독점 소프트웨어(Proprietary Software)였다. 이후 라이선스 문제로 리눅스 커널 개발자들이 BitKeeper를 계속 사용하기 어려워지면서, 리누스 토르발스는 리눅스 커널 개발에 적합한 새로운 버전 관리 도구를 직접 만들게 되었다. 이 도구가 바로 Git이다. GitHub Blog에서도 Git은 2005년 4월 7일 첫 커밋이 만들어졌고, 리눅스 커널 개발자들이 BitKeeper 접근 권한을 잃은 뒤 만들어졌다고 설명한다.
Git의 가장 큰 특징은 완전한 분산 관리(Distributed Management) 가 가능하다는 점이다. 중앙 집중식 버전 관리 시스템에서는 중앙 서버가 원본 저장소 역할을 하고, 개발자들은 그 서버에서 파일을 받아 작업한 뒤 다시 서버에 반영한다. 반면 Git에서는 각 개발자가 자신의 컴퓨터에 프로젝트의 전체 변경 이력을 포함한 저장소를 가질 수 있다.
즉, Git에서는 단순히 파일의 현재 상태만 복사하는 것이 아니라, 과거 커밋 이력까지 포함한 저장소 전체를 로컬에 보관한다. 그래서 중앙 서버에 접속하지 않아도 커밋(Commit)을 만들고, 로그(Log)를 확인하고, 브랜치(Branch)를 만들고, 이전 상태로 되돌아가는 작업을 할 수 있다. 중앙 서버는 협업을 위해 자주 사용되지만, Git의 구조상 반드시 하나의 중앙 서버만 원본이어야 하는 것은 아니다.
이 점에서 Git은 기존 도구의 단순한 점진적 개선이라기보다, 버전 관리 방식을 크게 바꾼 도구로 볼 수 있다. CVS나 SVN 같은 중앙 집중식 버전 관리 시스템에서는 중앙 저장소가 기준이 되는 경우가 많았다. 하지만 Git에서는 각 개발자의 저장소가 독립적인 이력을 가질 수 있고, 필요에 따라 서로 변경 내용을 주고받을 수 있다. 그래서 오픈소스 프로젝트처럼 전 세계의 개발자가 참여하는 환경에 매우 잘 맞는다.
Git은 무료 오픈소스 소프트웨어(Free and Open Source Software) 이다. Git 공식 사이트에서도 Git을 무료 오픈소스 분산 버전 관리 시스템이라고 설명한다. Git은 빠르고 효율적으로 작은 프로젝트부터 매우 큰 프로젝트까지 처리할 수 있도록 설계되었다.
Git의 또 다른 장점은 브랜치와 병합이 강력하다는 점이다. Git에서는 새로운 기능을 실험하기 위해 브랜치를 만들고, 기능이 안정되면 다시 메인 브랜치(Main Branch)에 병합할 수 있다. 이 과정이 비교적 빠르고 가볍기 때문에, 현대 개발에서는 기능별 브랜치(Feature Branch), 버그 수정 브랜치(Bugfix Branch), 릴리스 브랜치(Release Branch) 같은 방식이 널리 사용된다.
Git은 현재 개인 프로젝트, 기업 개발, 오픈소스 프로젝트에서 매우 널리 사용된다. GitHub, GitLab, Bitbucket 같은 서비스도 Git을 기반으로 협업 기능을 제공한다. 다만 Git과 GitHub는 같은 것이 아니다. Git은 버전 관리 도구이고, GitHub는 Git 저장소를 온라인에서 호스팅하고 협업할 수 있도록 도와주는 플랫폼이다.
정리하면, Git 은 리눅스 커널 개발 과정에서 필요에 의해 만들어진 대표적인 분산 버전 관리 시스템이다. 기존에 사용하던 BitKeeper의 라이선스 문제가 계기가 되었고, 리누스 토르발스가 리눅스 커널 개발에 적합한 도구로 만들었다. Git은 각 개발자가 전체 저장소 이력을 로컬에 보관할 수 있기 때문에 중앙 서버에만 의존하지 않고, 완전한 분산 방식으로 프로젝트를 관리할 수 있다. 현재는 현대 소프트웨어 개발에서 가장 널리 사용되는 버전 관리 도구라고 할 수 있다.
📌Git을 이해할 때는 다음 구분이 중요하다.
Git 은 버전 관리 프로그램이다.
GitHub 는 Git 저장소를 온라인에서 관리하고 협업할 수 있게 해주는 서비스이다.
GitLab 과 Bitbucket 도 Git 저장소 호스팅과 협업 기능을 제공하는 플랫폼이다.
즉, Git을 배운다는 것은 GitHub 사용법만 배우는 것이 아니라, 커밋(Commit), 브랜치(Branch), 병합(Merge), 충돌 해결(Conflict Resolution), 원격 저장소(Remote Repository) 같은 버전 관리 개념을 배우는 것이다.

버전 관리에서 중요한 문제 중 하나는 여러 개발자가 같은 파일을 동시에 수정할 때 발생하는 충돌이다. 같은 파일이라도 서로 다른 함수를 수정하면 병합이 가능할 수 있지만, 같은 함수나 같은 코드 영역을 수정하면 충돌이 발생할 수 있다. 잠금 방식은 충돌을 줄일 수 있지만 작업 효율을 떨어뜨릴 수 있고, 병합 방식은 협업 효율은 높지만 충돌 해결이 필요하다. 따라서 버전 관리는 안전성과 효율성 사이에서 적절한 균형을 찾는 과정이다.
버전 관리의 고려사항: 파일 동시 변경 (Version Control Consideration: Concurrent File Changes)
버전 관리를 사용할 때 중요한 고려사항 중 하나는 여러 개발자가 같은 파일을 동시에 변경하는 상황이다. 소프트웨어 개발에서는 한 파일을 한 사람만 수정하는 경우도 있지만, 실제 협업 환경에서는 여러 개발자가 같은 파일을 동시에 수정하는 일이 자주 발생한다. 이때 변경 내용이 서로 어떻게 겹치는지에 따라 문제가 없을 수도 있고, 충돌이 발생할 수도 있다.
컴퓨터 시스템에서 여러 사용자가 같은 자원에 동시에 접근하는 것은 항상 조심해야 할 문제이다. 운영체제에서 여러 프로세스가 같은 데이터에 동시에 접근하면 동기화(Synchronization) 문제나 경쟁 상태(Race Condition) 가 발생할 수 있는 것처럼, 버전 관리에서도 여러 개발자가 같은 파일을 동시에 수정하면 변경 내용이 서로 충돌할 수 있다.
가장 단순한 해결 방법은 잠금(Lock) 을 사용하는 것이다. 한 개발자가 특정 파일을 수정하는 동안 다른 개발자가 그 파일을 수정하지 못하게 막는 방식이다. 이 방식은 충돌을 예방하는 데 효과적이다. 예를 들어 개발자 A가 main.c 파일을 잠그고 수정하고 있다면, 개발자 B는 A가 작업을 끝내기 전까지 같은 파일을 수정할 수 없다. 이렇게 하면 두 사람이 같은 파일을 동시에 수정해서 생기는 충돌을 줄일 수 있다.
하지만 잠금 방식에는 단점도 있다. 파일 전체를 잠그면 다른 개발자의 작업이 불필요하게 막힐 수 있다. 예를 들어 개발자 A는 같은 파일 안의 함수 login()을 수정하고 있고, 개발자 B는 전혀 다른 함수인 logout()을 수정하려고 할 수 있다. 두 작업은 서로 직접적인 충돌이 없을 수도 있지만, 파일 전체가 잠겨 있으면 B는 작업을 진행할 수 없다. 이 경우 협업 효율이 떨어진다.
그래서 현대 버전 관리 시스템에서는 단순히 파일 전체를 잠그는 방식만 사용하지 않고, 변경 내용을 비교하고 병합하는 방식을 많이 사용한다. 여러 개발자가 같은 파일을 수정하더라도 서로 다른 부분을 수정했다면 자동으로 합칠 수 있다. 예를 들어 개발자 A가 파일의 위쪽 함수를 수정하고, 개발자 B가 아래쪽 함수를 수정했다면 버전 관리 시스템은 두 변경 내용을 비교하여 하나의 파일로 병합할 수 있다.
반면 같은 파일 안에서도 같은 함수, 같은 줄, 같은 코드 블록을 서로 다르게 수정하면 충돌(Conflict) 이 발생할 가능성이 높다. 예를 들어 개발자 A와 B가 모두 calculateTotal() 함수의 같은 부분을 수정했다면, 버전 관리 시스템은 어떤 변경 내용을 최종적으로 남겨야 할지 자동으로 판단하기 어렵다. 이 경우 개발자가 직접 충돌 부분을 확인하고, 어떤 코드를 남길지 결정해야 한다.
따라서 버전 관리에서 중요한 것은 “같은 파일을 수정했는가”만이 아니라, “같은 파일의 어느 부분을 수정했는가”이다. 같은 파일이라도 서로 다른 함수나 서로 다른 위치를 수정했다면 병합이 가능할 수 있다. 하지만 같은 함수나 같은 코드 영역을 수정했다면 충돌이 발생할 수 있다.
이 문제는 협업 방식과도 연결된다. 파일을 어떻게 나누어 설계하느냐, 함수와 모듈을 얼마나 명확하게 분리하느냐, 누가 어떤 영역을 담당하느냐에 따라 충돌 가능성이 달라진다. 하나의 거대한 파일에 모든 기능이 들어 있다면 여러 개발자가 같은 파일을 자주 수정하게 되고, 충돌 가능성도 높아진다. 반대로 기능별로 파일과 모듈이 잘 나뉘어 있다면 각 개발자가 독립적으로 작업할 수 있어 충돌이 줄어든다.
결국 버전 관리에서 파일 동시 변경은 단순한 도구 문제가 아니라 개발 구조와 협업 방식의 문제이기도 하다. 잠금(Lock) 을 사용하면 안전성은 높아질 수 있지만 작업 효율은 떨어질 수 있고, 병합(Merge) 중심으로 관리하면 효율은 높아지지만 충돌을 해결해야 하는 부담이 생길 수 있다. 따라서 프로젝트의 성격, 파일의 종류, 팀의 작업 방식에 따라 적절한 관리 방법을 선택해야 한다.
특히 텍스트 기반 소스 코드에서는 병합 방식이 자주 사용되지만, 이미지, 영상, 실행 파일, 디자인 파일 같은 바이너리 파일(Binary File) 은 줄 단위 비교와 병합이 어렵기 때문에 잠금 방식이 더 적합할 수 있다. 예를 들어 게임 개발에서 3D 모델 파일이나 큰 이미지 파일을 여러 사람이 동시에 수정하면 자동 병합이 어렵기 때문에, 파일 잠금을 통해 한 번에 한 사람만 수정하도록 관리하는 경우가 있다.
정리하면, 버전 관리에서 파일 동시 변경을 고려할 때는 다음 두 가지 상황을 구분해야 한다. 여러 개발자가 같은 파일의 서로 다른 함수를 수정하는 경우에는 자동 병합이 가능할 수 있다. 하지만 여러 개발자가 같은 함수나 같은 코드 영역을 수정하는 경우에는 충돌이 발생할 가능성이 높다. 그래서 버전 관리는 단순히 파일을 저장하는 도구가 아니라, 협업 과정에서 변경 내용을 안전하고 효율적으로 관리하기 위한 체계라고 할 수 있다.

버전 관리에서 충돌은 같은 파일에서만 발생하는 것이 아니다. 서로 다른 파일을 수정했더라도 두 파일이 서로 의존하고 있다면 문제가 생길 수 있다. 예를 들어 한 파일에서 함수의 이름이나 매개변수를 바꾸면, 그 함수를 사용하는 다른 파일도 함께 수정되어야 한다. 따라서 버전 관리에서는 파일의 위치나 이름뿐만 아니라 파일 간 의존성도 함께 고려해야 한다.
버전 관리의 고려사항: 파일 간 의존성 (Version Control Consideration: File Dependency)
버전 관리에서 고려해야 할 또 다른 문제는 파일 간 의존성(File Dependency) 이다. 앞에서 살펴본 문제는 여러 개발자가 같은 파일(Same File) 을 수정할 때 발생하는 상황이었다. 이때 핵심은 같은 파일 안에서 같은 부분을 수정했는지, 아니면 서로 다른 부분을 수정했는지였다.
이번에 다루는 문제는 조금 다르다. 여기서는 개발자들이 서로 다른 파일(Different Files) 을 수정하고 있다. 겉으로 보면 같은 파일을 수정하는 것이 아니기 때문에 충돌이 없을 것처럼 보인다. 하지만 실제 소프트웨어 개발에서는 파일들이 서로 독립적으로 존재하지 않는 경우가 많다. 하나의 파일이 다른 파일을 참조하거나, 한 파일의 변경이 다른 파일의 동작에 영향을 줄 수 있다. 이것이 의존성(Dependency) 문제이다.
예를 들어 개발자 A가 user.c 파일을 수정하고, 개발자 B가 auth.c 파일을 수정한다고 하자. 두 사람은 서로 다른 파일을 수정하고 있으므로 버전 관리 시스템 입장에서는 직접적인 줄 단위 충돌은 없을 수 있다. 하지만 auth.c가 user.c의 함수나 구조체를 사용하고 있다면 문제가 생길 수 있다. A가 user.c 안의 함수 이름, 매개변수, 반환값을 바꾸면 B가 수정한 auth.c 코드가 더 이상 정상적으로 동작하지 않을 수 있다.
이처럼 서로 다른 파일을 수정했더라도 파일 사이에 의존 관계(Dependency Relationship) 가 있다면 충돌과 비슷한 문제가 발생할 수 있다. 버전 관리 시스템은 텍스트의 같은 줄이 동시에 수정되었는지는 비교할 수 있지만, 서로 다른 파일의 논리적 관계까지 항상 완벽하게 판단하지는 못한다. 따라서 Git 같은 도구에서 병합이 성공했다고 해서 프로그램이 반드시 정상적으로 동작한다는 뜻은 아니다.
반대로 파일 간 의존성이 거의 없다면, 서로 다른 파일을 수정하는 작업은 비교적 안전하게 병합될 수 있다. 예를 들어 개발자 A가 로그인 화면의 문구를 수정하고, 개발자 B가 전혀 다른 통계 출력 파일을 수정했다면 두 변경은 서로 영향을 주지 않을 가능성이 높다. 이런 경우에는 버전 관리 시스템이 자동으로 변경 내용을 합치기 쉽고, 실제 프로그램 실행에도 문제가 적을 수 있다.
따라서 버전 관리에서 중요한 점은 “같은 파일을 수정했는가”뿐만 아니라 “서로 다른 파일이지만 기능적으로 연결되어 있는가”이다. 같은 파일의 서로 다른 함수를 수정하는 문제는 텍스트 충돌에 가깝고, 서로 다른 파일의 의존성 문제는 구조적 충돌이나 의미적 충돌에 가깝다.
예를 들어 한 개발자가 payment.h 파일에서 함수 선언을 바꾸고, 다른 개발자가 payment.c 파일에서 기존 함수 정의를 기준으로 코드를 수정했다면 두 파일은 다르지만 서로 강하게 연결되어 있다. 병합 과정에서는 충돌이 나지 않을 수도 있지만, 컴파일 단계에서 오류가 발생할 수 있다. 또는 컴파일은 되더라도 실행 결과가 잘못될 수도 있다.
이런 문제를 줄이기 위해서는 파일 간 의존성을 잘 관리해야 한다. 기능별로 모듈(Module)을 분리하고, 인터페이스(Interface)를 명확히 정의하며, 한 파일의 변경이 다른 파일에 어떤 영향을 주는지 확인해야 한다. 또한 변경 내용을 병합한 뒤에는 반드시 빌드(Build)와 테스트(Test)를 수행해야 한다. 버전 관리 시스템이 변경 이력을 관리해주더라도, 프로그램의 동작까지 자동으로 보장해주는 것은 아니기 때문이다.
현대 개발 환경에서는 이런 문제를 줄이기 위해 CI(Continuous Integration) 를 사용하기도 한다. CI는 여러 개발자의 변경 내용을 자주 통합하고, 통합될 때마다 자동으로 빌드와 테스트를 실행하는 방식이다. 이를 통해 서로 다른 파일을 수정했지만 의존성 때문에 발생하는 문제를 빠르게 발견할 수 있다.
정리하면, 버전 관리의 파일 관련 고려사항은 두 단계로 나누어 볼 수 있다. 첫 번째는 같은 파일 안에서 같은 부분을 수정했는지, 다른 부분을 수정했는지의 문제이다. 두 번째는 서로 다른 파일을 수정했더라도 그 파일들이 서로 의존성을 가지고 있는지의 문제이다. 파일이 다르다고 해서 항상 안전한 것은 아니며, 의존성이 있는 파일이라면 한쪽의 변경이 다른 쪽의 오류로 이어질 수 있다.

Git 기본 설치 패키지 (Basic Git Installation Packages)
리눅스/유닉스 환경에서 Git 을 사용하려면 먼저 Git 패키지를 설치해야 한다. Ubuntu나 Debian 계열 리눅스에서는 보통 APT(Advanced Package Tool) 를 사용하여 패키지를 설치한다. 가장 기본적인 설치 명령어는 다음과 같다.
sudo apt install git
이 명령어는 Git을 사용하기 위한 기본 구성 요소를 설치한다. 일반적으로 Git 저장소를 만들고, 파일을 추가하고, 커밋하고, 브랜치를 만들고, 원격 저장소와 연결하는 기본적인 작업은 이 패키지만 설치해도 충분하다. 즉, Git을 처음 배우거나 일반적인 개발 작업을 하기 위해서는 git 패키지만 설치하면 된다.
Debian 패키지 설명에서도 git 패키지는 최소한의 의존성으로 Git의 주요 구성 요소를 제공한다고 설명한다. 그래픽 인터페이스, 다른 버전 관리 시스템과의 연동 도구, 웹 인터페이스 같은 추가 기능은 별도의 git* 패키지로 제공된다.
반면 다음과 같은 명령어도 있다.
sudo apt install git-all
git-all은 Git 하나만 설치하는 것이 아니라, Git과 관련된 다양한 부가 패키지들을 함께 설치하는 패키지이다. 예를 들어 Git GUI, Git Web Interface, Git SVN, Git CVS, Git Email 등 여러 보조 도구가 함께 설치될 수 있다. 그래서 git-all을 설치하면 설치되는 파일과 의존성 패키지의 양이 훨씬 많아질 수 있다.
쉽게 말해 sudo apt install git은 Git의 기본 기능을 설치하는 것이고, sudo apt install git-all은 Git과 관련된 거의 모든 부가 기능까지 함께 설치하는 방식이라고 볼 수 있다. 그래서 단순히 Git 명령어를 사용해 버전 관리를 배우고자 한다면 git만 설치해도 충분하다. 반대로 Git을 웹 인터페이스와 함께 사용하거나, SVN/CVS 같은 다른 버전 관리 시스템과 연동하거나, 이메일 기반 패치 작업처럼 특수한 기능까지 사용하려면 git-all을 고려할 수 있다.
그러나 초보자나 일반적인 개발자에게 git-all은 보통 필요하지 않다. 설치되는 패키지가 많고, 사용하지 않는 기능까지 함께 설치될 수 있기 때문이다. 특히 수업이나 개인 프로젝트에서 Git의 기본 명령어를 배우는 정도라면 git-all보다는 git 패키지를 설치하는 것이 더 간단하고 적절하다.
Git 설치 후에는 다음 명령어로 설치 여부와 버전을 확인할 수 있다.
git --version
이 명령어를 실행했을 때 git version 2.x.x와 같은 형태로 출력되면 Git이 정상적으로 설치된 것이다. 이후에는 사용자 이름과 이메일을 설정해야 한다. Git은 커밋을 만들 때 누가 변경했는지 기록하기 때문에, 처음 설치한 뒤에는 다음과 같이 기본 사용자 정보를 설정한다.
git config --global user.name "사용자이름"
git config --global user.email "이메일주소"
정리하면, Git을 가장 간단하게 사용하려면 sudo apt install git을 실행하면 된다. git-all은 Git 관련 부가 기능을 한꺼번에 설치하는 패키지이므로, 특별히 필요한 기능이 있을 때만 사용하는 것이 좋다. 일반적인 Git 학습과 개발 작업에서는 기본 git 패키지만으로도 충분하다.
📌초보자 기준으로는 다음 순서가 가장 적절하다.
sudo apt update
sudo apt install git
git --version
그다음 Git 사용자 정보를 설정한다.
git config --global user.name "사용자이름"
git config --global user.email "이메일주소"
git-all은 Git의 모든 관련 기능을 실험해보고 싶은 경우에는 사용할 수 있지만, 처음 배우는 단계에서는 보통 필요하지 않다.

Git에서 커밋은 특정 순간의 프로젝트 전체 모습을 찍은 사진과 같다. 하지만 매번 모든 파일을 새로 복사해서 저장하는 것은 아니다. 바뀐 파일은 새로 저장하고, 바뀌지 않은 파일은 이전에 저장된 객체를 다시 가리킨다. 그래서 Git은 전체 프로젝트의 스냅샷을 관리하면서도 저장 공간을 효율적으로 사용할 수 있다.
Git 버전의 개념: 스냅샷 방식 (Git Version Concept: Snapshot Model)
Git에서 하나의 버전(Version) 이 결정된다는 것은 단순히 변경된 파일 몇 개만 따로 저장한다는 뜻이 아니다. Git은 특정 시점의 프로젝트 전체 모습을 하나의 스냅샷(Snapshot) 처럼 기록한다. 여기서 스냅샷은 사진을 찍는 것과 비슷한 개념이다. 어느 순간의 프로젝트 상태를 하나의 장면처럼 남겨두는 것이다.
그림을 보면 시간이 오른쪽으로 흐르고, Version 1부터 Version 5까지의 버전이 차례로 나타난다. 각 버전 아래에는 File A, File B, File C 또는 A1, B1, C2처럼 파일의 상태가 표시되어 있다. 이 그림은 Git이 각 버전에서 프로젝트 전체 상태를 어떻게 바라보는지 설명하기 위한 예시이다.
Version 1에서는 File A, File B, File C가 존재한다. 이후 Version 2에서는 File A가 A1로 바뀌고, File C가 C1로 바뀐다. 반면 File B는 이전과 동일하다. 그림에서 실선으로 표시된 것은 이전 버전과 비교했을 때 변경된 파일을 의미하고, 점선으로 표시된 것은 이전 버전과 내용이 동일한 파일을 의미한다.
Version 3을 보면 A1과 B는 점선으로 표시되어 있다. 이는 Version 2와 비교했을 때 A1과 B는 바뀌지 않았다는 뜻이다. 반면 C1은 C2로 바뀌었기 때문에 새로운 파일 상태로 표시된다. 즉, Version 3이라는 버전은 전체 프로젝트의 상태를 나타내지만, 실제로 새롭게 저장해야 하는 내용은 변경된 C2뿐이라고 볼 수 있다.
이때 중요한 점은 Git이 “버전마다 프로젝트 전체를 사진처럼 기억한다”는 관점과 “변경되지 않은 파일을 매번 새로 복사하지 않는다”는 관점을 함께 가진다는 것이다. 사용자가 보는 관점에서는 Version 3도 A1, B, C2를 모두 포함한 완전한 프로젝트 상태이다. 그러나 내부 저장 방식에서는 이미 이전 버전에 존재하던 A1과 B를 굳이 다시 저장하지 않고, 기존 객체를 참조할 수 있다.
예를 들어 Version 2의 B와 Version 3의 B가 완전히 같은 내용이라면, Git은 같은 내용을 가진 파일을 또 하나 복사해서 저장할 필요가 없다. 이미 저장된 파일 내용을 다시 가리키면 된다. 그래서 Git은 변경된 파일은 새롭게 저장하고, 변경되지 않은 파일은 기존에 저장된 객체를 재사용한다. Git 공식 문서에서도 커밋 객체는 특정 시점의 프로젝트 스냅샷을 나타내는 트리 객체를 가리키며, 변경된 파일에 대해서는 새로운 blob 객체를 저장하고 트리와 커밋 객체를 만든다고 설명한다.
이 구조를 조금 더 기술적으로 보면 Git은 주로 블롭(Blob), 트리(Tree), 커밋(Commit) 객체를 사용한다. 블롭 객체(Blob Object) 는 파일의 실제 내용을 저장한다. 트리 객체(Tree Object) 는 디렉토리 구조와 파일 이름, 그리고 각 파일 내용이 어떤 블롭 객체를 가리키는지를 저장한다. 커밋 객체(Commit Object) 는 특정 시점의 최상위 트리와 부모 커밋, 작성자 정보, 커밋 메시지 등을 저장한다. Git 문서에서도 커밋 객체는 특정 시점의 디렉토리 트리 스냅샷을 나타내는 트리 객체를 참조한다고 설명한다.
따라서 Git의 버전은 단순히 “이전 버전에서 무엇이 바뀌었는가”만 저장하는 방식과는 다르다. Git은 각 커밋을 프로젝트 전체 상태의 스냅샷처럼 다룬다. 하지만 저장 공간을 낭비하지 않기 위해, 내용이 같은 파일은 같은 객체를 재사용한다. 즉, Version 5에서 A2가 이전 버전과 같다면 다시 저장하지 않고 기존 A2를 참조할 수 있고, B2나 C3처럼 변경된 파일만 새로운 내용으로 저장하면 된다.
이 방식은 Git을 이해할 때 매우 중요하다. 사용자는 각 커밋을 “그 시점의 전체 프로젝트 상태”로 생각하면 된다. 하지만 Git 내부에서는 변경되지 않은 파일을 매번 통째로 복사하지 않고, 이미 존재하는 파일 내용 객체를 재사용한다. 그래서 Git은 전체 스냅샷을 관리하면서도 저장 공간을 효율적으로 사용할 수 있다.
정리하면, Git에서 하나의 버전은 특정 순간의 프로젝트 전체 모습을 담은 스냅샷(Snapshot) 이다. 변경된 파일은 새 객체로 저장되고, 변경되지 않은 파일은 기존 객체를 다시 참조한다. 따라서 그림의 점선은 “이전 버전과 동일하므로 새로 저장하지 않고 기존 것을 참조할 수 있다”는 의미로 이해할 수 있다. Git은 이런 방식으로 버전마다 전체 프로젝트 상태를 관리하면서도, 불필요한 중복 저장을 줄인다.

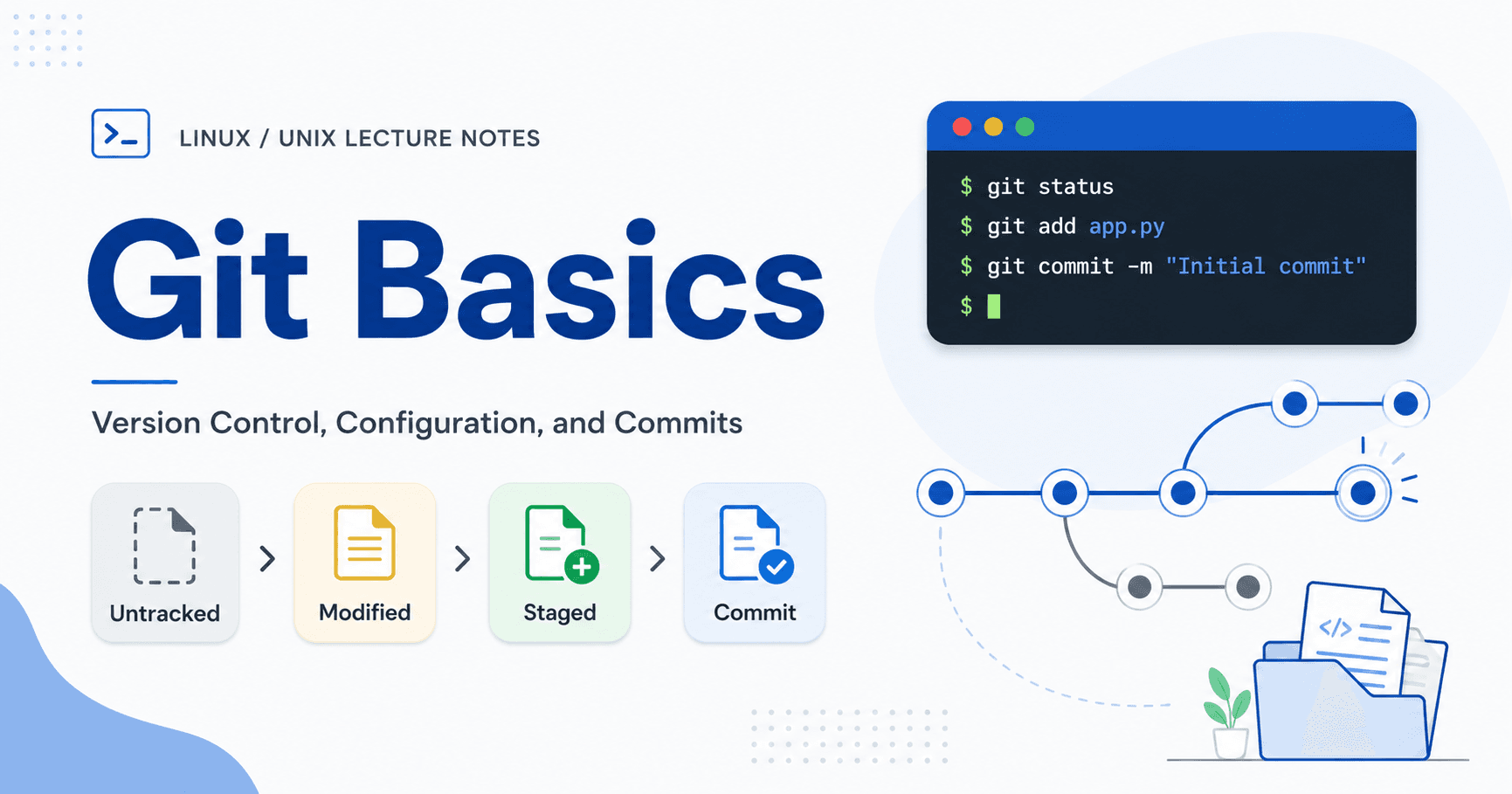
Git은 파일의 상태를 Modified, Staged, Committed 로 구분한다. 파일을 수정하면 Modified 상태가 되고, git add를 실행하면 Staged 상태가 되며, git commit을 실행하면 Committed 상태가 된다. 이 구조를 통해 Git은 어떤 변경을 다음 커밋에 포함할지 선택할 수 있게 해준다.
Git의 기본: 파일의 세 가지 상태 (Git Basics: Three File States)
Git은 파일이 변경되었는지, 변경된 파일이 다음 커밋에 포함될 준비가 되었는지, 그리고 변경 내용이 실제로 저장소에 기록되었는지를 구분해서 관리한다. 이때 Git에서 파일은 기본적으로 수정됨(Modified), 스테이지됨(Staged), 커밋됨(Committed) 이라는 세 가지 상태를 가진다.
먼저 수정됨(Modified) 은 파일의 내용이 이전에 저장된 상태와 달라졌다는 뜻이다. 예를 들어 a.c라는 파일이 있고, 이전에는 a라는 내용만 있었는데 이후에 b라는 내용이 추가되었다면 Git은 이 파일을 수정된 파일로 인식한다. 파일 이름은 여전히 a.c로 같지만, 이전 버전과 비교했을 때 내용이 달라졌기 때문에 Modified 상태가 된다.
이때 Git은 아주 작은 변경도 파일의 변경으로 인식할 수 있다. 코드 한 줄을 추가하거나 삭제하는 것뿐만 아니라, 공백, 줄바꿈, 주석문 변경도 파일 내용이 달라진 것으로 볼 수 있다. 물론 실제로 이 변경이 프로그램의 실행 결과에 영향을 주는지는 별개의 문제이다. Git 입장에서는 파일의 내용이 이전과 달라졌는지가 중요하다.
다음은 스테이지됨(Staged) 상태이다. Staged는 수정된 파일을 다음 커밋에 포함하기 위해 준비해 둔 상태를 말한다. 쉽게 말하면, 변경된 파일을 바로 저장소에 확정하는 것이 아니라, 먼저 스테이징 영역(Staging Area) 에 올려두는 것이다. Git에서는 보통 git add 명령어를 사용해 수정된 파일을 스테이징 영역에 올린다.
예를 들어 a.c 파일을 수정한 뒤 다음 명령어를 실행하면, 해당 파일은 Staged 상태가 된다.
git add a.c
이 상태는 “이 파일의 변경 내용을 다음 커밋에 포함하겠다”라고 표시해 둔 것과 같다. 즉, Staged 상태는 커밋 직전의 대기 상태라고 볼 수 있다.
마지막은 커밋됨(Committed) 상태이다. Committed는 스테이징 영역에 올라간 변경 내용이 Git의 로컬 저장소(Local Repository)에 실제로 기록된 상태를 말한다. Git에서는 보통 git commit 명령어를 사용해 변경 내용을 커밋한다.
git commit -m "Update a.c"
커밋이 완료되면 해당 변경 내용은 Git의 로컬 데이터베이스에 저장된다. 이때 Git은 단순히 파일을 복사해서 저장하는 것이 아니라, 변경된 상태를 하나의 기록으로 남긴다. 이 기록에는 어떤 파일이 변경되었는지, 누가 변경했는지, 언제 변경했는지, 어떤 메시지를 남겼는지 등의 정보가 포함된다.
따라서 Git에서 커밋(Commit) 은 단순히 “명령어를 실행한다”는 의미가 아니라, 프로젝트의 특정 시점 상태를 로컬 저장소에 저장하는 작업이다. Git은 이러한 커밋들을 통해 프로젝트의 변경 이력을 관리한다. 그래서 Git을 데이터베이스 관점에서 보면, 각 커밋은 프로젝트의 한 시점에 대한 기록이고, Git 저장소는 이러한 기록들이 쌓여 있는 데이터베이스라고 볼 수 있다.
정리하면 Git에서 파일의 세 가지 상태는 다음과 같다. Modified 는 파일이 수정되었지만 아직 다음 커밋에 포함되도록 준비되지 않은 상태이다. Staged 는 수정된 파일이 다음 커밋에 포함되도록 스테이징 영역에 올라간 상태이다. Committed 는 변경 내용이 로컬 저장소에 저장 완료된 상태이다.
이 세 가지 상태를 이해하면 Git의 기본 흐름도 자연스럽게 이해할 수 있다. 먼저 파일을 수정하면 Modified 상태가 되고, git add로 스테이징 영역에 올리면 Staged 상태가 되며, git commit으로 저장소에 기록하면 Committed 상태가 된다. Git의 기본 작업 흐름은 이 세 단계를 중심으로 움직인다.
파일 수정 → git add → git commit
Modified → Staged → Committed
결국 Git은 파일이 단순히 “있다” 또는 “없다”로만 관리되는 것이 아니라, 변경되었는지, 커밋 준비가 되었는지, 저장소에 기록되었는지를 구분해서 관리한다. 이 구조 덕분에 개발자는 어떤 변경을 커밋에 포함할지 선택할 수 있고, 프로젝트의 변경 이력을 더 세밀하게 관리할 수 있게되었다.

Git 설정은 시스템(System), 글로벌(Global), 로컬(Local) 범위로 나뉜다. 시스템 설정은 모든 사용자에게 적용되고, 글로벌 설정은 특정 사용자에게 적용되며, 로컬 설정은 특정 저장소에만 적용된다. 같은 설정이 여러 범위에 존재하면 더 구체적인 설정이 우선 적용되므로, 최종적으로는 로컬 설정이 가장 우선적으로 적용된다.
Git 사용 설정 종류 (Git Configuration Levels)
Git을 사용하기 위해서는 기본적인 설정(Configuration) 이 필요하다. Git 설정은 사용자 이름, 이메일, 편집기, 줄바꿈 처리 방식, 별칭(alias) 등 Git이 동작할 때 참고하는 여러 정보를 저장한다. 이 설정은 적용 범위에 따라 크게 시스템(System), 글로벌(Global), 로컬(Local) 세 가지로 나눌 수 있다.
Git 설정에서 중요한 특징은 오버라이드(Override) 구조이다. 오버라이드는 기존 설정을 더 구체적인 설정이 덮어쓴다는 뜻이다. 즉, 넓은 범위의 설정이 먼저 적용되더라도, 더 좁은 범위에서 같은 항목을 다시 설정하면 좁은 범위의 설정이 우선 적용된다.
가장 넓은 범위는 시스템 설정(System Configuration) 이다. 시스템 설정은 해당 컴퓨터를 사용하는 모든 사용자에게 적용되는 설정이다. 리눅스 환경에서는 보통 다음 경로에 저장된다.
/etc/gitconfig
이 설정은 컴퓨터 전체에 적용되기 때문에, 같은 시스템을 사용하는 모든 사용자가 영향을 받는다. 예를 들어 학교 실습실이나 서버처럼 여러 사용자가 같은 컴퓨터를 사용하는 환경에서는 시스템 설정이 공통 기본값처럼 작동할 수 있다.
두 번째는 글로벌 설정(Global Configuration) 이다. 글로벌 설정은 특정 사용자에게 적용되는 설정이다. 즉, 같은 컴퓨터 안에서도 사용자 계정마다 다른 Git 설정을 가질 수 있다. 리눅스에서는 보통 다음 위치에 저장된다.
~/.gitconfig
또는 다음 위치가 사용될 수 있다.
~/.config/git/config
여기서 ~는 현재 사용자의 홈 디렉토리(Home Directory)를 의미한다. 예를 들어 사용자 이름이 student라면 ~/.gitconfig는 /home/student/.gitconfig와 같은 의미가 될 수 있다. 일반적으로 Git을 처음 설치한 뒤 사용자 이름과 이메일을 설정할 때 이 글로벌 설정을 많이 사용한다.
예를 들어 다음 명령어는 현재 사용자에게 적용되는 이름과 이메일을 설정한다.
git config --global user.name "사용자이름"
git config --global user.email "이메일주소"
세 번째는 로컬 설정(Local Configuration) 이다. 로컬 설정은 특정 Git 저장소, 즉 특정 프로젝트에만 적용되는 설정이다. 로컬 설정은 해당 프로젝트 폴더 안의 다음 파일에 저장된다.
.git/config
로컬 설정은 프로젝트 단위로 적용되기 때문에 가장 구체적인 설정이다. 예를 들어 개인 프로젝트에서는 개인 이메일을 사용하고, 회사 프로젝트에서는 회사 이메일을 사용해야 한다면 로컬 설정을 통해 프로젝트마다 다른 이메일을 지정할 수 있다.
Git 설정의 우선순위는 일반적으로 다음과 같다.
System → Global → Local
즉, 시스템 설정이 가장 넓은 기본값이고, 글로벌 설정이 그 위에 적용되며, 로컬 설정이 최종적으로 가장 우선 적용된다. 같은 설정 항목이 여러 위치에 존재한다면, 더 구체적인 로컬 설정이 글로벌 설정을 덮어쓰고, 글로벌 설정은 시스템 설정을 덮어쓴다.
예를 들어 시스템 설정에는 사용자 이름이 Linux User로 되어 있고, 글로벌 설정에는 Student로 되어 있으며, 특정 프로젝트의 로컬 설정에는 Project Developer로 되어 있다면, 해당 프로젝트 안에서는 최종적으로 Project Developer가 적용된다. 이것이 Git 설정에서 말하는 오버라이드(Override) 의 의미이다.
이 구조는 Git을 여러 환경에서 유연하게 사용할 수 있게 해준다. 모든 사용자에게 공통으로 적용할 설정은 시스템 범위에 두고, 개인 사용자가 자주 쓰는 기본 설정은 글로벌 범위에 둔다. 그리고 특정 프로젝트에서만 달라져야 하는 설정은 로컬 범위에 둔다.
정리하면, Git 설정은 시스템(System), 글로벌(Global), 로컬(Local) 세 단계로 나뉜다. 시스템 설정은 컴퓨터 전체와 모든 사용자에게 적용되고, 글로벌 설정은 특정 사용자에게 적용되며, 로컬 설정은 특정 저장소나 프로젝트에 적용된다. 같은 설정이 여러 단계에 존재할 경우, 더 구체적인 설정이 더 넓은 설정을 덮어쓰며, 최종적으로는 로컬 설정이 가장 우선적으로 적용된다.

Git 사용 설정 확인과 변경 (Git Configuration Check & Set)
Git을 사용하려면 먼저 기본 설정을 확인하고 필요한 값을 지정해야 한다. Git 설정은 앞에서 본 것처럼 시스템(System), 글로벌(Global), 로컬(Local) 범위로 나뉘며, 같은 설정이 여러 곳에 존재할 경우 더 좁은 범위의 설정이 우선 적용된다. 즉, System → Global → Local 순서로 갈수록 우선순위가 높아지고, 최종적으로는 특정 저장소의 로컬 설정(Local Configuration) 이 가장 우선적으로 적용된다.
현재 Git에 어떤 설정들이 적용되어 있는지 확인하려면 터미널에서 다음 명령어를 사용할 수 있다.
git config --list --show-origin
여기서 --list는 현재 적용 가능한 Git 설정 목록을 보여주는 옵션이고, --show-origin은 각 설정이 어느 파일에서 온 것인지 함께 보여주는 옵션이다. 이 명령어를 사용하면 설정값뿐만 아니라 해당 설정이 시스템 설정(System Configuration) 에서 온 것인지, 글로벌 설정(Global Configuration) 에서 온 것인지, 아니면 로컬 설정(Local Configuration) 에서 온 것인지 확인할 수 있다.
Git 설정을 변경할 때는 적용 범위에 따라 옵션을 다르게 사용한다. 특정 프로젝트, 즉 현재 Git 저장소에만 설정을 적용하려면 --local 옵션을 사용한다.
git config --local user.name "korea cyber university"
git config --local user.email "noreply@koreacu.ac.kr"
이 명령어는 현재 저장소의 .git/config 파일에 사용자 이름과 이메일을 저장한다. 따라서 이 설정은 현재 프로젝트에서만 적용된다. 예를 들어 개인 프로젝트에서는 개인 이메일을 사용하고, 학교 과제 저장소에서는 학교 이메일을 사용하고 싶을 때 로컬 설정을 사용할 수 있다.
특정 사용자 계정 전체에 적용하려면 --global 옵션을 사용한다.
git config --global user.name "사용자이름"
git config --global user.email "이메일주소"
글로벌 설정은 보통 현재 사용자의 홈 디렉토리에 있는 다음 파일에 저장된다.
~/.gitconfig
또는 환경에 따라 다음 경로가 사용될 수도 있다.
~/.config/git/config
여기서 ~는 현재 사용자의 홈 디렉토리(Home Directory)를 의미한다. 따라서 --global은 컴퓨터 전체가 아니라, 현재 로그인한 특정 사용자에게 적용되는 설정이라고 이해하면 된다.
컴퓨터의 모든 사용자에게 공통으로 적용되는 설정은 --system 옵션을 사용한다.
git config --system user.name "공통사용자이름"
시스템 설정은 리눅스 환경에서 보통 다음 파일에 저장된다.
/etc/gitconfig
이 파일은 시스템 전체 설정이므로 일반 사용자 권한으로는 수정이 제한될 수 있다. 따라서 실제로 --system 설정을 변경하려면 관리자 권한이 필요할 수 있다.
sudo git config --system user.name "공통사용자이름"
정리하면, --system은 모든 사용자에게 적용되는 설정이고, --global은 현재 사용자에게 적용되는 설정이며, --local은 현재 Git 저장소에만 적용되는 설정이다. 같은 항목이 여러 위치에 설정되어 있으면 더 구체적인 설정이 기존 설정을 오버라이드(Override) 한다. 즉, 로컬 설정이 글로벌 설정을 덮어쓰고, 글로벌 설정이 시스템 설정을 덮어쓴다.
명령어를 입력할 때는 따옴표의 종류도 주의해야 한다. 일반적으로 값에 공백이 들어갈 때는 작은따옴표(')나 큰따옴표(")를 사용할 수 있다.
git config --local user.name "korea cyber university"
git config --local user.name 'korea cyber university'
두 명령어는 일반적인 문자열 설정에서는 비슷하게 동작한다. 하지만 백틱(`)은 작은따옴표가 아니다. 리눅스 셸에서 백틱은 명령어 실행 결과를 치환하는 용도로 사용될 수 있으므로, 단순 문자열을 감쌀 때 작은따옴표와 혼동하면 안 된다.
예를 들어 아래처럼 백틱을 사용하면 단순 문자열이 아니라 셸이 그 안의 내용을 명령어처럼 해석하려고 할 수 있다.
git config --local user.name `korea cyber university`
따라서 Git 설정 값을 입력할 때는 보통 큰따옴표(" ") 또는 작은따옴표(' ')를 사용하는 것이 안전하다. 특히 사용자 이름처럼 공백이 포함될 수 있는 값은 따옴표로 감싸는 것이 좋다.
결국 Git 설정은 “어디에 적용할 것인가”가 핵심이다. 모든 사용자에게 적용할 설정은 System, 현재 사용자에게 적용할 설정은 Global, 특정 프로젝트에만 적용할 설정은 Local 범위에 저장한다. 그리고 실제 적용 결과를 확인할 때는 git config --list --show-origin을 사용하면 어떤 설정이 어느 파일에서 왔는지 확인할 수 있다.

Git 사용 설정: 편집기와 기본 브랜치 설정 (Git Configuration: Editor & Default Branch)
Git을 사용할 때는 사용자 이름과 이메일뿐만 아니라, 기본 편집기와 기본 브랜치 이름도 설정할 수 있다. 이러한 설정은 Git을 사용할 때 반복적으로 적용되는 기본 동작을 정하는 역할을 한다.
먼저 기본 편집기(Default Editor) 설정이 있다. Git에서는 커밋 메시지(Commit Message)를 입력해야 하는 경우가 많다. 보통 간단한 커밋 메시지는 다음처럼 명령어에서 바로 작성할 수 있다.
git commit -m "커밋 메시지"
하지만 -m 옵션을 사용하지 않고 git commit만 실행하면, Git은 커밋 메시지를 입력하라고 편집기 창을 연다. 이때 어떤 편집기를 열 것인지 정하는 설정이 core.editor 이다.
예제에서는 다음과 같이 Vim을 기본 편집기로 설정하고 있다.
git config --global core.editor vim
이 명령어는 현재 사용자(Global) 범위에서 Git의 기본 편집기를 Vim 으로 설정한다. 이후 커밋 메시지를 직접 입력해야 할 때 Git은 Vim을 실행한다.
다만 모든 사용자가 Vim을 편하게 사용하는 것은 아니다. Vim은 리눅스/유닉스 환경에서 오래전부터 많이 사용된 강력한 텍스트 편집기지만, 처음 사용하는 사람에게는 조작 방식이 어렵게 느껴질 수 있다. Vim을 사용하지 않는다면 다른 편집기를 설정해도 된다. 예를 들어 Nano 를 사용하고 싶다면 다음처럼 설정할 수 있다.
git config --global core.editor nano
또는 Emacs 를 사용한다면 다음과 같이 설정할 수 있다.
git config --global core.editor emacs
즉, Git에서 편집기 설정이 필요한 이유는 Git 자체가 문서를 작성하기 위해서라기보다, 커밋 메시지처럼 사용자가 직접 텍스트를 입력해야 하는 상황에서 어떤 편집기를 사용할지 정하기 위해서이다.
다음으로 기본 브랜치(Default Branch) 이름 설정이 있다. Git에서 새 저장소를 만들면 기본 브랜치가 생성된다. 과거에는 기본 브랜치 이름으로 master가 많이 사용되었지만, 최근에는 main을 사용하는 경우가 많다. 그래서 새 Git 저장소를 만들 때 기본 브랜치 이름을 main으로 지정하려면 다음 명령어를 사용할 수 있다.
git config --global init.defaultBranch main
이 설정은 이후 git init으로 새 저장소를 만들 때 기본 브랜치 이름을 main으로 지정하게 한다. 이미 만들어진 저장소의 브랜치 이름을 바꾸는 명령어가 아니라, 앞으로 새로 생성할 저장소의 기본 브랜치 이름을 정하는 설정이라는 점이 중요하다.
정리하면, Git 설정에서는 사용자의 작업 환경에 맞게 기본 편집기와 기본 브랜치 이름을 지정할 수 있다. core.editor는 Git이 커밋 메시지 등을 입력받을 때 사용할 편집기를 정하는 설정이고, init.defaultBranch는 새 저장소를 만들 때 기본으로 생성될 브랜치 이름을 정하는 설정이다.

Git 사용: 저장소 초기화와 .git 디렉토리 (Git Usage: Repository Initialization & .git Directory)
Git을 사용하려면 먼저 버전 관리를 적용할 디렉토리에서 저장소 초기화(Repository Initialization) 를 해야 한다. Git을 설치했다고 해서 모든 디렉토리가 자동으로 Git 저장소가 되는 것은 아니다. 사용자가 원하는 프로젝트 디렉토리로 이동한 뒤, 그 위치에서 Git 저장소를 만들겠다고 지정해야 한다.
이를 위해 사용하는 명령어가 다음과 같다.
git init
git init 명령어를 실행하면 현재 디렉토리 안에 숨김 디렉토리인 .git 디렉토리가 생성된다. 리눅스/유닉스 환경에서는 이름이 점(.)으로 시작하는 파일이나 디렉토리는 기본적으로 숨김 파일(Hidden File)로 취급된다. 그래서 일반적인 ls 명령어만으로는 보이지 않을 수 있고, 다음처럼 -a 옵션을 사용해야 확인할 수 있다.
ls -a
.git 디렉토리는 Git 저장소의 핵심이다. 이 안에는 버전 관리에 필요한 여러 정보가 저장된다. 예를 들어 커밋 이력(Commit History), 브랜치 정보(Branch Information), 설정 파일(Configuration File), 객체 데이터(Object Data), 인덱스(Index) 등이 .git 디렉토리 안에 보관된다.
즉, 우리가 프로젝트 폴더에서 보는 일반 파일들은 실제 작업 파일이고, .git 디렉토리는 그 파일들의 변경 이력을 관리하는 내부 저장소라고 볼 수 있다. 사용자는 보통 소스 코드 파일을 수정하고 git add, git commit 같은 명령어를 사용하지만, Git은 내부적으로 .git 디렉토리에 필요한 정보를 기록하면서 버전 관리를 수행한다.
중요한 점은 .git 디렉토리를 삭제하면 해당 프로젝트의 Git 이력이 사라진다는 것이다. 예를 들어 프로젝트 폴더 안에 main.c, README.md 같은 파일이 남아 있더라도, .git 디렉토리를 삭제하면 Git은 더 이상 그 폴더를 Git 저장소로 인식하지 못한다. 현재 파일 자체는 남아 있을 수 있지만, 이전 커밋 이력, 브랜치 정보, 로컬 설정 등 버전 관리와 관련된 정보는 사라진다.
따라서 .git 디렉토리는 일반적인 폴더처럼 함부로 삭제하면 안 된다. 특히 Git을 처음 배우는 단계에서는 “.git은 Git이 자동으로 만든 숨김 폴더니까 지워도 되겠지”라고 생각할 수 있지만, 실제로는 Git 저장소의 핵심 데이터가 들어 있는 중요한 디렉토리이다.
다만 .git 디렉토리를 삭제한다고 해서 현재 작업 중인 파일 자체가 반드시 삭제되는 것은 아니다. 예를 들어 프로젝트 폴더 안의 a.c, b.c, index.html 같은 파일은 그대로 남아 있을 수 있다. 하지만 Git이 관리하던 변경 이력과 저장소 정보는 사라진다. 그래서 해당 폴더는 Git 입장에서는 그냥 일반 디렉토리가 된다.
정리하면, Git을 사용하기 위해서는 프로젝트 디렉토리에서 git init을 실행하여 저장소를 초기화한다. 이때 생성되는 .git 디렉토리에는 Git 버전 관리에 필요한 핵심 정보들이 저장된다. 따라서 .git 디렉토리를 삭제하면 현재 파일은 남아 있더라도, Git이 관리하던 이력과 저장소 정보는 사라진다는 점을 반드시 알아두어야 한다.
📌추가 설명 (Additional Notes)
.git 디렉토리를 확인하는 기본 흐름은 다음과 같다.
mkdir my-project
cd my-project
git init
ls -a
이때 .git이 보이면 해당 디렉토리가 Git 저장소로 초기화된 것이다.
Git 저장소인지 확인하고 싶다면 다음 명령어를 사용할 수 있다.
git status
Git 저장소 안이라면 현재 브랜치와 파일 상태가 출력된다. 반대로 .git 디렉토리가 없거나 Git 저장소가 아니라면 오류 메시지가 나타난다.

Git 기본 사용법: 새 파일 추가와 Untracked 상태 (Git Basic Usage: Adding a New File & Untracked State)
Git 저장소를 만든 뒤 새 파일을 생성하면, Git은 그 파일을 자동으로 버전 관리 대상으로 포함하지 않는다. 예를 들어 Git 저장소 안에서 다음과 같이 helloWorld.c 파일을 만들었다고 하자.
vi helloWorld.c
또는 다른 편집기를 사용해서 같은 파일을 만들 수도 있다.
nano helloWorld.c
이렇게 새 파일을 만들고 나서 현재 Git 저장소의 상태를 확인하려면 다음 명령어를 사용한다.
git status
git status는 현재 저장소에서 어떤 파일이 변경되었는지, 어떤 파일이 스테이징 영역(Staging Area)에 올라가 있는지, 어떤 파일이 아직 Git의 관리 대상이 아닌지를 보여준다.
새로 만든 helloWorld.c 파일은 처음에는 Untracked Files 항목에 표시된다. 여기서 Untracked 는 Git이 아직 해당 파일을 추적하지 않는다는 뜻이다. 즉, 파일은 실제 디렉토리 안에 존재하지만, Git은 아직 이 파일의 변경 이력을 관리하지 않는다.
화면에 표시된 메시지를 보면 다음과 같은 내용이 나온다.
Untracked files:
(use "git add <file>..." to include in what will be committed)
helloWorld.c
이 문장은 “이 파일을 다음 커밋에 포함하려면 git add <file> 명령어를 사용하라”는 뜻이다. 즉, Git에게 “이 파일을 앞으로 관리 대상으로 삼아라”라고 알려주어야 한다.
이를 위해 다음 명령어를 입력한다.
git add helloWorld.c
git add는 파일을 스테이징 영역(Staging Area) 에 올리는 명령어이다. 새 파일의 경우에는 이 명령어를 통해 Git이 해당 파일을 추적하기 시작한다. 즉, helloWorld.c는 더 이상 Untracked 상태가 아니라, 다음 커밋에 포함될 준비가 된 Staged 상태가 된다.
여기서 중요한 점은 Git이 파일을 자동으로 모두 기록하지 않는다는 것이다. Git 저장소 안에 파일이 존재한다고 해서 무조건 버전 관리 대상이 되는 것은 아니다. 사용자가 git add를 통해 명시적으로 추가해야 Git이 해당 파일을 관리 대상으로 인식한다.
이는 실수를 줄이기 위한 구조이기도 하다. 프로젝트 폴더 안에는 임시 파일, 실행 결과 파일, 로그 파일, 빌드 결과물처럼 버전 관리에 포함하지 않아야 하는 파일도 있을 수 있다. Git은 사용자가 어떤 파일을 기록할지 선택할 수 있도록, 새 파일을 처음부터 자동으로 추적하지 않고 Untracked 상태로 둔다.
정리하면, Git 저장소 안에서 새 파일을 만들면 처음에는 Untracked 상태가 된다. 이 상태는 Git이 아직 해당 파일을 감시하거나 기록하지 않는 상태이다. 새 파일을 버전 관리 대상으로 포함하려면 git add 파일명 명령어를 실행해야 한다. 이후 파일은 Staged 상태가 되고, 다음 git commit을 실행할 때 저장소 이력에 기록될 수 있다.
vi helloWorld.c
git status
git add helloWorld.c
git status
이 흐름을 통해 새 파일이 Git에서 어떻게 관리 대상으로 들어가는지 확인할 수 있다.
📌추가 설명 (Additional Notes)
Git에서 새 파일을 추가하는 기본 흐름은 다음과 같다.
echo "hello world" > helloWorld.c
git status
git add helloWorld.c
git status
git commit -m "Add helloWorld.c"
상태 변화는 다음처럼 이해할 수 있다.
Untracked → Staged → Committed
즉, 새 파일은 처음에는 Git이 모르는 파일이고, git add를 실행하면 다음 커밋에 포함될 준비가 되며, git commit을 실행하면 Git 이력에 저장된다.

새 파일을 만들면 Git은 처음에 그 파일을 Untracked 상태로 표시한다. git add를 실행하면 파일은 Staged 상태가 되어 다음 커밋에 포함될 준비가 된다. 하지만 아직 커밋된 것은 아니므로, 실제 이력에 저장하려면 git commit을 실행해야 한다.
Git 기본 사용법: git add와 Staged 상태 (Git Basic Usage: git add & Staged State)
Git 저장소 안에서 새로운 파일을 만들면, 처음에는 Git이 그 파일을 자동으로 관리하지 않는다. 예를 들어 helloWorld.c라는 파일을 새로 만들고 git status를 실행하면, Git은 이 파일을 추적되지 않은 파일(Untracked File) 로 표시한다. 이는 파일이 실제 디렉토리 안에는 존재하지만, 아직 Git의 버전 관리 대상에는 포함되지 않았다는 뜻이다.
새 파일을 Git의 관리 대상으로 포함하려면 git add 명령어를 사용한다.
git add helloWorld.c
이 명령어를 실행하면 helloWorld.c 파일은 Git의 스테이징 영역(Staging Area) 에 올라간다. 스테이징 영역은 다음 커밋(Commit) 에 포함할 변경 내용을 임시로 모아두는 공간이다. 즉, git add는 단순히 “파일을 감시 대상으로 등록한다”는 의미도 있지만, 더 정확하게는 “이 파일의 현재 변경 내용을 다음 커밋에 포함하도록 준비한다”는 뜻이다.
git add helloWorld.c를 실행한 뒤 다시 git status를 확인하면, 화면에는 다음과 비슷한 내용이 나타난다.
Changes to be committed:
new file: helloWorld.c
여기서 Changes to be committed 는 “커밋될 예정인 변경 사항”이라는 뜻이다. 그리고 new file: helloWorld.c 는 새 파일인 helloWorld.c가 다음 커밋에 포함될 준비가 되었다는 의미이다. 이 상태가 바로 Staged 상태이다.
이전 단계의 Untracked 상태와 비교하면 차이가 분명하다. Untracked 상태에서는 Git이 아직 해당 파일을 관리하지 않는다. 하지만 git add를 실행하면 Git은 그 파일을 다음 커밋에 포함할 대상으로 인식한다. 다만 아직 커밋이 완료된 것은 아니다. 즉, 파일이 Git 이력에 영구적으로 저장된 상태는 아니고, 커밋을 기다리는 상태이다.
화면에 보이는 use "git rm --cached <file>..." to unstage라는 문장은, 스테이징 영역에 올린 파일을 다시 내리고 싶을 때 사용할 수 있는 안내이다. 예를 들어 실수로 helloWorld.c를 git add 했다면 다음 명령어로 스테이징 상태를 취소할 수 있다.
git rm --cached helloWorld.c
이 명령어는 파일 자체를 삭제하는 것이 아니라, Git의 스테이징 영역에서만 제거한다. 즉, helloWorld.c 파일은 작업 디렉토리에 그대로 남아 있지만, 다음 커밋에 포함될 예정에서는 빠지게 된다. 새 파일의 경우 다시 Untracked 상태로 돌아간다고 이해하면 된다.
정리하면, 새 파일을 만들면 처음에는 Untracked 상태가 된다. 이후 git add helloWorld.c를 실행하면 해당 파일은 Staged 상태가 되어 다음 커밋에 포함될 준비가 된다. 하지만 아직 Committed 상태는 아니므로, 실제 Git 이력에 저장하려면 이후에 git commit을 실행해야 한다.
vi helloWorld.c
git status
git add helloWorld.c
git status
git commit -m "Add helloWorld.c"
이 흐름에서 상태 변화는 다음과 같이 정리할 수 있다.
Untracked → Staged → Committed
Git의 기본 사용법에서 이 흐름은 매우 중요하다. Git은 새 파일이 생겼다고 해서 바로 기록하지 않고, 사용자가 git add로 명시적으로 다음 커밋에 포함할 변경 내용을 선택하게 한다. 이 구조 덕분에 개발자는 어떤 파일을 커밋할지 직접 결정할 수 있다.

Git 기본 사용법: 커밋으로 현재 상태 저장하기 (Git Basic Usage: Commit)
Git에서 파일을 새로 만들고 git add로 스테이징 영역에 올렸다면, 다음 단계는 커밋(Commit) 이다. 커밋은 현재까지 준비된 변경 내용을 Git 저장소에 영구적인 기록으로 남기는 작업이다. 쉽게 말하면, 지금 상태를 하나의 버전으로 “박제해서 보관하는 것”이라고 이해할 수 있다.
커밋을 실행할 때는 보통 다음과 같이 git commit 명령어를 사용한다.
git commit -m "first git commit"
여기서 -m 옵션은 커밋 메시지(Commit Message) 를 명령어 안에서 바로 작성하겠다는 의미이다. 커밋 메시지는 사람이 나중에 변경 내용을 이해할 수 있도록 남기는 설명이다. 따라서 아무 의미 없는 문장보다는, “무엇을 변경했는지”를 알 수 있는 내용을 작성하는 것이 좋다.
예를 들어 새 파일 helloWorld.c를 처음 추가한 상황이라면 다음과 같은 메시지를 사용할 수 있다.
git commit -m "Add helloWorld.c"
커밋을 실행하면 Git은 스테이징 영역에 올라와 있던 변경 내용을 로컬 저장소(Local Repository)에 기록한다. 이때 화면에는 커밋 결과가 출력된다. 예시 화면에서는 다음과 같은 내용이 보인다.
[master (root-commit) 1c686a5] first git commit
1 file changed, 5 insertions(+)
create mode 100644 helloWorld.c
여기서 root-commit 은 이 저장소에서 처음 만들어진 커밋이라는 뜻이다. 아직 이전 커밋이 없기 때문에, 첫 번째 커밋은 루트 커밋(Root Commit)이 된다.
1 file changed는 하나의 파일이 변경되었다는 의미이고, 5 insertions(+)는 다섯 줄이 추가되었다는 의미이다. create mode 100644 helloWorld.c는 helloWorld.c라는 새 파일이 생성되었고, 일반 파일 권한 모드로 저장되었다는 뜻이다.
중간에 보이는 1c686a5 같은 알 수 없는 문자와 숫자의 조합은 커밋 해시(Commit Hash) 또는 커밋 ID(Commit ID) 의 짧은 형태이다. Git은 각 커밋을 고유하게 식별하기 위해 해시 값을 사용한다. 이 값은 커밋마다 다르게 생성되며, 나중에 특정 커밋으로 이동하거나, 특정 시점의 내용을 확인하거나, 이전 상태로 되돌릴 때 사용할 수 있다.
즉, 커밋 해시는 Git에서 각 버전을 구분하는 식별자(Identifier) 역할을 한다. 사람이 보기에는 복잡한 문자처럼 보이지만, Git 입장에서는 “이 커밋이 정확히 어떤 기록인가”를 구분하는 중요한 값이다.
커밋을 완료한 뒤 다시 상태를 확인하려면 다음 명령어를 사용한다.
git status
커밋이 정상적으로 완료되었고 추가로 수정된 파일이 없다면 다음과 같은 메시지가 나타난다.
On branch master
nothing to commit, working tree clean
여기서 nothing to commit 은 현재 커밋할 변경 내용이 없다는 뜻이다. working tree clean 은 작업 디렉토리(Working Tree)가 깨끗하다는 뜻으로, 마지막 커밋 이후 변경된 파일이 없다는 의미이다.
즉, 파일을 수정하고 git add로 스테이징한 뒤 git commit으로 저장소에 기록했기 때문에, 현재 작업 공간에는 Git이 새로 기록해야 할 변화가 남아 있지 않은 상태이다.
정리하면, git commit은 Git에서 변경 내용을 하나의 버전으로 확정하는 명령어이다. git add가 다음 커밋에 포함할 파일을 준비하는 단계라면, git commit은 그 준비된 변경 내용을 실제 Git 이력에 저장하는 단계이다. 커밋이 만들어지면 Git은 고유한 커밋 해시를 부여하고, 이 값을 통해 나중에 특정 버전을 찾거나 되돌아갈 수 있다.
Git의 기본 흐름은 다음과 같이 정리할 수 있다.
파일 생성 또는 수정 → git add → git commit → git status 확인
상태 변화로 보면 다음과 같다.
Untracked 또는 Modified → Staged → Committed
결국 Git에서 커밋은 단순한 저장이 아니라, 프로젝트의 특정 시점을 기록하는 작업이다. 앞으로 Git을 실습할 때는 파일을 수정하고, 변경 내용을 스테이징하고, 커밋을 만든 뒤, git status로 현재 상태가 깨끗한지 확인하는 흐름을 반복하게 된다.
📌추가 설명 (Additional Notes)
커밋 메시지는 나중에 이력을 볼 때 매우 중요하다. 예를 들어 다음처럼 작성하는 것이 좋다.
git commit -m "Add helloWorld.c"
git commit -m "Fix login error"
git commit -m "Update README"
반대로 다음처럼 너무 모호한 메시지는 좋지 않다.
git commit -m "update"
git commit -m "fix"
git commit -m "test"
커밋 메시지는 “나중에 내가 봐도 이 변경이 무엇인지 알 수 있게” 작성하는 것이 가장 좋다.

Git에서 새 파일은 처음에 Untracked 상태이다. git add를 하면 Staged 상태가 되고, git commit을 하면 저장소에 기록되어 Unmodified 상태가 된다. 이후 파일을 수정하면 Modified 상태가 되며, 다시 git add와 git commit을 거쳐 새로운 버전으로 저장된다. Git은 이 과정을 통해 어떤 변경을 기록할지 사용자가 직접 선택할 수 있게 해준다.
파일의 상태 변화 주기 (File Status Lifecycle in Git)
Git에서 파일은 작업 과정에 따라 여러 상태를 오가게 된다. 대표적인 상태는 추적되지 않음(Untracked), 수정되지 않음(Unmodified), 수정됨(Modified), 스테이지됨(Staged) 이다. 이 상태 변화를 이해하면 Git의 기본 사용 흐름을 더 쉽게 따라갈 수 있다.
먼저 Untracked 상태는 Git이 아직 관리하지 않는 파일을 의미한다. 새 파일을 만들었지만 아직 git add를 하지 않았다면, Git은 그 파일을 추적 대상으로 보지 않는다. 즉, 파일은 디렉토리에 존재하지만 Git의 변경 이력에는 포함되지 않은 상태이다.
이 파일을 Git의 관리 대상으로 포함하려면 git add 명령어를 사용한다.
git add 파일명
새 파일에 대해 git add를 실행하면 파일은 Staged 상태가 된다. 여기서 Staged는 무대(Stage)에 올려놓았다는 의미처럼 이해할 수 있다. 즉, “이 파일을 다음 커밋(Commit)에 포함하겠다”라고 표시한 상태이다.
그다음 git commit을 실행하면 Staged 상태에 있던 파일이 Git 저장소에 기록된다. 커밋이 완료되면 해당 파일은 Git이 알고 있는 최신 원본 상태가 된다. 이 상태를 Unmodified 라고 한다. Unmodified는 마지막 커밋 이후 파일이 수정되지 않았다는 뜻이다.
git commit -m "커밋 메시지"
이후 사용자가 파일 내용을 다시 수정하면, Git은 해당 파일을 Modified 상태로 인식한다. Modified는 이미 Git이 추적하고 있는 파일이지만, 마지막 커밋 이후 내용이 바뀐 상태를 의미한다. 예를 들어 helloWorld.c 파일을 커밋한 뒤 다시 내용을 추가하거나 수정하면, 그 파일은 Modified 상태가 된다.
Modified 상태의 파일을 다시 다음 커밋에 포함하려면 git add를 실행해야 한다. 이때 git add는 단순히 새 파일을 추적 대상으로 등록하는 역할만 하는 것이 아니라, 수정된 파일의 현재 상태를 다음 커밋에 포함하도록 스테이징(Staging) 하는 역할을 한다.
git add helloWorld.c
이렇게 하면 Modified 상태였던 파일은 다시 Staged 상태가 된다. 그리고 git commit을 실행하면 그 변경 내용이 새로운 커밋으로 저장되고, 파일은 다시 Unmodified 상태가 된다.
따라서 Git에서 기본적인 상태 변화는 다음과 같이 이해할 수 있다.
Untracked → Staged → Unmodified → Modified → Staged → Unmodified
조금 더 실제 작업 흐름으로 표현하면 다음과 같다.
파일 생성
git add 파일명
git commit -m "첫 커밋"
파일 수정
git add 파일명
git commit -m "수정 내용 저장"
여기서 Remove the file 은 파일을 더 이상 Git이 추적하지 않게 만드는 상황을 의미할 수 있다. 예를 들어 추적 중인 파일을 삭제하고 그 변경을 커밋하면, Git은 해당 파일이 제거되었다는 사실을 이력에 기록한다. 반대로 새 파일을 git add 했다가 다시 스테이징에서 내리거나 추적 대상에서 제외하면, 새 파일은 다시 Untracked 상태로 돌아갈 수 있다.
중요한 점은 Git이 파일을 자동으로 무조건 저장하지 않는다는 것이다. 파일을 수정하면 Modified 상태가 되고, 그 변경을 커밋에 포함하려면 사용자가 직접 git add로 Staged 상태로 만들어야 한다. 그리고 git commit을 해야 비로소 Git의 이력에 저장된다.
결국 Git의 파일 상태 변화는 “작업한 내용을 바로 저장하는 방식”이 아니라, 사용자가 어떤 변경을 다음 버전으로 남길지 선택하는 구조이다. 이 구조 덕분에 여러 파일을 수정했더라도 필요한 변경만 골라 커밋할 수 있고, 변경 이력을 더 깔끔하게 관리할 수 있다.

Git 사용자 설정이다. user.name은 커밋 작성자 이름이고, user.email은 커밋 작성자 이메일이다. core.editor vim은 Git이 메시지를 입력받을 때 사용할 기본 편집기를 vim으로 설정한 것이다. init.defaultBranch heesu는 앞으로 git init으로 새 저장소를 만들 때 기본 브랜치 이름을 heesu로 하겠다는 뜻이다.

Git 저장소 안에서 파일 상태를 확인하고, 새 파일을 Git 관리 대상으로 추가하였다. README.md가 처음에는 Untracked 상태였고, git add README.md 후에는 커밋 준비 상태인 Staged 상태가 된 화면이다.

git commit -a -m 'first commit w12'로 .gitignore와 README.md를 커밋했고, 이후 git status에서 working tree clean이 나와 더 이상 저장할 변경사항이 없다는 화면이다.

echo 로 second line을 추가하니 modified: README.md가 뜬다. git diff로 바뀐 상태를 확인하는 연습을 했다.

git commit이후에 git log에서 자세한 설명을 확인했다.

commit 이후엔 second line이 추가된 README.md 가 원본이 되었다.

checkout으로 입력하니 second line이 사라졌다. 그후 switch로 다시 second line이 돌아온것을 확인할수있다.





