Data Modeling, 5 steps Database Design Phase and Physical database design

데이터모델링, 데이터베이스 설계 5단계, 물리적 데이터베이스 설계
Contents
1️⃣데이터 모델링의 개요(Introduction of Data Modeling)
2️⃣데이터 모델링의 단계 (Stages of Data Modeling)
3️⃣데이터베이스 설계 5단계 (5 steps to database design)
4️⃣ 물리적 데이터베이스 설계 (Physical database design)
1️⃣데이터 모델링의 개요
(Introduction of Data Modeling)
데이터 모델

데이터 모델은 집을 지을 때 설계도가 필요한 것과 같다. 집을 짓기 위해 설계도가 필요하듯, 데이터베이스를 설계할 때도 "데이터 모델"이 필요하다. 예를 들어, 학교 데이터베이스를 설계할 때 어떤 데이터를 저장할 것인가? 어떻게 저장할 것인가?에 대한 답을 데이터 모델이 제시해 준다.
이론적인 설명은 다음과 같다: "데이터 모델은 우리가 관심 있는 현실 세계의 정보를 데이터베이스로 표현하는 과정에서 데이터베이스의 구조를 개념적/논리적으로 나타내기 위해 사용되는 도구이다."
데이터 모델의 역할(Role of Data Model)
데이터 모델은 데이터베이스 설계에서 중요한 역할을 한다. 다음은 데이터 모델링의 개요와 그 역할이다.
✅ 시스템을 현재 또는 원하는 모습으로 가시화(visualize)하도록 도와준다.
(Helps visualize the system in its current or desired state.)
- 데이터 모델링은 시스템의 현재 상태 또는 목표로 하는 시스템의 구조를 시각적으로 표현하여 이해하기 쉽게 만들어준다.
✅ 시스템의 구조와 행동을 명세화(specify)할 수 있게 한다.
(Allows specifying the structure and behavior of the system)
데이터 모델은 시스템의 데이터 구조와 그에 따른 동작을 명확히 정의하여 설계 단계에서 발생할 수 있는 혼란을 줄여준다.
생각보다 많은 사람들이 같은 주제이지만 다른 생각을 가지고 있다. 데이터 모델링을 통해 이를 명세화할 수 있게 한다.
✅시스템을 구축하는 틀을 제공한다. (Provides a framework for building the system.)
- 데이터 모델은 데이터베이스 구축을 위한 기본적인 틀을 제공하여 데이터가 어떻게 저장되고 처리될지를 명확히 정한다.
✅ 결정된 것들을 문서화한다. (Documents the decisions made.)
- 데이터 모델링을 통해 결정된 사항들을 문서화하여 프로젝트 진행 중에 참조하거나 유지보수에 활용할 수 있다.
✅ 시스템을 바라보는 다양한 관점을 제공한다.
(Offers different perspectives on the system.)
- 데이터 모델은 시스템을 다양한 관점에서 바라볼 수 있게 해주며, 이를 통해 더 나은 설계를 도출할 수 있게된다.
✅ 특정 목표에 따라 다양한 상세 수준을 제공한다.
(Provides varying levels of detail based on specific goals.)
- 데이터 모델링은 시스템의 목표에 따라 상세한 수준에서부터 개략적인 수준까지 다양한 수준의 모델을 제공한다.
데이터 모델링 정의

데이터 모델링이란 정보시스템을 구축하기 위해 필요한 데이터를 분석하고, 이를 구조적으로 표현하는 과정이다. 데이터 모델링은 데이터베이스를 설계하기 위한 첫 단계로, 시스템에서 다룰 데이터와 정보의 흐름을 정의하는 중요한 작업이다.
데이터 모델링의 필요성
데이터 모델링은 복잡한 현실 세계를 단순화하여 시스템에서 중요한 요소를 식별하고, 이들 간의 관계를 정의하는 과정이다. 이 과정은 다음과 같은 이유로 필수적이다.
✅현실 세계의 복잡성을 단순화
(Simplifying real-world complexity)
- 현실에 존재하는 개체들을 식별(identifies)하고, 개체들 간의 관계를 정의하여 시스템이 현실을 반영할 수 있도록 한다.
✅ 사용자와 데이터베이스 간의 인터페이스 제공
(Providing an interface between users and the database)
- 데이터 모델은 사용자와 데이터베이스 간의 상호작용을 위한 중요한 수단(critical means)이다.
✅ 효율적인 의사소통
(Facilitating efficient communication)
- 프로젝트에 참여하는 분석자, 설계자, 개발자, 사용자 간의 원활하고 효율적인 의사소통을 가능하게 한다.
✅ 신규 또는 개선 시스템 개발의 기초 제공
(Laying the foundation for new or improved system development)
- 데이터 모델링은 새로운 시스템을 개발하거나 기존 시스템을 개선할 때 중요한 기초(fundamental basis)를 제공한다.
💡보통 정보 시스템을 구현할 때 크게 소프트웨어 기능설계(software functionality design), 화면설계(screen (UI) design), 데이터 구조 설계(data structure design)측면으로 나뉘는데 데이터 모델링은 데이터 구조 설계에 해당한다.
2️⃣데이터 모델링의 단계
(Stages of Data Modeling)
데이터 모델링은 크게 3가지로 구분된다. 아래의 과정을 거치면서 상세화 시킨다.
데이터 모델링 종류1 : 개념적 모델링(Conceptual Data Modeling)

업무의 대상이 되는 실제 데이터들의 상관관계를 파악하는 작업이다. 주로 무엇(What)과 같은 큰 덩어리, 주제들의 관계 파악 등에 포커스를 맞춘다. 개념적 모델링에 들어가는 요소로는 개체, 관계, 속성을 식별하고 이들 간의 관련성을 도식화(schematic)한다.
결과물: ERD (Entity Relationship Diagram)

데이터 모델링 종류2: 논리적 모델링(logical modeling)
논리적 모델링은 DBMS의 유형에 맞춰 데이터베이스에 저장될 데이터의 골격(스키마)을 설계하는 작업이다. 주로 데이터를 어떻게(How), 어떤 구조로 저장할 것인가를 작업한다.
DBMS의 유형에 따라 설계가 달라진다. (관계형, 객체지향형, 객체-관계형) 이 유형에 맞추어 논리적 스키마(릴레이션 구조)를 설계하여 데이터베이스의 구조를 구체화하고 데이터의 정규화(normalize)를 수행한다.

결과물: 함수 종속성 파악(Understanding functional dependencies), 논리적(logical) 스키마(릴레이션 구조)
💡데이터의 정규화 (Normalization)는 데이터베이스 설계 과정에서 중요한 개념으로, 데이터의 중복을 줄이고 데이터의 무결성을 유지하기 위해 데이터를 구조적으로 정리하는 과정을 의미한다.
💡함수 종속성(functional dependencies)은 특정 속성의 값이 다른 속성의 값에 따라 결정된다는 것을 의미한다. 예를 들어, 학생 데이터베이스에서 학생 ID(StudentID)와 학생 이름(StudentName)이 있다고 가정해 보자. 여기서 학생 ID가 주어지면 학생 이름이 유일하게 결정도니다. 이 경우, 학생 이름은 학생 ID에 함수적으로 종속된다고 말할 수 있다. 이를 기호로 표현하면 StudentID → StudentName으로 나타낼 수 있다.
데이터 모델링 종류3: 물리적 모델링(physical modeling)
물리적 모델링은 데이터베이스 설계의 마지막 단계로, 데이터베이스가 실제로 어떻게 구현될지를 결정한다. 이 단계에서는 다음과 같은 작업을 수행한다.
✅ 특정 DBMS에 의존하는 데이터 형식(Data types specific to a particular DBMS)
- 데이터베이스 관리 시스템(DBMS)에 맞는 데이터 타입을 설정한다. 예를 들어, 정수, 문자열, 날짜 등 데이터의 구체적인 형식을 정의한다.
✅ 각종 제약 조건(Various constraints): 데이터의 무결성을 유지하기 위해 기본 키, 외래 키, 고유 제약조건, 체크 제약조건 등을 설정한다.
✅ 뷰(Views): 데이터베이스에서 사용자에게 필요한 정보를 제공하기 위해, 데이터의 가상 테이블을 정의한다.
✅ 인덱스(Index): 데이터 검색 성능을 향상시키기 위해, 테이블의 특정 열에 대해 인덱스를 생성한다.
결과물(Result of Physical modeling)

위의 결과물을 살펴보면 개체(entities)들은 테이블과 애트리뷰의 columns에 위치해 있고 각 튜플의 이름들의 데이터 타입이 추가되었다.
테이블 정의서(Table Definition Document): 테이블의 구조를 정의하고 각 열의 데이터 타입, 제약 조건 등을 설명한다.
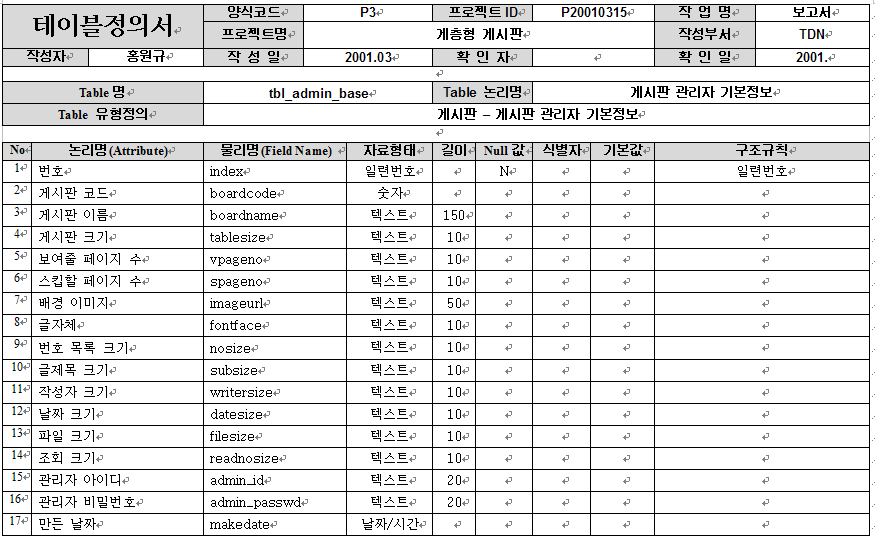
제약 조건 리스트(Constraints List): 데이터 무결성을 보장하기 위해 설정된 제약 조건의 목록을 제공한다.
인덱스 명세서(Index Specification Document): 데이터 검색 성능 향상을 위한 인덱스의 세부 정보를 제공한다.
데이터 모델링 과정(Process of Data modeling)

위의 그림을 설명하자면 데이터 모델링 과정은 다음과 같이 요약할 수 있다.
✅ 현실 세계의 개념 구체화(Conceptualization of Real-World entities)
- 현실 세계에서 존재하는 개념들(예: 학생, 과목, 수강)과 같은 것들을 구체화하는 과정이다. 예를 들어, 쇼핑몰 사이트의 경우, 상품, 상세 정보, 고객, 판매자 정보 및 이들 간의 관계 등을 정의한다.
➡️ 개념적 구조(Conceptual structure): 이 단계에서 현실 세계의 개념과 관계를 이해하고, 이를 개념적 모델로 표현한다.
➡️ 논리적 구조(Logical structure): 개념적 모델을 바탕으로 데이터베이스의 논리적 구조를 설계한다. 데이터의 관계와 구조를 논리적으로 정의하는 과정이다.
➡️ 물리적 데이터베이스 구현(Physical database implementation): 논리적 구조를 기반으로 실제 데이터베이스를 구현한다. 데이터의 저장 형식, 제약 조건, 인덱스 등을 설정한다.
💡 데이터 모델링 과정의 핵심은 현실 세계의 데이터와 물리적 데이터베이스에서 구현된 정보가 일치하도록 하는 것이다. 이 과정을 통해 데이터베이스는 현실 세계의 정보를 정확하게 반영하고, 효율적으로 관리될 수 있게된다.
3️⃣데이터베이스 설계 5단계
(5 steps to database design)
데이터베이스 설계에 대해서 구체적으로 공부해보자
데이터베이스 설계의 정의
데이터베이스 설계는 사용자의 요구사항을 기반으로 그들에게 필요한 정보를 제공할 수 있도록 데이터베이스 구조를 개발하는 과정이다. 데이터 모델링과 거의 동일하지만 몇 가지 차이점이 있다.
데이터 모델링: 데이터 자체를 설계하는 과정에 초점을 맞추며, 데이터의 구조와 관계를 정의한다.
데이터베이스 설계: 완성된 데이터 모델링의 결과를 바탕으로 추가적인 요구사항을 명세화하고, 정리하며 실제 구현까지 포함되는 전 과정을 포함한다. (전 과정이라 함은 개념적 데이터베이스 설계, 논리적 데이터베이스 설계, 그리고 물리적 데이터베이스 설계를 뜻한다. )
실제 업무에서는 "데이터 모델링"과 "데이터베이스 설계"라는 용어가 혼용되어 사용된다.
데이터베이스 설계 시 고려사항
💡 현재 및 미래의 사용자 요구사항을 충족시킬 수 있도록 데이터 지향적 관점(Data-Oriented Perspective)에서 설계해야 한다.
데이터 지향적 관점(Data-Oriented Perspective): 데이터베이스 설계 시에는 데이터가 중심이 되어야 하며, 현재와 미래의 요구사항을 모두 충족하고 향후 변화나 확장에 유연하게 대응할 수 있도록 설계하는 것이 중요하다. 이를 통해 데이터베이스는 시간이 지나면서도 안정적이고 유용하게 운영될 수 있게 된다.

위의 내용은 읽어보면 당연한 것들이지만 설계 시에는 고려해야 한다는 점을 알아두자
데이터베이스 설계 단계
데이터베이스 설계는 다섯 단계로 나누어 진행된다. 이 과정을 통해 요구사항을 만족하는 최적화된 데이터베이스 시스템을 설계하고 구축하게 된다.

✅ 요구 분석 (Requirement Analysis)
사용자, 특히 고객의 요구사항을 분석하고, 데이터베이스가 제공해야 할 기능과 데이터를 정의한다.
결과물: 데이터 요구명세서
✅ 개념적 설계 (Conceptual Design)
데이터베이스에서 다룰 개체와 이들 간의 관계를 정의한다. 데이터 모델링 관계와 같다. 전체적인 데이터의 구조와 관계를 파악하는 단계이다.
결과물: 개체 관계도(ERD, Entity Relationship Diagram)
✅ 논리적 설계 (Logical Design)
개념적 설계를 바탕으로 데이터베이스의 논리적 구조를 설계한다. 쉽게 얘기하면 어떤 구조로 저장할 것인지를 결정(스키마)한다. 여기에는 테이블 구조를 정의하고 함수 종속성을 파악하여 데이터를 정규화/역정규화 하는 작업이 포함된다.
결과물: 함수 종속, 테이블 구조
✅ 물리적 설계 (Physical Design)
논리적 설계를 기반으로 실제 데이터베이스가 지원하는 타입, 저장구조, 인덱스 형식을 가지고 실제 DBMS구현할 수 있도록 설계하는 방식이다. 테이블 최적화, 인덱스 설정 등을 포함합니다.
결과물: 테이블 최적화, 인덱스 설정
✅ 구현 (Implementation)
물리적 설계를 바탕으로 데이터베이스를 실제로 구축한다. DDL(Data Definition Language)을 사용해 데이터베이스 객체를 생성하고, 트랜잭션 작성 등도 이 단계에서 이루어지게된다.
결과물: DDL을 이용한 구현, 트랜잭션 작성
데이터 모델링 vs 데이터베이스 설계
거의 비슷한 의미이나, 데이터 모델링은 개념적/논리적 수준을 말하는 것이 일반적이고 데이터베이스 설계는 시스템 구현에 좀더 가까운 개념으로 사용된다.
데이터 모델링(Data modeling)
개념적, 논리적 수준에서: 현실 세계의 상황을 컴퓨터가 이해할 수 있도록 논리적이고 명확하게 정형화된 방식으로 표현하는 과정이다.
세 가지 단계: 데이터 모델링은 개념적, 논리적, 물리적 데이터 모델링으로 구분된다.
목표: 최적화된 데이터베이스를 구현하기 위한 단계적 실행 절차로 정의된다.
데이터베이스 설계(Database design)
데이터 모델링을 포함: 데이터베이스 설계는 데이터 모델링 과정을 포함하며, 이를 구체화하고 실제 구현까지 이어지는 프로세스를 포함한다.
구체적인 절차: 요구사항 분석, 데이터 구조 설계, 데이터 무결성 및 성능 고려 등 다양한 과정을 통해 데이터베이스를 구축하는 체계적인 절차이다.
데이터베이스 설계 흐름(Database design workflow)

이 다이어그램은 데이터베이스 시스템의 설계 과정을 나타내고 있다. 구조설계와 기능적 요구사항을 기준으로 데이터베이스의 설계가 어떻게 이루어지는지를 보여준다. 각 부분을 살펴보자.
오른쪽 부분: 구조설계
요구사항 수집 및 분석: 사용자와 시스템의 필요를 정의하고, 이를 바탕으로 어떤 데이터가 필요한지를 결정한다.
데이터베이스 요구사항: 어떤 구조로 데이터를 저장할지, 실제 DBMS에서 어떻게 구현할지를 설계한다.
구조적 설계 단계: 데이터 모델 생성(데이터 모델 설계), 논리적 설계(기본 DBMS 데이터 모델 설계)와 물리적 설계(내부 스키마)로 나뉜다.
왼쪽 부분: 데이터의 동작과 처리
기능적 요구사항: 예를 들어 "학생"의 DBMS 설계 시 학생의 결석 여부, 시험 채점 여부 등 데이터 처리에 관한 요구사항이다. 이러한 기능적 요구사항은 데이터의 동작과 처리를 관리한다.
가운데 점선
점선은 논리적 설계를 기준으로, 위쪽은 DBMS에 독립적인 요소들을, 아래쪽은 DBMS에 의존적인 요소들을 나타낸다. 이는 설계가 어떻게 DBMS의 특성에 맞춰져 있어야 하는지를 보여주는 중요한 경계이다.
이 설계 과정을 통해 데이터베이스는 효과적으로 구축되며, 데이터의 저장, 검색 및 관리가 최적화되도록 지원한다.
데이터베이스 설계 1단계: 요구분석단계 #1
(Database Design Phase 1: Requirement Analysis Stage #1
사용자는 주로 구두로 원하는 요구조건을 전달하거나 데이터베이스화를 원하는 자료들을 보여주는 편이다. 이을 수집하고 분석해서 공식적인 요구조건 명세를 생성하는 것(Creating an official requirements specification)이 천번째 과정이다. 반드시 문서화가 되어야 한다. (This must be documented.)
개체, 속성, 관계, 제약조건 등과 같은 정적인 구조에 대한 요구조건 명세 생성 (어떤 데이터를 대략적으로 저장할 것인가? 그들사이엔 무슨 관계가 있는가?)
트랜잭션의 유형, 트랜잭션의 실행 빈도와 같은 동적인 요구조건 명세 생성 (대략적으로 이러한 처리가 이루어진다는 과정을 정리하는 단계)
이 과정에선 기관의 경영 목표 및 정책, 규정과 같은 제약조건이 포함된다.
데이터베이스 설계 1단계: 요구분석단계 #2
(Database Design Phase 2: Requirement Analysis Stage #2)

데이터베이스 설계 2단계: 개념적 설계 단계 #1
(Database Design Phase 2: Conceptual Design Stage #1)

1단계에서 명세된 내용(Specified content)들을 기반으로 가시화(visualize)하는 단계이다. 사용자 및 개발자가 시스템이 다룰 데이터를 직관적으로 이해할 수 있도록 도울 수 있다. 특히 개체, 속성, 관계를 식별 및 결정 단계를 거친다.
개체와 개체 간의 연관성 (학생-과목 간의 관계)말고도 학생이 과목을 몇개까지 할 수 있는지, 과목의 학점만 저장하면 되는지, 중간고사 기말고사의 결과까지 저장해야하는지 등 포함 관계에 중점을 둔다.
트랜잭션을 정의한다는 뜻은 데이터를 조회, 삽입, 수정, 삭제하는 작업을 설명하는 단계이다.
최종적으로 식별된 개체, 속성, 관계를 시각화하여 개체-관계 다이어그램(ERD, Entity-Relationship Diagram)으로 표현한다. 이는 전체 시스템에서 데이터 흐름과 구조를 쉽게 이해할 수 있게 해다. ERD는 개체 간의 관계와 속성을 그래픽적으로 보여주는 대표적인 도구로, 이후 논리적 설계 단계로 이어진다.
데이터베이스 설계 2단계: 개념적 설계 단계 #2
(Database Design Phase 2: Conceptual Design Stage #2)

데이터베이스 설계 2단계: 개념적 설계 단계 #3
(Database Design Phase 2: Conceptual Design Stage #3)

개체: 과목, 학생
관계: 등록
속성: 모든 동그라미
데이터베이스 설계 3단계: 논리적 설계 단계 #1
(Database Design Phase 3: Logical Design Stage #1)

데이터를 특정 목표 DBMS(데이터베이스 관리 시스템)에 어떻게 저장할지를 결정하는 작업이다. 이 단계에서는 선택한 DBMS가 처리할 수 있는 스키마를 생성다. DBMS의 유형에는 관계형, 계층형, 네트워크형, 객체지향형(object-oriented), 객체관계형(object-relational) 등이 포함된다.
특히 관계형 데이터베이스 모델의 경우엔 함수적 종속성 분석(Functional Dependency Analysis)과 테이블 정규화(Normalization)를 통해 중복되는 값이 최소화하도록 테이블 설계, 구조설계를 한다. 이때부터 DBMS의 특성을 많이 고려하게 된다.
💡함수적 종속성 분석(Functional Dependency Analysis) 속성 간의 함수적 종속성을 분석하여 데이터를 효율적으로 저장할 수 있도록 하는것
💡테이블 정규화(Normalization) 정규화 기법(예: 1NF, 2NF, 3NF, BCNF)을 적용하여 데이터 중복을 줄이고 데이터 무결성을 보장하는것. 이를 통해 테이블과 그 관계를 조직한다.
그래서 개체 관계도 트랜잭션 정의서를 기반으로 목표 DBMS 유형에 따라 (논리적 스키마 구조를 만들고 함수적 종속성을 도출하게 된다. ) 이부분은 관계형 모델에서 적용되는 부분이다.
데이터베이스 설계 3단계: 논리적 설계 단계 #2
(Database Design Phase 3: Logical Design Stage #2)

관계형 데이터베이스 설계시 사용되는 논리적 스키마 구조
데이터베이스 설계 4단계: 물리적 설계 단계 #1
(Database Design Phase 4: Physical Design Stage #1)

테이블로 구현하기 직전 단계의 설계모델을 물리적 데이터베이스를 설계한다 라고 한다. 설계시엔 데이터의 저장 구조(테이블)나 접근 경로(인덱스)에 대해서 DBMS가 지원하는 방법 중에서 선택하게 된다. 하드웨어 특성, 운영체제 특성, DBMS특성을 고려해서 물리적 설계를 진행하고 최적화된 내부적 스키마(최적화된 테이블) 결과를 만들어내는 것이 목표이다.
이 과정에선 응답시간, 저장공간, 트랜잭션 처리 성능도 고려해야한다. 레코드의 양식, 순서, 접근경로, 저장공간을 할당하게 된다. 인섹스를 생성하고 성능을 고려하여 역정규화(denormalization)에 대한 결정도 이루어진다. 하지만 기본적으로 데이터베이스 설계시에는 중복을 최소화하는 것을 목표로 진행한다.
💡역정규화(denormalization) 성능 개선을 위해 일부러 데이터 중복을 허용하여 역정규화를 고려하는 것
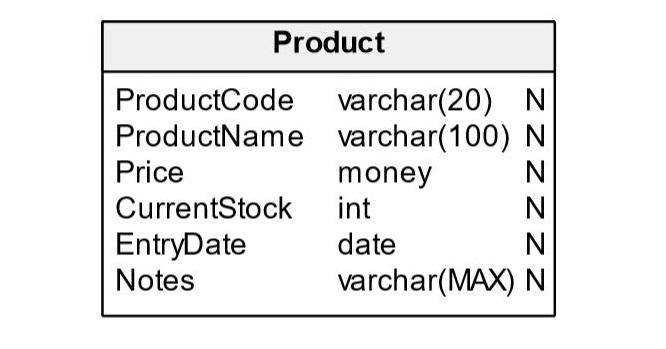
데이터베이스 설계 4단계: 물리적 설계 단계 #2
(Database Design Phase 4: Physical Design Stage #2)

컬럼명이 영문화 되었고 데이터타입은 DBMS가 지원하는 데이터타입, 길이로 정한다.
또한 제약조건인 NULL, UK, PK, FK가 위치해있다.
완성된 테이블 설계로 데이터베이스를 만들수 있게 된다.
데이터베이스 설계 4단계: 물리적 설계 단계 #3
(Database Design Phase 4: Physical Design Stage #3)

Course(과목)테이블 설계 예제
데이터베이스 설계 4단계: 물리적 설계 단계 #4
(Database Design Phase 4: Physical Design Stage #4)

학점의 비고부분은 제약조건으로 구현되게 된다.
데이터베이스 설계 5단계: 데이터베이스 구현 단계 #1
(Database Design Phase 5: Database Implementation Stage #1)

마지막 구현 단계에서는 설계도대로 시공을 진행한다. SQL(DDL, Data Definition Language) 등을 이용하여 DBMS 상에 데이터베이스 스키마 구조 생성하게 된다.
데이터베이스 설계 5단계: 데이터베이스 구현 단계 #2
(Database Design Phase 5: Database Implementation Stage #2)

데이터베이스 설계 5단계: 데이터베이스 구현 단계 #3
(Database Design Phase 5: Database Implementation Stage #3)

오라클에서 실행한 예제이다. 위에 대로 작성하고 실행버튼을 누르면 데이터베이스 내에 테이블이 만들어지게 된다.

데이터를 입력하는 INSERT명령문을 사용하여 한줄 한줄 입력하게 된다.
데이터베이스의 설계 5가지를 전체적으로 공부하였다.
4️⃣ 물리적 데이터베이스 설계
(Physical database design)
물리적 데이터베이스 설계에 대해서 구체적으로 살펴보자. 물리적 데이터베이스 설계의 최종 산출물이라고 할 수 있다. 물리적 데이터모델은 어떤 역할을 할까? 위키디피아에서 정리하는 내용은 아래와 같다.

물리 데이터 모델(또는 데이터베이스 설계)이란, 주어진 데이터베이스 관리 시스템의 기능과 제약을 고려한 데이터 설계의 표현이다.
프로젝트 수명 주기에서, 이는 일반적으로 논리 데이터 모델에서 파생되지만, 주어진 데이터베이스 구현에서 역으로 엔지니어링될 수도 있다.
물리적 데이터베이스 설계 목적
데이터의 저장 구조나 접근 경로에 대해서 DBMS가 지원하는 방법 중에서 선택함
응답시간, 저장공간의 효율화, 트랜잭션 처리도(Throughput) 등을 고려해야 함
효율적, 구현 가능한 물리적 DB 구조 설계하는 것을 목적으로 한다.
효율적이라는 말은 성능을 고려하는 것을 의미한다. 여러개의 디스크에 분산해서 만든다던지, 인덱스를 효율적으로 접근해서 필요한 정보를 빠르게 가져올 수 있게 하는 효율성을 포함한다.
구현 가능한 물리적 DB구조 설계의 뜻은 DBMS상에서 실제로 구현이 가능한 범위내에서 설계를 해야한다는 뜻이다.
물리적 데이터베이스 설계: 수행작업(Task)

수행작업: 저장구조 설계: 데이터베이스가 어떤 구조로 저장될지, 그리고 테이블을 어떻게 분할할지 구체적으로 설계한다.
수행작업: 제약조건 지정: 테이블 정의서에서 나온 데이터타입, 기본키, 기본값, 체크 제약조건, 규칙 등을 지정한다. 이는 데이터 무결성을 보장하기 위한 작업이다.
수행작업: 데이터 집중의 분석 및 설계: 데이터 크기와 물리적 저장 장치의 특성을 분석하여 테이블을 분산시키고 파티셔닝을 설계한다. 작은 테이블은 그대로 진행할 수 있지만, 큰 테이블(예: 상품 판매 데이터)은 한 테이블로 통합할지, 아니면 월별로 테이블을 분리할지 결정하는 단계이다.
수행작업: 접근 경로 설계: 관계형 데이터베이스는 테이블 형태로 데이터를 저장한다. 데이터를 검색하려면 첫 번째 행부터 마지막 행까지 확인해야 하는데, 데이터가 100만 개라면 시간이 많이 걸릴 수 있다. 이를 개선하기 위해 자주 검색되는 데이터(예: 학생 이름)를 미리 인덱스화하여 빠르게 검색할 수 있도록 설계한다. 그러나 모든 컬럼에 인덱스를 설정하는 것은 비효율적이므로, 학점과 같이 값의 범위가 제한적인 경우에는 인덱스가 필요 없다. "뷰 정의"는 사용자에 따라 20개의 컬럼 중 5개 또는 10개의 컬럼만 보여주고 싶을 때 사용하는 가상의 테이블 정의이다.
수행작업: 데이터 처리 설계: 여러 트랜잭션이 동시에 잘 처리될 수 있도록 시스템을 설계하는 작업을 수행한다.
물리적 데이터베이스 설계: 수행작업 - 저장구조 설계 (Task: Design of storage structure)
오라클 데이터베이스의 저장 구조 설계 (Storage Structure Design)에 대해 살펴보자

논리적 저장 구조 (Logical Storage Structure)
테이블스페이스 (Tablespace): 데이터베이스의 논리적 저장 단위이다. 사용자 테이블, 인덱스, 기타 객체들이 테이블스페이스 내에 저장된다. 각 테이블스페이스는 하나 이상의 데이터 파일을 가질 수 있다.
세그먼트 (Segment): 테이블, 인덱스 등 데이터베이스 객체의 물리적 저장 단위이다. 각 세그먼트는 테이블스페이스 내에서 하나 이상의 익스텐트로 구성된다.
익스텐트 (Extent): 세그먼트를 구성하는 연속적인 데이터 블록의 집합이다. 세그먼트가 생성될 때, 초기 익스텐트가 할당된다.
오라클 데이터 블록 (Oracle Data Block): 데이터베이스의 가장 작은 물리적 저장 단위이다. 데이터 블록은 익스텐트 내에서 데이터가 실제로 저장되는 최소 단위이다.
물리적 저장 구조 (Physical Storage Structure)
- 데이터 파일 (Data Files): 실제 데이터는 운영체제의 데이터 파일에 저장된다. 파일 시스템에서 데이터 파일은 데이터베이스의 물리적인 저장 매체이다.
데이터베이스 인스턴스 (Database Instance): 오라클의 데이터베이스이고 데이터를 저장하고 처리할 때는 아래와 같이 구성된다. 각각의 파일들의 역할은 다다르고 내부는 컨트롤 할순 없지만 분산, 구조는 응답시간이 빠르게 동작되도록 설계하여 컨트롤이 가능하다.
데이터 파일 (Data Files): 실제 데이터와 관련된 정보를 저장한다. 데이터 파일은 테이블스페이스 내의 데이터 블록들을 저장한다.
컨트롤 파일 (Control Files): 데이터베이스의 구조와 상태를 추적하고 관리한다. 데이터베이스의 물리적 구조와 로그 파일의 위치 등을 기록한다. 데이터베이스가 정상적으로 작동하도록 돕는 중요한 파일이다.
온라인 리두 로그 (Online Redo Logs): 데이터베이스의 트랜잭션을 기록하는 로그 파일이다. 데이터베이스 복구와 데이터 무결성 유지를 위해 사용된다. 모든 트랜잭션의 변경 사항을 기록하여, 장애 발생 시 데이터 복구를 가능하게 한다.
💡
분산 구조(Distributed Structure)데이터베이스가 여러 서버나 파일에 분산될 수 있다. 이를 통해 성능을 향상시키고 데이터 무결성을 보장한다.💡
구조 설계(Structural Design)데이터베이스 구조는 성능 최적화를 위해 설계된다. 데이터 액세스 시간, 응답 시간 등을 최소화하기 위해 데이터 파일, 세그먼트, 익스텐트, 데이터 블록 등을 적절히 구성한다.
물리적 데이터베이스 설계:
수행작업 - 제약조건 실행 (Task: Implementation of constraints)

데이터 무결성을 구현하기 위해 제약조건을 실행한다. DBMS가 지원하는 제약조건은 크게 3가지로 구분된다.
개체무결성 제약조건(Entity Integrity Constraint): 기본 키 (Primary Key): 테이블 내의 각 행을 유일하게 식별하는 열 또는 열들의 조합. 기본 키 열에는 NULL 값이 허용되지 않으며, 각 기본 키 값은 테이블 내에서 유일(Unique)해야 한다.
도메인 무결정 제약조건 (Domain Integrity Constraint): 도메인 (Domain): 특정 열에 대해 허용되는 값의 범위나 타입을 정의(Data Type)한다. 특정 조건을 만족하는 값만 허용하도록 제한하는 체크 제약(Check)과 열에 값이 입력되지 않았을 때 기본값을 자동으로 설정하는 기본값 제약(Default)도 포함된다.
참조 무결성 제약조건 (Referential Integrity Constraint): 외래 키 (Foreign Key): 다른 테이블의 기본 키를 참조하여 테이블 간의 관계를 유지한다. 외래 키는 참조되는 기본 키 값과 일치해야 하며, NULL 값이 허용될 수 있다. 이를 통해 데이터의 일관성과 무결성을 보장한다.
💡참조무결성 제약조건(Referential Integrity Constraint) 테이블 간의 관계에서 데이터의 일관성과 무결성을 보장하는 제약 조건이다.
물리적 데이터 설계 방식 이후엔 바로 SQL로 구현하게 된다.
물리적 데이터베이스 설계:
수행작업 - 레코드 집중의 분석과 설계 (Task: Analysis and design of record concentration)

똑같은 판매테이블이 있을 때 한 테이블에 데이터가 몰려있으면 성능이 저하된다. 위의 테이블의 데이터를 가로로 분할하여 (1998, 1999) 이런식으로 연간 데이터를 분산, 파티셔닝해서 저장하였다. 결과로 퍼포먼스가 향상되게 되는데 이런 과정을 레코드 집중의 분석과 설계라고 한다.
물리적 데이터베이스 설계:
수행작업 - 접근 경로 설계 #1 (Task: Design of access paths #1)

인덱스 생성: 총 데이터가 0부터 100만건이 있다고 가정시 위의 구조로 데이터를 만들어 준다. 처음부터 끝까지 찾는 것보다 트리구조로 위에서부터/왼쪽, 오른쪽 이런식으로 찾아가며 범위를 좁혀가는 방식으로 효율성을 높인다.
물리적 데이터베이스 설계:
수행작업 - 접근 경로 설계 #2 (Task: Design of access paths #2)

뷰 정의: 위의 데이터에서 보여주고 싶지 않은 정보들은 빼고 프로그램/사용자가 필요한 정보만을 보여주는 가상의 테이블이다. 성능이나 보안에서 중요한 역할을 한다.
물리적 데이터베이스 설계:
수행작업 - 데이터 처리 설계 #1 (Task: Design of data processing #1)
데이터베이스의 물리적 설계 단계에서 데이터 처리 설계는 시스템의 성능과 안정성을 좌우하는 중요한 요소이다. 여기에는 트랜잭션 구현, 저장 프로시저 구현, 동시성 제어 등이 포함된다.

✅ 트랜잭션 구현: 트랜잭션은 데이터베이스에서 하나의 논리적 작업 단위로 취급되는 일련의 명령어 집합이다. 즉, 여러 개의 명령어를 하나의 단위로 묶어 모두 수행되거나 전혀 수행되지 않도록 처리한다. 이는 데이터의 일관성과 무결성을 유지하는 데 필수적이다.
✅ 저장프로시져 구현: 데이터베이스에 미리 컴파일된 SQL 코드 블록으로, 복잡한 작업이나 반복적인 작업을 수행할 때 사용된다. 이는 함수와 유사하지만 더 큰 모듈로 여러 작업을 포함할 수 있다.
✅ 동시성 제어는 여러 사용자가 동시에 데이터베이스에 접근할 때 데이터의 무결성과 일관성을 유지하기 위한 메커니즘이다. 이는 트랜잭션의 격리성을 보장하는 데 중요하다.
물리적 데이터베이스 설계:
수행작업 - 데이터 처리 설계 #2 (Task: Design of data processing #2)

위의 데이터 처리 설계는 트랜잭션, 저장 프로시저, 동시성 제어가 데이터베이스 환경에서 어떻게 구현되는지를 설명하고 있다. 공통적으로 자주 사용하는 사용하는 함수 Stored Procedure를 정해놓고 불러서 사용하여 오류를 줄이고 보안성을 높인다.
학습정리






