Understanding Relational Data Models and RDBMS
관계형 데이터 모델, 1주차 데이터베이스 설계구축

Contents
1️⃣관계형 데이터 모델(Relational Data Model)
2️⃣데이터베이스관리시스템(Database Management System)
3️⃣관계형 DBMS (Relational DBMS)
1️⃣데이터 모델
(Data Model)
데이터 베이스 발전 과정
관계형 데이터 베이스는 “관계형 데이터 모델”을 기반으로 한다. 관계형 데이터모델로 데이터를 저장한다는 뜻인데 아주 쉽게 얘기하면 엑셀, 표의 형태로 데이터베이스를 표현하는 뜻이다.
데이터베이스의 중요성은 60년대 부터 필요성이 대두되기 시작한다. 최초의 컴퓨터 ANIAC이 1946년에 생긴 이후로 초기엔 단순한 계산의 용도로만 사용되었지만 발전되기 시작하면서 데이터를 저장하는 역할이 중요해졌다. 데이터를 함께 모아놓은 뒤 처리해보자는 아이디어가 1963년 6월 제 1차 심포지움에서 ““Development and Management of a Computer-centered Data base” 라는 단어가 처음 등장하였다.

이 후엔 데이터를 어떤 방식으로 묶을지, 저장되는 형식 등의 표준화가 필요해지기 시작했다. 첫 시도는 Navigational DBMS (1960) 였다. 자료구조의 기본 형태인 리스트와 트리, 그래프를 따라 데이터를 저장하는 시도가 시작되었다.

위의 사진처럼 학생과 튜터의 관계인 데이터베이스의 구조를 트리형태로 표현하였다.
Navigational DBMS (1960) 의 문제점으로는 연결 구조를 표현하기엔 쉽지만 정형화된 데이터들, 즉 주소록과 같은 데이터를 처리하기엔 불안정하고 처음부터 일일히 찾아야하 단점이 있었다. 이것을 계기로 데이터를 테이블의 형태로 구조를 다시 정의해보는 시도는 1970년대에서 시작된다. “relational DBMS" (1970)이고 그 후에 SQL이라는 개념이 1970년대 후반에 생겨났다. 관계형 데이터베이스를 조작하기 위한 도구를 SQL이라는 간단하지만 강력한 데이터베이스 전용 언어가 개발되었다. SQL는 단점이 있지만 장점이 더 많다는 특징이 있다. SQL의 단점을 극복하기 위한 대안으로 “object-oriented databases (1980)가 생겨났다. 최근 빅데이터의 등장으로 관계형 데이터가 수용할 수 있는 한계 이상으로 별도의 DBMS 시스템이 생겨났는데 이를 “NoSQL databases (21세기)” 라고 한다. 이는 특정 소프트웨어가 아니고 용도가 다를뿐이다. 업무용으로는 주로 관계형 DBMS가 사용되고 NoSQL database는 대용량 데이터 분석용으로 많이 사용된다.
데이터를 어떤 구조로 표현하고 저장할 것인가? (How to represent and store the data in terms of structure?)
Detail of Data Model - Click here
데이터의 연결, 구성, 구조를 정의하기 위해서는 "데이터 모델" 이 필수적이다. 위에서 언급된 관계형 모델은 가장 유연하고 쿼리 기능이 뛰어나 실제 애플리케이션에서 가장 많이 사용된다. 그 외에도 계층형(Hierarchical), 네트워크형(Network) 모델이 있는데 각각 고유한 특성과 적용 분야를 가지고 있기 때문에 상황에 따라 적절한 모델을 선택해야한다. 데이터 복잡성, 연결, 쿼리 요구사항과 같은 애플리케이션의 특정 요구에 따라 계층형, 네트워크형, 관계형 데이터 모델 중 하나를 선택하게 된다. 여러 부모 연결을 가진 네트워크 모델은 그래프의 구조를 가지고 있는데 기본 트리 구조로 제한되는 계층형 모델보다 더 많은 유연성을 제공하는 특징이 있다. 노드들간에 싸이클이 존재하면 네트워크 데이터 모델이고 계층형은 허용하지 않는다.

관계형(Relational Data Model) 데이터 모델
관계형 데이터 모델은 아주 간단하게 테이블의 형태로 데이터를 표현(저장)한다고 이해하면 쉽다. 대표적인 형식은 엑셀이기 때문에 개념이 그다지 어렵진 않다.

데이터가 추가되면 아래에 한줄이 추가되고, 데이터가 사라지면 한줄이 사라지게 된다.
컬럼(Column)은 도메인이라고도 하는 데이터의 제목이고, 줄(row)은 상세정보를 뜻한다.
관계형(Relational Data Model) 데이터 모델의 특징
1970년 IBM 연구소의 “A Relational Model for Large Shared Data Banks” 라는 논문에서 처음으로 소개되었다. Relational, 관계라고하면 A와 B의 관게라고 생각하기 쉬은데 관계형 데이터 모델에서의 관계란 “테이블의 형태로 데이터를 표현하는 것”(representing data in the form of tables)을 뜻한다. 즉 수학적 릴레이션(Mathematical relation)의 개념을 사용해서 테이블의 형태로 표현한 것이다. 현재 대부분의 상업용 시스템이 지원하고 있다. 오라클, SQL 서버, MySQL, IBM DB2등이 있다.
관계형 데이터 모델 정의

관계형 데이터 모델은 앞서 언급된것 처럼 릴레이션으로 데이터베이스를 표현하고 그 릴레이션의 집합을 모아놓은 것을 “ (관계형) 데이터 베이스”라고 한다.
릴레이션 구조
릴레이션에서 사용하는 용어를 공부해보자

릴레이션 스키마(Relation Schema): 데이터에서 각 하나의 의미를 가지고 있는 부분, 주로 구조를 일컫음
릴레이션(Relation): 구조를 제외한 실제 데이터를 테이블로 저장된 집합을 뜻한다. 릴레이션은 모델링할때 사용하고 실제 구축시에는 “테이블” 이라고 한다.
튜플(Tuple): 릴레이션에서 데이터를 표현하는 것들을 의미함, “로우 (row)”, “레코드 (record)” 라고도 한다.
애트리뷰트(Attribute): 테이블의 각 열을 의미하며, 특정 데이터 항목의 속성을 나타낸다. “컬럼(Column)”이라고도 한다.위의 릴레이션은 7개의 애트리뷰트, 5개의 튜플로 구성되어 있다.
용어 정의


도메인(Domain): 특정 애트리뷰트에 입력될 수 있는 모든 가능한 값들의 집합을 정의한 것이다. 예를 들어, "나이"라는 애트리뷰트의 도메인은 0에서 120 사이의 정수일 수 있고, "성별" 애트리뷰트의 도메인은 "남", "여"와 같은 특정 값으로 제한될 수 있다. 도메인은 데이터 무결성을 유지하는 데 중요한 역할을 한다.
차수(Degree): 위의 관계형 데이터베이스에서 차수는 7이다.
카디날러티(Cardinality): 위의 관계형 데이터베이스에서의 카디날러티는 5이다.
릴레이션의 특징 (관계형 데이터베이스에서의 관계)
집합 이론(Set theory)에 기초한다: 관계형 데이터베이스는 수학적 집합 이론을 바탕으로 설계되어 데이터의 집합을 다루는 방식으로 동작한다. 즉 수학적인 집합의 큰 특징인 중복된 값이 존재하지 않는다는 법칙또한 따른다.
한 릴레이션에 포함된 튜플들은 모두 상이하다(different): 하나의 릴레이션(테이블) 내에서 각 튜플(행)은 고유해야 하며, 중복된 튜플이 존재하지 않습니다.
모든 애트리뷰트 값은 원자값(Atomic value), 단일값이다: 각 애트리뷰트(컬럼)의 값은 더 이상 나눌 수 없는 원자값이어야 합니다. 즉, 각 셀에는 하나의 값만 포함될 수 있습니다. 예를 들면 주소 애트리뷰트에선 “서울” 만 허용하고 “서울, 부산” 은 허용하지 않는다는 뜻이다. 만약 원자값이 아니라면 1)주소 릴레이션을 따로 만든다 2) 주소 애트리뷰트를 추가한다 의 해결책이 있다.
한 릴레이션을 구성하는 튜플과 애트리뷰트 사이에는 순서가 없다: 릴레이션 내의 튜플(행)과 애트리뷰트(컬럼)는 순서가 없으며, 데이터는 순서에 의존하지 않습니다. 집합 이론의 기초에 따른다. 순서는 나중에 임의로 지정해야한다.
2️⃣데이터베이스관리시스템
(Database Management System)
DBMS 정의
이 두 용어는 자주 혼용되지만, 구체적으로는 데이터베이스는 추상적인 데이터 모음을 의미하고, DBMS는 이 데이터를 다루는 소프트웨어를 의미한다는 점에서 차이가 있다. DBMS를 사용함으로써 데이터베이스 내 데이터를 효율적으로 관리하고 활용할 수 있게 된다.
데이터베이스(Database)
정의: 데이터베이스는 단순히 "데이터의 집합"을 의미한다. 이 데이터는 구조화되어 있고, 서로 연관된 정보들로 구성되어 있다. 데이터베이스는 추상적인 개념으로, 컴퓨터 시스템 내에서 정보를 체계적으로 저장하고 관리하기 위한 기본적인 틀이다.
위키피디아 정의: "정보로서 처리되는 구조화된 데이터의 집합"
Elmasri & Navathe 정의: "서로 관련 있는 데이터들의 모임"
예시: 고객 정보, 상품 정보, 주문 정보 등 다양한 데이터를 테이블로 구성한 시스템 내의 정보 모음.
데이터베이스 관리 시스템(DBMS)
정의: DBMS는 데이터베이스를 관리하고 접근할 수 있도록 하는 소프트웨어이다. 데이터베이스 내의 데이터를 삽입, 조회, 수정, 삭제하는 기능을 제공하며, 이를 통해 데이터를 효율적으로 관리하고 사용할 수 있도록 돕는다. 즉, DBMS는 데이터베이스에 대한 인터페이스를 제공하는 구체적인 소프트웨어이다.
역할:
데이터를 저장하고 검색하는 기능 제공
데이터 보안 및 무결성 보장
동시 접근 제어와 데이터 일관성 유지
데이터 백업과 복구 기능 지원
데이터베이스 vs DBMS
- 데이터베이스는 단순히 저장된 데이터 그 자체를 의미하는 반면, DBMS는 이 데이터를 관리하기 위한 소프트웨어이다. 데이터베이스는 데이터를 저장하는 추상적인 개념이라면, DBMS는 그 데이터를 다루는 구체적인 도구라고 볼 수 있다.
DBMS의 예시
Oracle DB: 오라클이 제공하는 상용 DBMS로, 대규모 기업 환경에서 자주 사용된다.
MySQL: 오픈소스 관계형 DBMS로, 웹 애플리케이션이나 소규모 프로젝트에서 자주 사용된다.
PostgreSQL: 고급 기능을 제공하는 오픈소스 DBMS로, 데이터 일관성과 무결성을 중시하는 프로젝트에서 자주 사용된다.
Microsoft SQL Server: 마이크로소프트에서 제공하는 DBMS로, 주로 윈도우 기반 시스템에서 많이 사용된다.
DBMS 역할
DBMS는 데이터를 단순히 모아서 관리하는 것뿐만 아니라 다양한 추가 기능을 제공해 데이터 관리의 효율성과 안전성을 높여준다. 이를 통해 기업이나 조직은 안정적이고 신뢰할 수 있는 데이터 관리 환경을 구축할 수 있게 된다. 주요 기능을 구체적으로 살펴보면 다음과 같다.

✅ 데이터 공유(Data Sharing)
역할: 여러 사용자가 동시에 데이터를 접근하고 수정할 수 있도록 지원한다. 이는 다중 사용자 환경에서 필수적인 기능으로, 동시 접근을 제어하는 동시성 제어(concurrency control)와 관련된다.
- 이점: 여러 사용자가 동시에 작업하더라도 충돌이나 데이터 손실을 방지할 수 있다.
✅ 데이터 무결성 강화(Data Integrity)
역할: 데이터의 정확성, 일관성, 신뢰성을 보장한다다. 이를 위해 제약조건(constraints)을 설정해 데이터가 잘못된 값으로 입력되지 않도록 관리한다다.
예시: 외래 키 제약, 유일성 제약, NOT NULL 제약 등이 있으며, 이를 통해 데이터의 품질을 높인다.
✅ 데이터 표준화(Data Standardization)
역할: 데이터를 일정한 형식과 규칙에 따라 관리함으로써 데이터의 일관성과 호환성을 유지한다. 표준화된 데이터는 서로 다른 시스템 간에 데이터 통합이 쉬워지며, 분석 및 활용이 용이해진다.
이점: 데이터를 일관된 형식으로 저장하여 데이터 품질을 유지하고, 서로 다른 부서나 애플리케이션 간에 데이터를 쉽게 교환할 수 있게된다.
✅ 보안 강화(Data Security)
역할: 민감한 데이터에 대해 접근 권한을 제어하고, 권한이 없는 사용자의 접근을 방지한다. DBMS는 사용자 인증(authentication) 및 권한 부여(authorization)를 통해 데이터를 안전하게 보호할 수 있다.
이점: 데이터에 대한 무단 접근, 손실, 또는 수정으로부터 보호하여 데이터의 기밀성과 무결성을 보장한다.
✅ 프로그램 수정과 유지보수 용이(Program Modification and Maintenance)
역할: DBMS는 데이터와 애플리케이션 프로그램을 분리하여 유지보수를 쉽게 만든다.데이터베이스 설계가 바뀌더라도 애플리케이션에 미치는 영향이 적어, 유지보수가 간편해진다.
이점: 소프트웨어 개발 시 데이터 구조를 변경할 때, 애플리케이션 전체를 수정할 필요 없이 부분적인 수정만으로 작업이 가능하다.
✅ 효율적 데이터 관리(Efficient Data Management)
역할: 데이터를 효율적으로 저장하고 관리할 수 있도록 다양한 최적화 기능을 제공한다. 예를 들어, 인덱스나 파티셔닝을 통해 데이터 접근 속도를 향상시키고, 중복 데이터 관리를 통해 저장 공간을 절약합니다.
이점: 데이터 접근 성능을 높이고, 저장 공간을 절약해 비용 절감과 성능 향상을 동시에 이룰 수 있습니다.
✅ 성능 향상(Performance Improvement)
역할: DBMS는 데이터 처리 속도를 최적화하기 위한 다양한 기법을 지원한다. 인덱스, 캐시, 트랜잭션 관리 등의 기능을 통해 쿼리 처리 성능을 크게 개선할 수 있다.
이점: 대규모 데이터 처리와 복잡한 쿼리 작업을 빠르게 처리할 수 있어 많은 사용자가 동시에 사용해도 오류가 나지 않는다.
DBMS에서 기능적인 측면에서는 정의(definition), 제어(control), 조작(manipulation) 3가지가 있다.
DBMS의 정의(definition) 기능
DBMS의 정의 기능은 데이터베이스의 논리적 구조(logical structure)와 물리적 구조(physical structure)를 정의하고, 이 두 구조 간의 변환을 명확하게 기술하는 중요한 역할을 한다. 쉽게 설명하면 DBMS는 데이터를 저장하고 관리할 때, 데이터를 논리적으로 어떻게 구성할지(논리적 구조), 이를 물리적으로 어떻게 저장할지(물리적 구조), 그리고 이 두 구조를 어떻게 연결할지를 결정하는 중요한 정의 기능을 제공한다. 이 정의 기능을 통해 데이터베이스는 사용자가 데이터를 효율적으로 사용할 수 있게끔 데이터 구조를 설계하고, 물리적 저장 구조와 논리적 구조 간의 변환을 지원한다.
논리적 구조(logical structure)는 데이터가 실제로 저장되는 방식과는 독립적인 추상적인 구조를 말한다. 이는 사용자가 데이터에 접근할 때 보는 방식으로, 데이터 모델을 통해 정의된다. 여기에는 테이블, 열, 행, 데이터 타입, 관계 등이 포함된다.기능: 응용 프로그램들이 필요로 하는 데이터 구조를 지원할 수 있도록 데이터베이스의 논리적 구조를 정의한다. 이를 통해 데이터가 어떻게 논리적으로 연결되고, 관계를 형성하며, 제약 조건이 어떻게 적용되는지를 명확히 설정한다.
예시: 관계형 데이터베이스에서는 테이블 간의 관계를 정의하고, 기본 키, 외래 키 등의 제약조건을 설정하여 데이터 무결성을 보장한다.
물리적 구조(physical structure)는 데이터가 실제로 저장되는 방법과 관련된 부분이다. 물리적 저장 장치에서 데이터가 어떻게 배치되고, 파일 시스템이 어떻게 구성되는지 등을 다룬다.기능: 데이터베이스를 물리적 저장 장치에 어떻게 저장할지를 명세한다. 이는 데이터 접근 성능, 저장 공간 최적화, 백업 및 복구와 같은 물리적 데이터 관리 측면에서 중요한 요소이다. 데이터의 저장 위치, 저장 방식, 인덱싱, 파티셔닝 등의 세부사항을 정의하여 효율적인 데이터 관리를 지원한다.
예시: 특정 데이터가 하드 디스크의 어떤 블록에 저장되는지, 인덱스가 어느 위치에 생성되는지 등을 포함한다.
논리적 구조와 물리적 구조 간의 사상(mapping)기능: 논리적 데이터 구조와 물리적 데이터 구조 사이에서 변환이 가능하도록, 즉 응용 프로그램에서 보는 논리적 데이터 구조와 실제 물리적 저장 구조 사이의 차이를 명확하게 정의한다.
사상(mapping)은 사용자가 데이터베이스의 물리적 저장 방식을 알지 못해도 논리적으로 데이터를 접근할 수 있도록 돕는다. 이 과정에서 DBMS는 데이터를 물리적으로 어떻게 저장할지와 이를 사용자에게 어떻게 보여줄지 간의 변환 작업을 자동으로 처리한다.예시: 응용 프로그램은 논리적 구조인 테이블로 데이터를 접근하지만, 실제로 DBMS는 이 데이터를 물리적 디스크의 특정 위치에서 찾아 제공한다. 이 과정에서 사상(mapping)이 이루어진다.
DBMS의 조작(manipulation) 기능
사용자가 데이터베이스와 데이터를 다루는 핵심적인 역할을 한다. 즉 상호작용할 수 있는 인터페이스를 제공하는 중요한 기능으로, 데이터를 검색, 수정, 삽입, 삭제하는 작업을 지원한다. 이 기능은 사용자가 데이터를 다루기 위한 도구(언어)를 통해 구현되며, 이를 통해 데이터베이스의 데이터를 효과적으로 관리하고 활용할 수 있다.
조작 기능에 대한 상세 설명은 다음과 같다:
✅ 사용자와 데이터베이스 사이의 인터페이스 제공
(Providing an Interface between Users and the Database)
DBMS는 사용자와 데이터베이스 간의 인터페이스 역할을 하여, 사용자가 직접 물리적 데이터를 다루지 않고도 데이터베이스의 데이터를 쉽게 처리할 수 있게 돕는다
이를 위해 SQL(Structured Query Language)과 같은 데이터 조작 언어가 제공된다. SQL은 데이터를 검색하는 SELECT 문, 수정하는 UPDATE 문, 삽입하는 INSERT 문, 삭제하는 DELETE 문 등을 통해 사용자가 데이터에 접근하고 조작할 수 있게 해준다.
✅ 데이터 검색, 수정, 삽입, 삭제 연산 지원
(Operational support on data Retrieval, modification, insertion, deletion)
검색(Retrieval): 데이터베이스에서 특정 조건에 맞는 데이터를 조회할 수 있다.
- 예:
SELECT * FROM Customers WHERE Age > 30;
- 예:
수정(Modification): 기존의 데이터를 변경할 수 있다.
- 예:
UPDATE Customers SET Age = 35 WHERE CustomerID = 1;
- 예:
삽입(Insertion): 새로운 데이터를 추가할 수 있다.
- 예:
INSERT INTO Customers (Name, Age) VALUES ('John Doe', 28);
- 예:
삭제(Deletion): 불필요한 데이터를 삭제할 수 있다.
- 예:
DELETE FROM Customers WHERE CustomerID = 1;
- 예:
✅ 도구(언어)를 통해 구현(Implemented through Tools (Languages))
DBMS는 이러한 데이터 조작 작업을 위한 도구나 언어를 제공한다. 대부분의 DBMS에서 사용되는 도구는 SQL과 같은 데이터 조작 언어(DML, Data Manipulation Language)이다. 이 언어는 사용자가 데이터를 쉽게 조작할 수 있도록 설계되었으며, 명령문을 통해 데이터를 조회, 삽입, 수정, 삭제하는 등의 작업을 수행한다.
SQL 외에도, 일부 DBMS는 사용자 인터페이스(UI)나 애플리케이션 프로그램을 통해 데이터 조작 기능을 제공한다.
✅ 조작 기능의 필수 조건(Essential Requirements for Manipulation Functions)
사용하기 쉬워야 한다: DBMS가 제공하는 데이터 조작 언어는 사용자가 쉽게 배워서 사용할 수 있어야 한다. 직관적인 명령어와 구문으로 설계되어야 하며, 복잡한 연산도 간단한 명령어로 처리할 수 있어야 한다.
- 예: SQL은 사람이 읽고 이해하기 쉬운 자연어와 유사한 문법을 사용하여 데이터베이스와 상호작용하게 한다.
명확하고(Explicit/Clear) 완전해야 한다: 사용자가 요청한 데이터 조작 작업이 명확하게 수행되어야 하며, 데이터의 일관성을 유지해야 한다. 또한, 모든 필요한 데이터 조작 기능을 지원해야 한다.
- 예: 잘못된 명령이 실행되지 않도록 구문 검사를 수행하고, 데이터 무결성을 보장하는 방식으로 조작이 이루어져야 한다.
효율적이어야 한다: 대규모 데이터베이스에서도 빠르고 효율적으로 데이터를 검색, 수정, 삽입, 삭제할 수 있어야 한다. 이를 위해 인덱스, 캐시, 최적화 기법 등을 사용하여 쿼리 성능을 높인다.
DBMS의 제어(Control) 기능
데이터베이스의 정확성, 안전성, 그리고 무결성을 유지하는 역할을 한다. 이를 통해 데이터베이스가 항상 신뢰할 수 있는 상태를 유지하고, 여러 사용자가 동시에 작업을 수행하더라도 데이터가 손상되지 않도록 보장한다. 주요 제어 기능은 다음과 같다.

✅ 데이터 무결성(Data Integrity) 유지
역할: 데이터베이스에서 수행되는 갱신, 삽입, 삭제 작업이 데이터 무결성을 파괴하지 않도록 제어한다. DBMS는 데이터의 일관성을 보장하기 위해 다양한 제약 조건(constraints)을 적용하고, 사용자가 잘못된 데이터를 삽입하거나 수정하지 않도록 막는다.
예시
참조 무결성(Referential Integrity): 외래 키(foreign key) 관계를 통해 관련된 데이터가 항상 일관성을 유지하도록 함.
유일성 제약(Uniqueness Constraint): 특정 열이 중복되지 않도록 하는 제약을 통해 데이터의 유일성을 보장.
체크 제약(Check Constraint): 특정 열의 값이 일정 범위 내에 있도록 제약 조건을 설정.
✅ 보안(Security) 및 권한(Authority) 관리
역할: 데이터베이스 보안은 정당한 사용자만이 허가된 데이터에 접근할 수 있도록 관리하는 기능이다. DBMS는 사용자의 인증(authentication)과 권한 부여(authorization)를 통해 데이터를 보호한다. 특정 사용자 또는 그룹에게 데이터에 대한 접근 권한을 부여하거나 제한할 수 있다.
기능:
사용자가 데이터를 조회, 수정, 삽입, 삭제할 수 있는 권한을 세부적으로 제어.
민감한 데이터는 비인가 사용자가 접근하지 못하도록 보안 계층을 강화.
예시:
- 사용자 A는 고객 데이터에 대한 읽기 권한만, 사용자 B는 고객 데이터를 수정할 수 있는 권한을 가질 수 있음.
✅ 동시성 제어(Concurrency Control)
역할: 여러 사용자가 동시에 데이터베이스에 접근하여 데이터를 처리할 때, 데이터베이스와 처리 결과의 정확성을 유지하는 기능이다. 동시성 제어는 데이터의 충돌을 방지하고, 트랜잭션 간에 일관성을 보장한다.
기능:
잠금(Locking): 여러 트랜잭션이 동일한 데이터를 동시에 수정하려 할 때, 충돌을 방지하기 위해 데이터에 잠금을 설정.
트랜잭션 격리 수준(Isolation Levels): 여러 트랜잭션이 서로 간섭하지 않고 독립적으로 처리될 수 있도록 격리 수준을 설정.
예시: 한 사용자가 데이터를 수정하는 동안 다른 사용자가 동일 데이터를 수정하거나 읽지 못하게 막음으로써 데이터 손상을 방지.
✅ 스키마 관리(Schema Management)
역할: DBMS는 데이터베이스의 논리적 구조와 물리적 구조를 정의하는 스키마를 관리한다. 스키마는 데이터베이스 설계를 기술하는 메타데이터를 포함하며, 이를 유지하고 변경하는 작업이 스키마 관리의 핵심이다.
기능:
새로운 테이블, 인덱스, 관계 등의 데이터 구조를 정의하고 관리.
스키마 변경 시 데이터베이스와 관련된 응용 프로그램이 정상적으로 작동하도록 제어.
✅ 디스크 관리(Disk Management)
역할: DBMS는 데이터를 물리적으로 저장하는 디스크 관리 기능을 제공하여, 데이터가 효율적으로 저장되고 빠르게 접근될 수 있도록 최적화한다.
기능:
데이터 파일의 물리적 배치 최적화.
데이터 압축 및 파티셔닝을 통해 저장 공간을 효율적으로 관리.
읽기/쓰기 성능을 향상시키기 위한 캐싱(caching) 관리.
✅ 백업 및 복구(Backup and Recovery)
역할: DBMS는 데이터 손실이나 시스템 장애에 대비해 데이터베이스를 백업하고, 문제가 발생했을 때 데이터를 복구할 수 있는 기능을 제공한다. 이를 통해 데이터베이스의 안정성과 연속성을 보장한다.
기능:
정기적인 데이터베이스 백업을 통해 데이터 손실 방지.
장애 발생 시 데이터 복구 절차를 통해 데이터베이스를 정상 상태로 되돌림.
예시: 정기적인 스냅샷 백업을 통해 데이터베이스의 특정 시점으로 복구할 수 있음.
✅ 복제(Replication)
역할: 데이터베이스의 복제는 여러 서버에 데이터를 복제하여 데이터의 가용성을 높이고, 시스템 장애 시에도 데이터가 손실되지 않도록 하는 기능이다.
기능:
동일한 데이터가 여러 위치에 복제되어 고가용성(high availability)을 보장.
장애 발생 시 복제본을 사용해 빠르게 시스템을 복구.
DBMS 구조

위 그림은 DBMS(Database Management System)의 전형적인 아키텍처를 보여준다. 이 다이어그램은 다양한 유형의 사용자와 그들이 시스템과 상호작용하는 방법, 그리고 DBMS의 내부 구성 요소 간의 상호 작용을 설명하고 있다. 이를 통해 DBMS가 어떻게 복잡한 데이터베이스 환경을 효율적으로 관리하고, 다양한 요구 사항을 충족시키는지를 알 수 있다. 데이터의 안전성, 접근성 및 정확성을 유지하기 위한 다양한 구성 요소와 그들의 상호작용이 중요하다. 각 요소의 역할과 기능을 간단히 살펴보자.
✅ 사용자(Users)
DBA Staff: 데이터베이스 관리자(Databases Administrators)는 DDL(Data Definition Language) 문을 사용하여 데이터베이스 스키마를 생성하거나 수정한다.
Casual Users: 일반 사용자들은 대화형 쿼리(interactive query)를 통해 데이터베이스에 접근한다.
Application Programmers: 응용 프로그램 개발자들은 응용 프로그램을 작성하여 DBMS와 상호작용한다.
Parametric Users: 특정 매개 변수를 사용하여 프리컴파일된 트랜잭션을 실행하는 사용자들이다.
✅ 컴파일러 및 최적화기(Compilers and Optimizer)
DDL Compiler: DDL 문을 해석하고 처리하여 시스템 카탈로그(system catalog)에 변경 사항을 저장한다.
Query Compiler: 쿼리를 해석하여 실행 가능한 형태로 변환한다.
Query Optimizer: 쿼리 실행 계획을 최적화하여 쿼리의 실행 시간과 자원 사용을 최소화한다.
DML Compiler: 데이터 조작 언어(DML) 문을 컴파일한다.
✅시스템 카탈로그(System Catalog)
- 데이터베이스의 메타데이터를 저장하는 내부 데이터베이스로, 모든 스키마 정보, 테이블, 인덱스, 권한 등을 보관한다.
✅실행 시 데이터베이스 프로세서(Runtime Database Processor)
- 컴파일된 쿼리와 트랜잭션을 실행하여 실제 데이터베이스와 상호작용한다.
✅ 저장 데이터베이스(Stored Database)
- 실제 데이터가 저장되는 영역이다. 여기에는 모든 사용자 데이터와 관련된 정보가 포함된다.
✅ 병행 처리 및 백업/복구 시스템(Concurrency Control and Backup/Recovery Systems)
병행 처리 시스템: 여러 사용자가 동시에 데이터베이스에 접근할 때 발생할 수 있는 충돌을 관리한다.
백업/복구 시스템: 데이터 손실이 발생했을 때 데이터를 복구하고 시스템의 지속성을 보장한다.
✅ 트랜잭션 처리부(Transaction Manager)
- 트랜잭션의 정확성과 격리성을 보장하며, 실행을 관리하고 필요에 따라 롤백이나 커밋을 수행한다.
3️⃣관계형 DBMS
(Relational DBMS)
DBMS 역사
DBMS의 역사는 데이터 관리 방식이 간단한 파일 시스템에서 복잡한 데이터베이스 관리 시스템으로 발전한 과정을 포함한다. 이는 기업 및 조직에서 정보의 중요성과 복잡성이 증가함에 따라 변화해 왔다.
1960년대 이전의 초기 데이터 관리
운영체제 파일 시스템: 초기 컴퓨터 시스템에서는 운영체제가 제공하는 기본 파일 시스템을 통해 데이터를 관리했다. 이 시스템은 간단한 데이터 저장 및 검색 기능을 제공했으며, 주로 단일 프로그램이 데이터를 필요로 할 때 사용되었다.
계층적 및 네트워크 데이터 모델: 이 단계에서는 주로 계층적(Hierarchical) 데이터 모델과 네트워크(Network) 데이터 모델이 사용되었다. 계층적 모델은 데이터를 트리와 같은 구조로 구성하여 관리하는 반면, 네트워크 모델은 보다 복잡한 연결 관계를 가지고 있어 여러 관계를 표현할 수 있다.
1960년대: Navigational DBMS
CODASYL(Conference on Data Systems Languages): 1960년대 중반, CODASYL은 데이터베이스 관리의 새로운 접근 방식을 제안하였다. 이 단체는 네트워크 데이터 모델에 기반한 DBMS의 설계와 구현을 주도했으며, 이를 통해 데이터 항목 간의 다양한 관계를 보다 효과적으로 관리할 수 있게 되었다.
IDS(Integrated Data Store): 이는 CODASYL의 초기 프로젝트 중 하나로, 복잡한 데이터 관계를 효과적으로 관리할 수 있는 시스템의 개념을 소개했다.
IMS(IBM), TOTAL(CINCOM): 이러한 네트워크 기반의 DBMS는 IBM의 IMS(Integrated Management System)와 같은 상업적 제품으로 발전했다. IMS는 특히 대규모 기업 환경에서 광범위하게 사용되어 왔으며, 여전히 중요한 시스템으로 활용되고 있다.
1970년대 초중반: Relational DBMS
1970년대는 데이터베이스 관리 시스템(DBMS) 분야에서 혁명적인 변화의 시기였다. 이 시기에는 E.F. Codd의 이론에 기반한 관계형 데이터베이스 모델이 개발되어, 사용자에게 보다 친숙하고 이해하기 쉬운 데이터 관리 환경을 제공하게 되었다. 이를 통해 데이터베이스 설계와 쿼리 작성 과정이 표준화되면서, 비전문가도 데이터베이스 시스템을 쉽게 이해하고 사용할 수 있게 되었다. 또한, 관계형 데이터베이스는 데이터의 무결성을 유지하고, 복잡한 데이터 관계를 쉽게 관리할 수 있는 강력한 도구를 제공하는 계기가 되었다.
이러한 변화는 기업과 조직에서 데이터 중심 의사 결정을 촉진하는 데 중요한 역할을 했으며, 오늘날에도 여전히 데이터베이스 기술의 핵심으로 남아 있다.
E.F. Codd의 제안: 1970년 E.F. Codd는 IBM에서 근무하며 "A Relational Model of Data for Large Shared Data Banks"라는 논문을 발표했다. 이 논문에서 그는 데이터를 테이블 형태로 조직화하는 관계형 모델을 제안했는데 이 모델은 집합이론과 관계대수를 기반으로 하며, 데이터 항목 간의 관계를 수학적으로 정의하는 방법을 제공했다.
초기 관계형 데이터베이스 시스템 INGRES: 1973년, 캘리포니아 대학교 버클리의 Eugene Wong과 Michael Stonebraker는 INGRES 프로젝트를 시작했다. INGRES는 초기 관계형 데이터베이스 관리 시스템(RDBMS) 중 하나로, 쿼리 언어로 QUEL을 사용했으며 나중에 SQL로 발전했다.
초기 관계형 데이터베이스 시스템 System R: IBM에서 1976년부터 1977년 사이에 개발된 System R은 관계형 데이터베이스 원칙을 실제 시스템에 적용한 첫 번째 상업적 시도 중 하나였다. System R은 SQL(Structured Query Language)을 처음으로 도입했으며, 이는 나중에 데이터 조작의 표준 언어로 자리 잡게 되었다.
1970년대 후반: SQL DBMS
1970년대 후반은 SQL을 중심으로 한 관계형 데이터베이스 관리 시스템(RDBMS)의 발전이 가속화된 시기였다. 이 시기에 몇몇 주요 플레이어들이 시장에 진입하며, SQL 기반의 DBMS 기술이 상업적으로 크게 성공하게 된다. 이는 데이터 관리와 분석을 위한 기반 기술로서의 위치를 공고히 하며, 현대의 데이터 중심 비즈니스 환경에 이르기까지 영향을 미쳤다.
IBM의 System R: IBM의 연구 프로젝트인 System R은 SQL(Structured Query Language)을 처음으로 사용한 시스템 중 하나로, 관계형 데이터 모델을 기반으로 한 실질적인 쿼리 언어의 구현을 제공했다.
SQL/DS: IBM은 System R의 성공을 바탕으로, SQL을 표준 질의 언어로 채택한 첫 번째 상업용 데이터베이스 시스템인 SQL/DS(Data System)를 출시했다. 이는 후에 DB2(Database 2)로 발전하며, IBM의 주요 데이터베이스 제품군이 되었다.
INGRES의 상업화: 버클리 대학교에서 개발된 INGRES는 초기의 관계형 데이터베이스 중 하나로, 원래는 QUEL 쿼리 언어를 사용했으나, 시장의 요구와 경쟁의 압력을 받아 SQL 인터페이스를 갖춘 상용 DBMS 개발로 전환했다. 이로 인해 INGRES는 더 넓은 시장 접근성을 확보할 수 있었다.
Sybase, Informix: INGRES 프로젝트에 참여했던 연구원들이 나가 독립적으로 Sybase와 Informix와 같은 SQL 기반 DBMS를 개발하기 시작했다. 이들 제품은 특히 금융 시장에서 큰 인기를 끌었다.
NonStop SQL: 이는 Tandem Computers가 개발한 것으로, 고가용성과 분산 처리를 목표로 하는 시장에 적합한 DBMS였다.
Microsoft SQL Server의 출시: 이는 Microsoft와 Sybase가 협력하여 개발한 결과물로, 처음에는 Sybase SQL Server로 알려져 있었다. Microsoft는 이 후 Sybase와의 파트너십을 종료하고 독자적인 경로로 SQL Server를 발전시켜 나갔다.
아래에 소개될 두 인물은 데이터 관리와 운영을 혁신하는 데 큰 영향을 미쳤으며, 오늘날에도 기업들과 개발자들에게 중요한 도구로 남아 있다. Larry Ellison과 Michael Stonebraker는 각각의 분야에서 뛰어난 선견지명과 혁신을 보여준 인물로 평가받는다.

Larry Ellison & Oracle: Larry Ellison은 IBM의 System R 프로젝트의 연구 결과에 근거하여 Oracle을 창업했다. System R은 SQL을 사용하는 최초의 프로토타입 관계형 데이터베이스 관리 시스템 중 하나였고, 이 연구는 관계형 데이터베이스의 가능성을 보여주었다. Ellison은 이 아이디어를 상업적으로 활용할 수 있는 기회로 보고, 1977년에 소프트웨어 개발 랩(Software Development Laboratories)을 설립했다. 이 회사는 나중에 Oracle로 이름이 바뀌었고, 1979년 Oracle Version 2를 출시했습니다, 역사적으로 첫 번째 상업용 관계형 데이터베이스 시스템으로 기록된다.

Michael Stonebraker와 INGRES: Michael Stonebraker는 버클리 대학교에서 INGRES 데이터베이스 프로젝트를 진행하며 데이터베이스 기술의 발전에 크게 기여했다.
Postgres와 PostgreSQL의 탄생: Stonebraker는 INGRES 이후에 또 다른 혁신적인 프로젝트인 Postgres를 시작했다. Postgres는 보다 진보된 데이터베이스 시스템 아키텍처를 제안했으며, 이는 SQL을 확장하여 복잡한 데이터 타입을 지원하고, 시스템의 프로그래밍을 용이하게 하는 기능을 포함했다. Postgres 프로젝트는 나중에 오픈 소스 커뮤니티에 의해 PostgreSQL로 발전되었다. PostgreSQL은 오늘날에도 계속해서 발전하고 있는 강력하고 유연한 오픈 소스 관계형 데이터베이스 관리 시스템이다.
1980년대: 객체 지향 데이터 베이스(Object-Oriented Database)
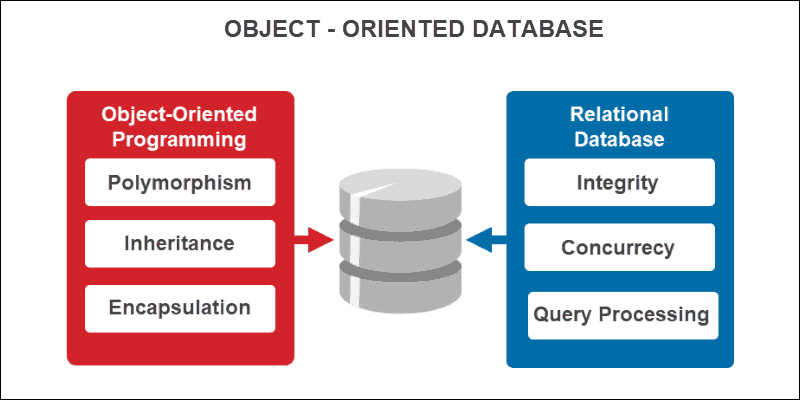
1980년대는 데이터베이스 기술 발전에 있어 중요한 전환점을 맞이한 시기로, 객체 지향 프로그래밍의 부상과 함께 객체 지향 데이터베이스(OODB)가 개발되기 시작했다. 이 시기의 도전과 발전은 데이터 관리 방식에 큰 변화를 가져왔다. 또한 오늘날의 다양한 데이터베이스 기술 통합과 발전의 기반을 마련했습니다.
✅ 객체 지향 데이터베이스의 도입 배경
성능 문제: 1970년대의 컴퓨터 성능과 기술적 한계로 인해, 관계형 데이터베이스의 성능이 종종 비효율적이었다. 특히 복잡한 쿼리가 필요한 대규모 응용 프로그램에서는 그 한계가 두드러졌다.
프로그래밍 패러다임의 변화: 1980년대에 C++과 Java 같은 객체 지향 프로그래밍 언어가 인기를 끌면서, 소프트웨어 개발 패러다임이 객체 지향으로 이동했다. 이로 인해 기존의 관계형 모델과 프로그래밍 모델 사이의 불일치(impedance mismatch) 문제가 부각되었다.
✅ 객체 지향 데이터베이스의 개발과 한계
객체 그대로의 저장: 객체 지향 데이터베이스는 객체를 그대로 저장하고 검색할 수 있도록 설계되었다. 이는 프로그래밍과 데이터 관리 사이의 일관성을 높이고, 개발자가 데이터 구조와 비즈니스 로직을 보다 효과적으로 통합할 수 있게 했다.
기술적 도전과 한계: 초기 OODB 시스템들은 다양한 형태의 데이터를 처리할 수 있는 능력을 가졌지만, 기본적인 데이터베이스 기능과 성능에서는 관계형 DBMS를 따라가지 못했다. 복잡성과 성능 문제로 인해 광범위한 상용화에는 한계가 있었다.
✅ 관계형 DBMS의 지속적인 발전
기능 수용과 발전: 객체 지향 기능의 필요성이 증가함에 따라, 기존의 관계형 DBMS들은 객체 지향적 요소를 통합하는 방향으로 발전했다. SQL의 입지는 더욱 견고해졌으며, 검색 속도를 높이기 위한 인덱스 개념 등이 도입되었다.
현대 데이터베이스의 혼합 모델: 2024년 현재, 관계형 데이터베이스가 여전히 가장 널리 사용되는 데이터 관리 시스템으로 남아 있다. 하지만, NoSQL, NewSQL, 그리고 객체 관계형 매핑(ORM) 기술 같은 현대적 접근 방식이 기존 관계형 모델을 보완하고 있다.
2000년대: NoSQL Database
2000년대는 데이터베이스 기술에서 NoSQL 데이터베이스의 등장으로 큰 변화를 겪은 시기이다. 이 시기에는 인터넷의 대중화와 디지털 데이터 폭발로 인해 기존의 관계형 데이터베이스 시스템으로는 다루기 힘든 새로운 유형의 데이터 요구가 등장했다. NoSQL 데이터베이스는 이러한 요구에 부응하여 개발되었으며, 전통적인 SQL 기반의 관계형 모델의 한계를 극복하고자 했다. NoSQL 데이터베이스는 데이터의 다양성, 규모, 복잡성 증가에 따른 새로운 요구에 효과적으로 대응하면서 데이터 관리 및 분석 기술의 발전에 크게 기여했다.
✅ NoSQL 데이터베이스의 특징과 발전
비정형 데이터 처리(Unstructured Data Processing): NoSQL 데이터베이스는 비정형 데이터(unstructured data) 또는 대용량 데이터의 저장과 처리에 효과적입니다. 이들은 고정된 스키마를 요구하지 않고, 데이터 모델을 유연하게 구성할 수 있다.
확장성(Scalability): NoSQL 데이터베이스는 수평적 확장성(Horizontal Scalability)을 강조한다. 즉, 더 많은 서버를 데이터베이스 시스템에 추가함으로써 성능과 용량을 증가시킬 수 있다. 이는 비즈니스의 성장과 급증하는 데이터 양을 효과적으로 처리할 수 있게 해준다.
다양한 데이터 모델(Various Data Models): NoSQL 데이터베이스는 키-값 저장소(Key-Value Store), 문서 지향 데이터베이스(Document-Oriented Database), 칼럼 기반 저장소(Column-Based Store), 그래프 데이터베이스(Graph Database) 등 다양한 유형을 제공한다. 이를 통해 다양한 응용 프로그램(various application)과 요구 사항에 더욱 적합하게 데이터를 저장하고 관리할 수 있다.
✅ 주요 NoSQL 데이터베이스 시스템
MongoDB: 문서 지향 데이터베이스(Document-Oriented Database)로, JSON과 유사한 형태의 BSON 형식을 사용하여 데이터를 저장한다. MongoDB는 개발자에게 유연한 데이터 모델과 강력한 쿼리 언어를 제공한다.
Redis: 인메모리 키-값 저장소로, 빠른 데이터 처리가 필요한 경우에 사용된다. 캐싱, 메시지 브로커 역할 등 다양한 용도로 활용된다.
Apache Cassandra: 높은 확장성과 신뢰성을 제공하는 칼럼 기반 분산 데이터베이스 시스템이다. 대규모 분산 데이터베이스 요구에 특히 적합하다.
CouchDB: RESTful API를 통해 접근 가능한 문서 지향 데이터베이스이다. 웹 애플리케이션에 특히 유용하다.
HBase: Google의 Bigtable에 영감을 받아 개발된, 칼럼 기반의 분산 데이터베이스 시스템으로, Apache Hadoop 프로젝트의 일부이다.
Firebase: 2011년 스타트업으로 시작하여 2014년에 구글(Google)에 인수되었다.
주로 NoSQL 데이터베이스인 Cloud Firestore와 Firebase Realtime Database를 제공한다. 두 데이터베이스 모두 비정형 데이터를 처리하는데 적합하며, JSON 구조의 데이터로 저장 및 조회가 이루어진다. 모바일 및 웹 애플리케이션 개발자들 사이에서 매우 인기가 높고 특히 스타트업과 소규모 개발팀에게 많이 사용되고 있다.
✅ XML 데이터베이스
- XML 데이터 저장: XML 데이터베이스는 XML 문서를 저장, 검색 및 관리하는 데 특화되어 있다. 이들은 복잡한 데이터 구조를 가진 XML 문서를 효율적으로 처리할 수 있는 쿼리 언어와 인덱싱 메커니즘을 제공한다.
관계형 DBMS의 정의

관계형 DBMS의 종류

관계형 DBMS의 종류 2

관계형 DBMS의 특징
✅ 관계 대수 사용 (SELECT, PROJECT, JOIN 등)
관계형 DBMS는 SELECT, PROJECT, JOIN과 같은 관계 대수(relational algebra)를 사용하여 데이터를 검색하고 조작할 수 있습니다.
SELECT: 특정 조건을 만족하는 행을 반환합니다.
PROJECT: 테이블에서 특정 열만 선택하여 반환합니다.
JOIN: 여러 테이블에서 공통된 값을 기준으로 데이터를 결합합니다.
✅ 모델이 단순하고 모델링이 쉬움
RDBMS는 데이터를 표(테이블) 형태로 관리하므로 구조가 직관적이고 이해하기 쉽다.
테이블 간의 관계는 외래 키(Foreign Key)를 통해 설정된다.
✅ SQL을 사용한 데이터 검색 및 조작
- 관계형 데이터베이스가 사용하는 SQL은 간단한 명령어로 복잡한 데이터 조회, 삽입, 갱신, 삭제 작업을 수행할 수 있다.
✅ 대규모 트랜잭션 처리 및 성능 요구
- 인터넷 환경이 발전하면서, 많은 사용자와 대규모 트랜잭션을 처리하기 위한 성능 향상이 요구되었다.
✅ 장애 복구 기능 (분산 데이터베이스, 미러링, 복제 등):
RDBMS는 데이터를 안정적으로 관리하기 위해 분산 데이터베이스, 미러링, 복제 등의 기능을 제공한다.
분산 데이터베이스는 여러 위치에 데이터를 분산 저장하여 접근성과 성능을 향상시킨다.
미러링과 복제는 시스템 장애 발생 시 데이터를 복구하는 데 사용된다.
오라클(Oracle) 회사 소개


마이크로소프트 SQL server 소개

MySQL & Maria DB 소개

학습정리








