Contents
1️⃣ 전송계층의 위치 (Location of Transport layer)
2️⃣ 프로세스-대-프로세스 통신 (Process-to-Process)
3️⃣ 캡슐화와 역캡슐화
4️⃣ 흐름 제어(Flow Control)
5️⃣ 오류 제어(Error Control)
6️⃣ 오류 제어와 흐름제어의 결합 (Combination of Flow Control and Error Control)
7️⃣ 혼잡 제어 (Congestion Control)
8️⃣ 비연결형과 연결형 서비스 (Connectionless Service and Connection oriented Service)
전송계층의 서비스 Keyword: 흐름제어(Flow Control), 오류 제어(Error Control), 혼잡 제어 - 개방 루프, 폐루프 (Congestion Control - Open loop, Closed loop), 비연결형 서비스(Connectionless Service), 연결형 서비스(Connection-oriented Service), 슬라이딩 윈도우(Sliding windows), 순서번호(Sequence Number), 확인응답(ACK), 패킷 순서 조정 (Reordering of Packets)
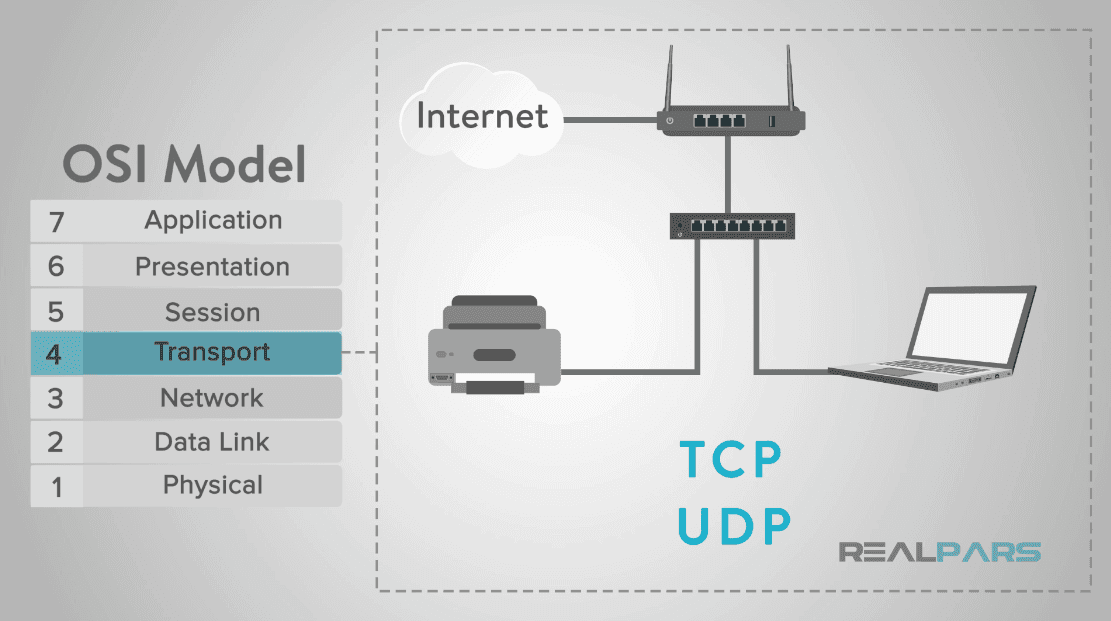
1️⃣전송계층의 위치(Location of Transport layer)

💡요약: 위의 이미지의 빨간 박스로 표시된 부분은 오늘의 주제인 Transport Layer (전송 계층)이다. 이 계층은 데이터가 네트워크를 통해 정확하게 전달될 수 있도록 하는 중요한 역할을 한다. 전송 계층에는 SCTP, TCP, UDP라는 세 가지 주요 프로토콜이 있다.
SCTP: 전화 통신에 사용, 안정적인 전송 보장
TCP: 웹사이트나 이메일 등 신뢰성 필요한 경우 사용
UDP: 비디오 스트리밍, 게임 등 빠른 전송이 필요한 경우 사용
☑️ SCTP (Stream Control Transmission Protocol): 안정적인 데이터 전송을 위해 사용되며, 데이터 손실 방지와 순서 보장이 중요한 애플리케이션에 적합하다. 주로 전화 통신과 같은 실시간 애플리케이션에서 사용된다.
☑️ TCP (Transmission Control Protocol): 신뢰성이 높은 데이터 전송을 제공하며, 데이터가 순서대로 도착하도록 보장한다. 따라서, 웹사이트, 이메일과 같은 정확한 데이터 전송이 필요한 애플리케이션에 주로 사용된다. 만약 전송 중 데이터가 손실되면 재전송 요청을 통해 데이터를 완전하게 전달한다.
☑️ UDP (User Datagram Protocol): TCP와 달리 데이터 전송의 신뢰성보다 속도가 중요한 애플리케이션에 사용된다. 비디오 스트리밍, 온라인 게임과 같이 빠른 데이터 전송이 요구되지만 데이터 일부 손실이 크게 문제가 되지 않는 경우에 사용된다.
전송계층: 프로세스-대-프로세스 통신 (Process-to-Process) #1

💡요약: 네트워크에서 전송 계층이 응용 프로그램 간의 데이터 전송을 담당한다는 점을 보여주고 있다. 데이터를 주고받을 때, 네트워크 계층은 컴퓨터 간의 연결을 담당하고, 전송 계층은 해당 데이터를 특정 응용 프로그램(프로세스)로 보내는 역할을 한다. 결론적으로 네트워크 계층과 전송 계층이 서로 다른 목적을 위해 작동한다는 것을 알아두자.
프로세스 (Process): 실행 중인 응용 프로그램
프로세스-대-프로세스 통신 (Process-to-Process Communication): 서로 다른 컴퓨터의 응용 프로그램들이 네트워크를 통해 통신하는 방식
네트워크 계층은 데이터가 장치까지 이동하는 역할을 하고, 전송 계층은 데이터가 도착한 후에 적절한 응용 프로그램에 전달되도록 한다.
- ☑️ 프로세스 (Process): 컴퓨터에서 실행 중인 특정 응용 프로그램을 의미한다. 예를 들어, 웹 브라우저나 이메일 클라이언트가 프로세스에 해당한다. 이 프로세스는 사용자의 요청을 처리하고, 다른 컴퓨터의 프로세스와 데이터를 주고받는다.
☑️ 프로세스-대-프로세스 통신 (Process-to-Process Communication): 두 장치가 네트워크를 통해 서로 데이터나 메시지를 주고받는 과정을 뜻한다. 여기서 중요한 것은 컴퓨터 간의 통신이 아니라, 각 컴퓨터 내의 응용 프로그램들 간의 통신이라는 점이다. 예를 들어, 사용자가 웹사이트에 접속하면 웹 서버의 프로세스가 웹 브라우저의 프로세스와 통신하여 데이터를 주고받는다.
네트워크 계층과 전송 계층 (Domain of Network-layer Protocol and Domain of Transport-layer Protocol):
Network-layer Protocol은 데이터를 목적지 컴퓨터까지 전달하는 역할을 담당한다. 이때는 IP와 같은 프로토콜을 사용하여 두 장치 간에 데이터를 전송한다.
Transport-layer Protocol은 목적지에 도착한 데이터를 어떤 프로세스로 전달할지 관리한다. 예를 들어, TCP나 UDP가 전송 계층 프로토콜로, 데이터를 특정 응용 프로그램(프로세스)으로 전달하는 역할을 한다.
전송계층: 프로세스-대-프로세스 통신 #2

- 위 예제에서의 포트주소: 13
💡요약: 전송 계층에서는 IP주소, 포트 주소 두가지 정보를 사용하여 데이터를 정확한 서버와 정확한 응용 프로그램(프로세스)으로 전달할수 있게 한다. IP 주소는 네트워크 상에서 장치를 찾는 데 사용되고, 포트 주소는 해당 장치 내의 특정 응용 프로그램을 구분하는 역할을 한다. 이 과정 덕분에, 같은 서버에 있는 여러 응용 프로그램이 서로 충돌하지 않고 데이터 통신을 할 수 있게 된다.
IP 주소: 데이터를 정확한 서버로 보내는 데 사용된다.
포트 주소: 데이터를 정확한 서버 안에서 응용 프로그램 (프로세스)으로 전달하는 데 사용된다.
- ☑️ IP 주소 (IP Address): IP 주소는 네트워크 상에서 특정 장치(서버)의 위치를 나타내는 고유한 주소이. 이미지를 보면, 데이터 패킷 안에 목적지 IP 주소(초록색 박스)가 포함되어 있다. Destination IP address selects the server (목적지 IP 주소는 서버를 선택함)라는 설명처럼, IP 주소를 통해 데이터를 어떤 서버로 보내야 하는지 결정한다.
- ☑️ 포트 주소 (Port Number): 포트 주소는 서버 내에서 특정 응용 프로그램(프로세스)을 식별하는 데 사용된다. 서버에는 여러 응용 프로그램이 동시에 실행될 수 있기 때문에, 포트 주소를 통해 어떤 응용 프로그램으로 데이터를 전달할지 결정한다. 예를 들어, 포트 번호가 "13"인 경우, 전송 계층은 이 포트 번호를 보고 해당 응용 프로그램으로 데이터를 전달하게 된다. Destination port number selects the process (목적지 포트 번호는 프로세스를 선택함) 설명처럼, 포트 주소는 데이터가 도착한 후에 어느 응용 프로그램으로 전달될지 정하는 데 사용된다.
전송계층: 프로세스-대-프로세스 통신 #3
💡요약: 전송 계층이 데이터를 정확한 컴퓨터와 정확한 프로그램으로 전달하기 위해선 아래와 같은 여러 가지 주소 정보를 필요로 한다. 이러한 정보가 있어야만, 통신이 올바른 컴퓨터와 응용 프로그램 간에 이루어지며, 사용자 간의 원활한 데이터 전송이 가능해진다.
프로세스 간 통신을 위해서는 로컬 호스트, 로컬 프로세스, 원격 호스트, 원격 프로세스가 필요하다.
전송 계층의 정확한 통신을 위해 송신자 IP 주소, 송신자 포트 주소, 수신자 IP 주소, 수신자 포트 주소의 4가지 정보가 필요하다.
☑️ 프로세스 간 통신을 위해 필요한 4가지 사항:
로컬 호스트 (Local Host): 통신을 시작하는 컴퓨터. 예를 들어, 내가 사용하는 컴퓨터가 로컬 호스트가 된다.
로컬 프로세스 (Local Process): 로컬 호스트에서 실행 중인 특정 응용 프로그램. 예를 들어, 내가 사용하는 웹 브라우저나 이메일 프로그램 같은 것이다.
원격 호스트 (Remote Host): 통신을 받는 쪽의 컴퓨터이다. 예를 들어, 내가 접속하려는 웹사이트의 서버가 원격 호스트가 된다.
원격 프로세스 (Remote Process): 원격 호스트에서 실행 중인 특정 응용 프로그램이다. 예를 들어, 웹 서버나 이메일 서버 같은 프로그램이 될 수 있다.
☑️ 전송 계층의 서비스를 이용하기 위해 필요한 4가지 주소: 전송 계층에서는 데이터를 정확히 보내고 받기 위해 4가지 주소 정보를 사용한다.
송신자 호스트 IP 주소 (Sender Host IP Address): 데이터를 보내는 장치의 IP 주소
송신자 프로세스 포트 주소 (Sender Process Port Address): 송신자의 특정 응용 프로그램을 식별하는 포트 번호
수신자 호스트 IP 주소 (Receiver Host IP Address): 데이터를 받는 장치의 IP 주소
수신자 프로세스 포트 주소 (Receiver Process Port Address): 수신자의 특정 응용 프로그램을 식별하는 포트 번호
전송계층: 프로세스-대-프로세스 통신 #4
💡요약: 포트 번호는 용도와 목적에 따라 다른 범위로 구분된다.
잘 알려진 포트: 0에서 1,023까지, 웹 서버 등 잘 알려진 서비스용
등록된 포트: 1,024에서 49,151까지, IANA에 등록된 특정 응용 프로그램용
동적 포트: 49,152에서 65,535까지, 임시 또는 개인용 포트
☑️ 잘 알려진 포트 (Well-known Port Number):
범위: 0번 ~ 1023번
주요 용도: 웹 서버, 이메일 서버 등 기본적인 네트워크 서비스에 사용된다.
권한: 일반적으로 관리자 권한이 필수이다.
엄격성: 네트워크 보안과 시스템 안정성을 위해 일반 사용자는 접근할 수 없도록 제한된다.
예시: HTTP(80), HTTPS(443), FTP(21), SMTP(25) 등이 이 범위에 포함된.
☑️ 등록된 포트 (Registered Port):
범위: 1024번 ~ 49151번
주요 용도: 특정 응용 프로그램이나 소프트웨어가 IANA (Internet Assigned Numbers Authority) 기관에 등록하여 사용하는 포트이다. 예를 들어, 데이터베이스, 게임 서버, 특정 응용 프로그램 등
권한: 특정 응용 프로그램이나 소프트웨어에 할당되지만, 관리자 권한 없이도 사용 가능하다.
엄격성: 잘 알려진 포트에 비해 덜 엄격하며, 필요에 따라 다른 포트로 변경할 수도 있다.
예시: MySQL(3306), PostgreSQL(5432), Microsoft SQL Server(1433) 등이 이 범위에 포함된다.
☑️ 동적 포트 (Dynamic Port):
49,152에서 65,535 사이의 포트 번호로, 임시 포트나 개인 포트로 사용다.
네트워크 통신에서 매우 자주 사용된다. 특정한 서비스에 접속할 때 임시로 할당되어 통신이 끝나면 다시 해제된다. 동적 포트는 사용자의 요청마다 새로운 포트를 할당해 사용하기 때문에 웹 브라우징, 이메일 확인, 파일 다운로드 등 일상적인 인터넷 활동에서 매우 빈번하게 사용되고 있다.
전송계층: 캡슐화와 역캡슐화(Encapsulation & Decapsulation)
💡요약: 네트워크 통신에서 데이터를 보내고 받을 때, 캡슐화와 역캡슐화 과정이 필수적이다. 이 과정 덕분에 데이터를 전송하는 동안 안전하게 패킷화하고, 수신 측에서 원본 데이터로 복원하여 정확하게 전달할 수 있게 된다.
캡슐화 (Encapsulation): 클라이언트에서 데이터를 전송할 때, 데이터를 패킷으로 만들기 위해 전송 계층에서 헤더를 추가하는 과정
역캡슐화 (Decapsulation): 서버가 받은 패킷에서 헤더를 제거하여 원본 메시지를 복원하는 과정

☑️ 캡슐화 (Encapsulation):
캡슐화는 데이터를 전송할 때, 데이터에 여러 계층의 헤더 (Header)를 추가하여 패킷으로 만드는 과정을 뜻한다.
이미지의 왼쪽에는 클라이언트 (Client)가 있으며, 여기서 사용자는 Application Layer (응용 계층)에서 데이터를 작성한다. 이 예시에서는 "Payroll"이라는 메시지가 클라이언트의 응용 계층에서 생성되었다.
데이터는 Transport Layer (전송 계층)로 전달되며, 여기에서 전송에 필요한 헤더가 추가된다. 이렇게 헤더가 추가된 데이터는 패킷 (Packet)이 되어 전송 준비를 마친다.
Logical Channel (논리적 채널)을 통해 이 패킷이 서버로 전송되게 된다.
☑️ 역캡슐화 (Decapsulation):
데이터가 서버에 도착하면, 서버 측에서 역캡슐화 과정을 거쳐 데이터의 헤더를 하나씩 제거하고 원본 메시지를 복원한다.
전송 계층에서 헤더가 제거된 후, 응용 계층으로 전달되어 "Payroll" 메시지가 서버의 Application Layer에 도착한다.
이로써, 서버는 클라이언트가 보낸 메시지를 이해하고 처리할 수 있게 된다.
전송계층: 흐름 제어(Flow Control) #1
💡요약: 흐름 제어는 정보 생산자와 소비자 간의 데이터 전송 속도를 조절하여 시스템의 효율성을 높이고, 데이터 손실을 방지하기 위한 방법이다. 밀기와 끌기 방식이 각각 다른 상황에서 유용하게 사용된다.
밀기 (Pushing): 소비자의 요구 없이 데이터를 전달, 필요에 따라 전송 중단이나 재개 요청. 실시간으로 빠르게 전달해야 하는 데이터에 적합. 주로 스트리밍, 실시간 알림, 계속 생성되는 데이터에 사용
끌기 (Pulling): 요청이 있을 때만 데이터를 보내야 효율적인 경우에 적합. 웹 브라우징, 주기적 업데이트 확인, 데이터베이스 조회 등에 사용
☑️ 정보 생성률과 소비율의 균형 (Balance of Production and Consumption Rate):
흐름제어에선 정보 생산자와 소비자 간에 정보 생성률과 소비율의 균형이 중요하다.. 즉, 데이터를 만들어 내는 쪽(생산자)과 그 데이터를 받아들이는 쪽(소비자)의 속도가 맞아야 한다.
균형이 맞지 않으면 데이터가 너무 빨리 전송되어 손실이 발생하거나, 시스템에 과부하가 걸려 효율성이 떨어질 수 있다.
예를 들어, 정보 생산자가 물 공급원이고 소비자가 양동이라고 하면 흐름제어는 물이 넘치지 않도록 조절하는 과정이다. 물의 양이 너무 많으면 양동이가 넘치고, 너무 적으면 양동이를 채우는 데 오랜 시간이 걸리기 때문이다.

정보 전달 방법:
☑️ 밀기 (Pushing):
생산자가 소비자의 요구 없이 데이터를 전달하는 방식이다.
이 경우, 소비자가 데이터를 처리할 수 없을 때는 전송 중단이나 재개 요청을 통해 조절할 수 있다.
예를 들어, 유튜브와 같은 스트리밍 서비스는 사용자가 영상을 보기 시작할 때 미리 데이터를 보내기 시작한다. 만약 네트워크가 느려서 사용자 기기가 데이터를 빠르게 처리하지 못하면 일시적으로 버퍼링이 발생하고, 데이터 전송이 잠시 중단될 수 있다. 또한 메신저 알림, 이메일 알림, 주식 시장 데이터, 날씨 업데이트 등도 이에 해당한다.
☑️ 끌기 (Pulling):
소비자가 데이터를 요청(Request)할 때만 생산자가 데이터를 전달(Deliver)하는 방식이다.
소비자가 필요할 때만 데이터를 받아 처리하므로, 불필요한 데이터 전송이 줄어들고 효율성이 높아지게 된다. 예를 들어, 웹 브라우저에서 사용자가 특정 웹 페이지를 요청할 때 서버가 해당 데이터를 보내는 것이 끌기에 해당한다.
예를 들어, 웹 브라우저에서 사용자가 특정 웹 페이지를 클릭하면, 서버에 해당 페이지의 데이터를 요청하게 된다. 서버는 요청이 있을 때만 데이터를 보내고, 요청이 없으면 데이터 전송을 멈춘다. 또한 데이터베이스 쿼리, 소프트웨어 업데이트 확인, API를 통한 데이터 수집등이 이에 해당한다.
전송계층: 흐름 제어(Flow Control) #2
💡요약: 흐름 제어가 어떻게 이루어지는지 알아보자. 흐름제어는 송신과 수신 간의 데이터 균형을 유지하기 위해 필요하다. 버퍼를 활용하여 송신 속도와 수신 속도를 맞추고, 데이터 손실이나 과부하를 방지할 수 있다.
엔터티 (Entity): 정보의 생산자와 소비자 역할을 동시에 할 수 있다.
버퍼 (Buffer): 송신과 수신 사이의 데이터 흐름을 제어하는 데 사용되는 임시 저장 공간이다.
흐름 제어 방식: 수신 측의 버퍼가 꽉 차면 송신 측에 전송을 멈추라고 요청하고, 여유가 생기면 다시 전송을 요청한다.
☑️ 엔터티 (Entity):
- 하나의 엔터티가 정보의 생산자이면서 동시에 소비자일 수 있음을 의미한다. 예를 들어, 컴퓨터 A와 컴퓨터 B가 서로 데이터를 주고받을 때, 컴퓨터 A가 데이터를 보낼 때는 생산자가 되고, 받을 때는 소비자가 되는 것과 같은 맥락이다.
☑️ 버퍼 (Buffer):
네트워크 상의 흐름 제어는 송신 전송 계층과 수신 전송 계층에 구현된 버퍼를 이용하여 수행됨을 설명한다.
버퍼는 데이터를 일시적으로 저장하는 공간으로, 수신 측의 전송 계층에 위치하고 있다. 송신 측에서 데이터가 빠르게 전송될 때, 수신 측이 그 데이터를 처리할 수 없으면 버퍼에 임시로 저장하여 데이터 손실을 방지한다.
☑️ 수신 버퍼의 공간 부족 시 흐름 제어:
수신 버퍼에 빈 공간이 없으면 송신 측에 요청하여 전송을 중단한다.
수신 측의 버퍼가 꽉 차면, 수신 측은 송신 측에 전송을 잠시 멈추라고 요청한다. 이후 버퍼에 여유 공간이 생기면 다시 송신 측에 전송을 재개하라고 요청하여 데이터 흐름을 조절할 수 있다.
💡 예시: 동영상 스트리밍을 할 때, 동영상 데이터를 수신 측 장치가 빠르게 처리하지 못하면 버퍼에 저장된다. 만약 버퍼가 꽉 차면, 재생 중 잠시 버퍼링이 발생하여 송신 측에 전송을 멈추게 한다. 이후 버퍼에 여유 공간이 생기면 다시 전송을 시작하여 끊김 없이 동영상을 재생하게 된다.
전송계층: 흐름 제어(Flow Control) #3
💡요약: 흐름 제어가 어떻게 이루어지는지 더 자세히 알아보자. 아래 사진은 전송 계층에서 송신 측과 수신 측이 어떻게 데이터를 주고받고, 흐름 제어를 통해 전송 속도를 조절하는지를 설명하고 있다. 송신 측은 데이터를 수신 측으로 밀어서(push) 보내며, 수신 측은 필요에 따라 데이터를 요청해서(pull) 받는다. 이 과정에서 흐름 제어가 중요하게 작용하는 것이다.
송신 측 (Sender): 응용 계층에서 메시지를 만들어 전송 계층으로 보내며, 패킷이 수신 측으로 전달된다.
수신 측 (Receiver): 수신 측 전송 계층에서 데이터를 받아 응용 계층으로 전달하며, 필요할 때만 데이터를 요청한다.
흐름 제어 (Flow Control): 수신 측이 송신 측에 데이터 전송 속도를 조절하도록 요청하여 데이터가 손실 없이 원활하게 전달되도록 한다.

송신 측 (Sender):
Application Layer (응용 계층): 여기에서 송신 측의 Producer가 메시지를 만들어 Transport Layer (전송 계층)의 Consumer에게 전달한다. 이 과정은 Messages are pushed (메시지가 밀려서 전달됨)이라고 표현되었다.
Transport Layer (전송 계층): 전송 계층의 Producer는 데이터를 패킷으로 만들어 수신 측으로 보낸다. 이를 Packets are pushed (패킷이 밀려서 전달됨)라고 한다.
수신 측 (Receiver):
Transport Layer (전송 계층): 수신 측의 Consumer는 송신 측에서 보내온 패킷을 받아 처리한다.
Application Layer (응용 계층): 수신 측의 Consumer는 데이터를 필요로 할 때 Requests (요청)을 보내고, 송신 측에서 메시지를 받는다. 이 과정을 Messages are pulled (메시지가 당겨서 전달됨)이라고 한다.
흐름 제어 (Flow Control):
송신 측과 수신 측 사이의 데이터 전송 속도를 조절하기 위해 Flow Control (흐름 제어)가 이루어진다.
송신 측의 데이터 전송 속도가 너무 빠르면 수신 측에서 감당하지 못할 수 있다. 이때 수신 측은 송신 측에 흐름 제어 요청을 보내어 전송을 조절하게 한다.
💡예시: 이메일을 전송할 때, 송신(Sender) 측 컴퓨터는 이메일 데이터를 패킷으로 만들어 서버로 전송한다. 수신 측 이메일 서버는 수신자의 속도에 맞게 데이터를 수신한다. 만약 수신 측의 데이터 처리 속도가 느려지면, 송신 측에 전송을 잠시 멈추라고 요청하는 흐름 제어가 이루어진다. 이를 통해 데이터가 손실 없이 도착하고, 이메일이 올바르게 수신된다.
전송계층: 오류 제어(Error Control) #1
💡요약: 전송 계층의 오류 제어 (Error Control in the Transport Layer)에 대해 알아보자. 오류 제어는 네트워크 통신에서 데이터의 신뢰성을 보장하기 위한 중요한 과정이다. 오류 제어를 통해 손상되거나 잘못 전달된 데이터 패킷을 감지하고, 이를 재전송하여 데이터가 올바르게 전달되도록 한다.
훼손된 패킷 감지: 전송 도중 손상된 패킷을 감지하고 폐기한다.
재전송 요청: 누락되거나 손상된 패킷을 송신 측에 다시 요청한다.
중복 패킷 폐기: 동일한 패킷이 두 번 이상 도착하면 삭제한다.
패킷 순서 조정: 뒤섞인 패킷을 순서대로 재배치하여 데이터를 올바르게 복원한다.
☑️ 훼손된 패킷 감지 및 폐기 (Detect and Discard Corrupted Packets):
- 신뢰성을 제공하기 위해 훼손된 패킷을 감지하고 폐기한다. 전송 도중 데이터 패킷이 손상되면, 수신 측에서 이를 감지하고 폐기하여 잘못된 데이터가 전달되지 않도록 한다.
☑️ 재전송 요청 (Request for Retransmission):
- 폐기된 패킷은 송신 측에 재전송 요청을 보낸다. 손상된 패킷이나 누락된 패킷이 있을 경우, 수신 측은 송신 측에 해당 패킷을 다시 보내 달라고 요청하여 올바른 데이터가 도착할 수 있도록 한다.
☑️ 중복 패킷 확인 및 폐기 (Identify and Discard Duplicate Packets):
- 중복 수신된 패킷은 확인하고 폐기한다. 동일한 패킷이 두 번 이상 도착했을 경우, 수신 측은 중복된 패킷을 삭제하여 데이터 중복을 방지한다.
☑️ 패킷 순서 조정 (Reordering of Packets):
- 폐기된 패킷이 다시 도착할 때까지 순서에 맞춰 패킷을 저장한다. 전송 중 순서가 뒤섞인 패킷들이 있을 경우, 수신 측은 버퍼를 사용하여 패킷을 순서대로 맞춰 원래의 메시지 형태로 복원한다.
💡예시: 이메일을 전송할 때, 데이터 패킷이 전송 중 손상되었거나 일부가 누락될 수 있다. 이 경우, 수신 측은 손상된 패킷을 폐기하고 송신 측에 해당 패킷을 다시 보내 달라고 요청한다. 송신 측은 요청에 따라 손상된 패킷을 다시 전송하며, 수신 측은 모든 패킷이 도착하면 이를 올바른 순서로 정렬하여 이메일을 완전한 형태로 받게 된다.

💡 패킷 순서 조정의 흐름 (Process of Reordering of Packets)
송신 측에서 패킷 전송:
- 송신 측은 데이터를 여러 개의 패킷으로 나누어 전송한다. 이때 각 패킷에는 순서 번호가 붙어 있어서, 수신 측이 이를 기준으로 순서를 맞출 수 있다.
패킷 순서가 뒤섞임:
네트워크를 통해 전송되는 동안, 일부 패킷은 지연되거나 다른 경로로 가면서 순서가 어긋날 수 있다.
예를 들어, 패킷 1, 2, 3이 송신 측에서 보냈지만, 수신 측에 도착하는 순서는 1, 3, 2일 수도 있다.
수신 측에서 패킷 순서 조정:
수신 측의 전송 계층은 패킷을 버퍼 (Buffer)에 저장하며, 도착한 순서가 아닌 원래의 순서대로 재정렬한다.
만약 특정 패킷이 도착하지 않았다면, 그 패킷이 올 때까지 기다리며 나머지 패킷을 순서대로 저장해 둔다.
완전한 데이터로 복원:
- 모든 패킷이 순서에 맞춰 정렬되면, 수신 측은 이를 다시 하나의 완전한 메시지로 조립하여 응용 계층으로 전달한다.
전송계층: 오류 제어(Error Control) #2
💡요약: 오류 제어 (Error Control)를 실행하기 위한 두 가지 중요한 개념, 즉 순서번호 (Sequence Number)와 확인응답 (ACK, Acknowledgment)에 대해 알아보자 이 둘을 통해 송신 측과 수신 측은 데이터의 정확성을 확인하고, 필요한 경우 데이터를 다시 요청하여 신뢰성 있는 통신을 유지할 수 있게 된다.
순서번호 (Sequence Number): 패킷의 순서를 확인하고 중복이나 누락을 방지하기 위해 각 패킷에 부여되는 번호이다.
확인응답 (ACK): 수신 측에서 송신 측으로 데이터가 제대로 도착했는지 알리는 신호로, 긍정(ACK) 또는 부정(NACK) 응답을 통해 데이터 전송 상태를 전달한다.
☑️ 순서번호 (Sequence Number):
용도: 순서번호는 어떤 패킷을 재전송해야 하는지, 어떤 패킷이 중복되었는지, 또는 어떤 패킷이 순서에 맞게 도착했는지를 확인하는 데 사용된다.
일련번호: 송신 측에서 전송하는 각 패킷에는 고유의 순서번호가 붙는다. 이를 통해 수신 측은 어떤 패킷이 먼저, 또는 나중에 도착했는지를 파악할 수 있게 된다.
모듈로 연산: 순서번호는 m비트로 표현되며, 2의 m제곱 (2^m)으로 나눈 나머지 값을 사용합니다. 이렇게 하면 순서번호가 고갈되지 않고 반복해서 사용할 수 있다.
☑️ 확인응답 (ACK, Acknowledgment):
긍정 확인응답 (Positive ACK): 수신 측에서 데이터가 제대로 도착했을 때 송신 측에 전송하는 응답이다. 송신 측은 ACK를 받으면 해당 데이터가 올바르게 도착했다고 판단한다.
부정 확인응답 (NACK, Negative ACK): 수신 측에서 데이터에 오류가 있거나 일부 패킷이 손실되었을 때 송신 측에 전송하는 응답이다. 송신 측은 NACK을 받으면 해당 데이터를 다시 전송한다.
💡 예시: 파일을 전송할 때, 파일이 여러 패킷으로 쪼개져 전송된다. 각 패킷에는 순서번호가 붙어서 수신 측에 도착한다.
패킷 1, 2, 3을 보내면 수신 측은 순서번호를 확인하고, 정상적으로 도착한 패킷에 대해 긍정 확인응답 (ACK)을 송신 측에 보낸다.
만약 패킷 2에 오류가 발생해 손상되었거나 도착하지 않았다면, 수신 측은 부정 확인응답 (NACK)을 보내어 송신 측에 해당 패킷을 다시 보내달라고 요청한다.
송신 측은 NACK을 받고, 패킷 2를 다시 전송하여 올바른 데이터가 도착할 수 있게 한다.
모듈로 연산 m = 16일 때, 2^16 = 65536이므로 순서번호의 범위는 0부터 65535까지가 된다. 패킷을 전송할 때 순서번호는 0, 1, 2, ..., 65534, 65535까지 증가하고, 65535 이후에는 다시 0으로 돌아가서 반복된다. 이렇게 하면 송신 측과 수신 측은 일정 범위 내에서 순서번호를 반복해서 사용할 수 있기 때문에 순서번호가 고갈되지 않고 계속해서 사용할 수 있게 된다. 또한 데이터 전송이 계속해서 이루어지더라도, 송신 측과 수신 측이 순서번호를 통해 패킷의 순서를 맞추고, 중복이나 누락을 쉽게 파악할 수 있게 된다.
전송계층: 오류 제어와 흐름 제어의 결합 - 슬라이딩 윈도우#1
💡요약: 슬라이딩 윈도우 (Sliding Window) 기법을 통해 오류 제어와 흐름 제어 (Error Control and Flow Control) 기능을 결합하는 방법을 알아보자 슬라이딩 윈도우는 송신 측과 수신 측이 데이터 패킷을 주고받는 과정에서 효율적이고 신뢰성 있는 통신을 유지하기 위해 사용되는 기법이다.
슬라이딩 윈도우 (Sliding Window): 송신 측과 수신 측이 관심을 가지는 순서번호의 범위를 설정하여, 그 범위 내에서만 패킷을 주고받는 방식이다.
윈도우 이동: 송신 측은 수신 측에서 확인응답을 받을 때마다 윈도우를 이동하여, 새로운 패킷을 보낼 수 있게 된다.
윈도우 크기: 송신 측이 보낼 수 있는 패킷 수를 제한하여 수신 측의 처리 능력에 맞춘 흐름 제어를 수행한다.
☑️ 슬라이딩 윈도우 (Sliding Window)의 개념:
슬라이딩 윈도우는 송신 측과 수신 측이 관심을 갖는 순서번호의 범위를 나타내는 추상적인 개념이다.
윈도우 내 순서번호를 가진 패킷만 유효하게 처리되며, 윈도우 밖의 순서번호를 가진 패킷은 폐기된다. 이는 수신 측에서 잘못된 패킷을 처리하지 않도록 도와준다.
☑️ 윈도우가 이동하는 방식:
송신 측에서 패킷을 전송하면, 수신 측에서 해당 패킷을 성공적으로 수신했다는 확인응답 (ACK)을 보낸다.
수신 측에서 ACK를 받으면, 송신 측은 윈도우를 다음 순서번호로 미끄러지듯 이동시킨다. 이를 통해 송신 측은 새로운 패킷을 보낼 수 있는 범위를 확보하게 된다.
윈도우는 송신 측이 동시에 전송할 수 있는 패킷의 수를 제한하는 역할도 하여 흐름 제어를 수행한다.
☑️ 윈도우의 크기:
- 윈도우 크기는 순서번호로 표현할 수 있는 범위보다 작게 설정된다. 이는 송신 측이 너무 많은 패킷을 한꺼번에 보내는 것을 방지하여 수신 측이 데이터 처리에 부담을 느끼지 않도록 돕게한다.
전송계층: 오류 제어와 흐름 제어의 결합
: 선형 형태의 슬라이딩 윈도우 (Linear Sliding Window) #2
💡요약: 슬라이딩 윈도우가 송신 측에서 패킷을 효율적으로 전송하고, 수신 측에서 오류가 없이 데이터를 수신하고 있는지 확인하는 데 어떻게 활용되는지를 예제를 통해 알아본다. 슬라이딩 윈도우 기법을 통해 데이터 전송의 신뢰성과 흐름 제어를 동시에 수행할 수 있게된다.
슬라이딩 윈도우 (Sliding Window): 송신 측이 설정한 범위 내에서만 패킷을 전송하며, 수신 측에서 확인응답(ACK)을 받으면 윈도우가 이동하여 새로운 패킷을 전송할 수 있는 공간이 생긴다.
윈도우가 꽉 찰 때까지 전송: 윈도우 내 패킷이 모두 전송되고 확인응답을 기다리게 되며, 확인응답을 받으면 윈도우가 이동하여 새로운 패킷을 전송할 수 있다.
송신 측에서 전송 가능한 순서번호 범위를 윈도우로 설정한다. 여기서 윈도우 크기는 한 번에 보낼 수 있는 패킷 수를 나타내며, 확인응답을 받으면 윈도우가 오른쪽으로 이동하게 된다.
이미지에서 윈도우 크기는 7개의 패킷(0-6)이다. 즉, 송신 측은 한 번에 최대 7개의 패킷을 전송할 수 있다.

a 단계: 네 개의 패킷 전송 (Four packets have been sent):
송신 측은 패킷 0, 1, 2, 3을 전송한다. 이때 윈도우는 0부터 6까지의 패킷을 포함하고 있다.
아직 수신 측에서 확인응답이 돌아오지 않은 상태이다.
b 단계: 다섯 개의 패킷 전송 (Five packets have been sent):
송신 측은 추가로 패킷 4를 전송하여, 현재까지 총 다섯 개의 패킷이 전송되었다.
윈도우 내에서 전송 가능한 범위 내의 패킷이 전송되고 있는 중이다.
c 단계: 일곱 개의 패킷 전송 및 윈도우가 꽉 참 (Seven packets have been sent, window is full):
송신 측은 패킷 5와 6을 추가로 전송하여, 윈도우 내 모든 패킷(0부터 6까지)을 전송하였다.
이 상태에서 윈도우가 꽉 찼으므로 수신 측에서 확인응답이 오기 전까지 새로운 패킷을 전송할 수 없다.
d 단계: 패킷 0의 확인응답 수신 및 윈도우 이동 (Packet 0 has been acknowledged and window slide):
수신 측에서 패킷 0에 대한 확인응답(ACK)이 도착했다다.
송신 측은 패킷 0이 올바르게 수신되었음을 확인하고, 윈도우를 한 칸 오른쪽으로 이동시킨다. 이제 새로운 패킷(7번)을 전송할 수 있는 공간이 생겼다.
전송 계층: 혼잡 제어(Congestion) 제어 #1
💡요약: 네트워크에서 혼잡은 데이터가 과도하게 몰려 네트워크가 정상적으로 동작하지 못하는 상황을 말한다. 혼잡 제어는 이런 상황을 방지하기 위해 네트워크의 상태를 모니터링하고, 필요한 경우 데이터 전송을 조절하는 기술이다.
네트워크 로드 (Network Load): 네트워크로 전송되는 데이터 양.
네트워크 용량 (Network Capacity): 네트워크가 처리할 수 있는 최대 데이터 양.
혼잡 상황 발생: 네트워크 로드가 용량을 초과하면 혼잡이 발생하여 네트워크 성능이 저하된다.

☑️ 네트워크 로드 (Network Load):
네트워크로 전송되는 패킷의 수를 의미한다. 즉, 네트워크가 한 번에 처리해야 하는 데이터 양이다.
로드가 많을수록 네트워크에 부담이 커지며, 지나치게 많은 데이터가 한꺼번에 전송되면 혼잡이 발생할 수 있다.
☑️네트워크 용량 (Network Capacity):
네트워크에서 처리할 수 있는 패킷의 수를 의미한다. 즉, 네트워크가 원활하게 처리할 수 있는 데이터의 최대 양을 뜻한다.
네트워크 용량은 고정된 값으로, 로드가 용량을 초과할 경우 네트워크가 혼잡해지게 된다.
☑️ 혼잡 상황:
네트워크 로드가 네트워크 용량을 초과할 경우 혼잡 상황이 발생한다.
혼잡이 발생하면 네트워크 속도가 느려지거나, 패킷이 손실될 수 있다. 따라서 혼잡을 방지하기 위해 네트워크 로드를 용량 이하로 유지하는 것이 중요하다.
💡 예시: 고속도로를 생각해 보자
고속도로의 용량은 차량이 원활하게 주행할 수 있는 최대 차량 수이다.
로드는 실제 도로 위에 있는 차량의 수이다.
차량이 너무 많아져 로드가 용량을 초과하면 고속도로는 혼잡하게 되고, 차량의 속도가 느려지며 교통 체증이 발생하게 된다.
이를 방지하기 위해 진입하는 차량 수를 조절하거나 우회로를 안내하는 등의 혼잡 제어가 필요하다.
전송 계층: 혼잡 제어(Congestion) 제어 #2
💡요약: 혼잡 제어를 위해 사전에 방지하는 개방 루프 방식 (Open-loop Congestion Control)과 발생 후에 해결하는 폐 루프 방식(Closed-loop Congestion Control)의 차이를 알아보자. 이 두 가지 방식은 네트워크가 혼잡해지는 것을 예방하거나, 혼잡 상황이 발생했을 때 이를 효과적으로 처리하는 데 중요한 역할을 한다.
개방 루프 (Open-loop) 혼잡 제어: 혼잡을 사전에 방지하는 방법으로, 데이터 전송에 있어 미리 대책을 마련하여 혼잡이 발생하지 않도록 한다.
폐 루프 (Closed-loop) 혼잡 제어: 혼잡 상황이 발생한 후에 이를 완화하기 위한 방법으로, 실시간으로 네트워크 상태를 확인하여 데이터 전송 속도를 조절한다.
☑️ 개방 루프 (Open-loop) 혼잡 제어:
목적: 혼잡 상황이 발생하기 전에 사전적으로 방지하는 것이다.
방법: 데이터를 전송할 때 적절한 재전송 방법을 사용하거나, 슬라이딩 윈도우 정책과 확인응답 정책을 통해 효율적인 데이터 전송을 수행한다. 이로써 네트워크가 과부하에 빠지지 않도록 미리 대책을 마련하는 것이다.
예를 들어, 슬라이딩 윈도우 기법을 사용하여 한 번에 전송할 수 있는 데이터의 양을 조절함 하는 것이 해당한다.
☑️ 폐 루프 (Closed-loop) 혼잡 제어:
목적: 혼잡 상황이 이미 발생한 경우, 이를 완화하는 방법이다.
방법: 네트워크의 상태를 확인하여 윈도우 크기를 조절하는 등 실시간으로 데이터 전송 속도를 변경하여 혼잡 상황을 해결한다. 개방 루프에 비해 더 복잡하기 때문에 구현이 상대적으로 어렵다는 특징이 있다.
예를 들어, 네트워크가 과부하 상태에 들어가면, 데이터 전송 속도를 낮추고 혼잡이 해소되면 속도를 다시 높이는 방식이다.
💡 예시: 개방 루프 혼잡 제어는 위에서 배운 슬라이딩 윈도우가와 확인응답(ACK) 정책을 통해 데이터의 양을 조절하는 방법을 예로 들수 있고 폐 루프 혼잡 제어의 경우는 아래와 같다.
대형 스트리밍 서비스(예: 유튜브)에서 네트워크 트래픽이 갑자기 급증할 때 사용하는 방법이다. 예를 들어, 스트리밍 서비스에서 특정 시간대나 이벤트로 인해 네트워크 트래픽이 급증하여 혼잡이 발생할 경우, 서버는 데이터 전송 속도를 일시적으로 줄인다. 화질을 자동으로 낮추거나, 데이터를 압축해서 보내는 방식으로 혼잡을 줄이는 것이다. 이후 네트워크가 안정화되면 서버는 전송 속도를 다시 높이고 화질을 원래대로 복구하여 사용자 경험을 개선한다. 이처럼 폐 루프 혼잡 제어는 혼잡 상황이 이미 발생한 후에 이를 완화하기 위한 조치로, 실시간으로 네트워크 상태에 따라 전송 속도를 조절하는 방식이다. 참고로 적응형 비트레이트 스트리밍 (Adaptive Bitrate Streaming) 알고리즘이나 대규모 트래픽 모니터링 시스템으로 상황에 맞게 대응한다. 사람이 일일히 하는 것이아님
전송계층: 비연결형과 연결형 서비스 (Connectionless Service & Connection-oriented Service)
💡요약: 네트워크에서 데이터를 전송하는 방식은 비연결형과 연결형으로 나뉘며, 이 두 방식은 데이터 전송 방식, 오류 처리, 연결 관리 측면에서 차이가 있다.
비연결형 서비스 (Connectionless Service): 데이터 패킷을 독립적으로 전송하며, 패킷이 순서 없이 도착해도 관리하지 않는다. 오류 제어나 혼잡 제어에 신경 쓰지 않는다.
연결형 서비스 (Connection-oriented Service): 데이터 전송 전에 연결을 설정하고, 오류 제어와 흐름 제어를 통해 신뢰성 있게 데이터를 전달한다. 데이터 전송이 완료되면 연결을 해제한다.
☑️비연결형 서비스 (Connectionless Service):
데이터를 작은 단위로 나누어 전송한다. 이 단위를 흔히 패킷 (Packet)이라고 한다.
각 패킷은 독립적인 단위로 취급되며, 목적지에 도착하는 순서나 경로가 다를 수 있다.
패킷은 순서 없이 도착할 수 있으며, 도착 순서, 흐름 제어, 오류 제어, 또는 혼잡 제어에 대한 관리가 이루어지지 않는다.
예를 들어, 데이터를 여러 작은 조각으로 나누어 전송하면, 각 조각은 독립적으로 목적지에 도착하여 나중에 하나로 조합되게 된다.
☑️연결형 서비스 (Connection-oriented Service):
데이터 전송을 시작하기 전에 서버와 클라이언트 간에 연결을 설정한다. 이를 통해 양측이 통신할 준비가 되었는지 확인한다.
흐름 제어, 오류 제어, 혼잡 제어 등을 수행하면서 데이터가 신뢰성 있게 전달될 수 있도록 관리하는 것이다.
데이터 교환이 완료되면 연결을 해제하여 더 이상 자원을 사용하지 않도록 한다.
예를 들어, 전화 통화를 생각할 수 있다. 전화 연결을 설정하고 통화가 끝나면 연결을 끊는 것과 비슷하다.
💡 예시: 비연결형 서비스 예제는 이메일이나 우편을 보내는 경우이다. 각 이메일(또는 우편)은 독립적으로 전송되어 도착 순서가 다를 수 있다. 수신자가 여러 개의 이메일을 순서에 상관없이 받고, 나중에 모아서 확인하는 방식이다. 연결형 서비스 예제는 은행에서의 온라인 거래이다. 거래를 시작할 때 먼저 연결을 설정하여 인증과 확인을 거친 후 데이터(거래 정보)를 전송한다. 거래가 완료되면 연결을 종료한다. 이 과정에서 오류나 데이터 누락이 발생하지 않도록 제어한다.
Summary






