Tree in Algorithms (1/2) : Binary search tree, Segment tree
Contents
1️⃣ 트리의 개념과 사례 (Introduction and Example of Tree)
2️⃣ 이진 검색 트리 (Binary Search Tree)
3️⃣ 세그먼트 트리 (Segment Tree)
4️⃣ 레드 블랙 트리 (Red Black Tree) - to be continued in 2nd part
1️⃣ 트리의 개념과 사례 (Introduction and Example of Tree)
💡Keyword: 노드(node), 순환 구조가 아님, 부모-자식 관계, 서브트리 독립적, 의사결정트리, 트리형 네트워크 토폴로지, 파스 트리
트리의 개념⬇️

컴퓨터 공학에서 트리는 “거꾸로 자라는 나무”이다.
트리의 구성요소⬇️
트리는 계층적 구조로, **상위 노드(부모 노드)**와 **하위 노드(자식 노드)**의 관계가 명확하다. 예를 들어, 가족 나무(족보)를 트리로 표현할 수 있다. 조상이 루트 노드, 자녀들이 자식 노드로 표현된다. 이처럼 트리는 계층적 데이터를 관리하고 처리하는 데 매우 유용하며, 파일 시스템이나 데이터베이스에서 많이 사용된다.

노드(Node): 트리의 기본 단위이다. 데이터나 레코드를 저장하는 장소라고 생각할 수 있다. 각 노드는 트리에서 다른 노드들과 연결될 수 있다.
에지(Edge): 노드와 노드를 연결하는 선이다. 이를 통해 노드들 사이의 관계를 나타낼 수 있다.
루트 노드(Root Node): 트리에서 가장 상위에 위치한 노드이다. 이 노드는 부모가 없으며, 트리의 시작점 역할을 한다. 예시에서는 A가 루트 노드이다.
부모 노드(Parent Node): 다른 노드를 가리키는 노드를 부모 노드라고 한다. 즉, 두 노드가 연결되어 있을 때 상위 노드를 부모 노드라고 부른다. 예시에서 A는 B와 C의 부모 노드이다.
자식 노드(Child Node): 부모 노드로부터 연결된 하위 노드를 자식 노드라고 한다. 예시에서 B는 D와 E의 부모이며, D와 E는 자식 노드이다.
리프 노드(Leaf Node): 더 이상 자식 노드가 없는 가장 하위의 노드를 리프 노드라고 한다. 즉, 끝 노드이다. 예시에서 C, D, E는 자식이 없으므로 리프 노드이다.
서브 트리(Subtree): 전체 트리의 부분 집합을 뜻한다. 예시에서는 B와 그 하위 노드들(D와 E)을 서브 트리로 볼 수 있다.
트리의 특징⬇️
💡요약: 트리는 중요한 자료구조로, 계층적 데이터 관리, 효율적인 탐색 및 검색, 데이터 구조 설계 등 다양한 문제를 해결할 수 있다. 트리의 기본 특성인 순환 없음, 부모-자식 관계, 서브 트리의 독립성은 데이터 구조를 설계할 때 매우 중요한 고려사항이다.
순환 구조를 지니고 있지 않음:
트리는 사이클(cycle)을 포함하지 않는 자료구조이다. 즉, 트리의 노드들은 순환 없이 한 방향으로만 연결되어 있다.
트리에는 항상 1개의 루트 노드가 존재하며, 이 노드는 트리의 최상위에 위치해 모든 노드의 시작점이 된다.
트리의 순환이 없는 특성은 그래프 탐색 알고리즘에서 중요한 요소가 될 수 있다. 순환이 있으면 탐색 알고리즘이 무한 루프에 빠질 수 있기 때문에 트리 구조를 사용하는 경우 안정성을 보장할 수 있게 된다.
루트 노드를 제외한 노드는 단 하나의 부모 노드만 가짐:
트리에서 각 노드는 부모 노드로부터 내려오며, 루트 노드를 제외한 모든 노드는 하나의 부모만을 가진다.
노드는 다른 여러 자식 노드를 가질 수 있지만, 반대로 부모는 하나뿐이다.
계층적인 데이터를 나타낼 때 유용하다. 예를 들어, 회사 조직도, 가계도 등에서 계층적으로 표현되는 데이터를 모델링할 때 트리 구조를 사용할 수 있다.
서브 트리(subtree)도 트리의 모든 특징을 따름:
트리의 부분 집합인 서브 트리도 독립적인 트리처럼 동작한다. 즉, 서브 트리도 트리의 모든 규칙과 특성을 그대로 따른다.
예를 들어, 트리의 한 노드와 그 자식 노드들이 함께 서브 트리를 이루며, 그 서브 트리도 부모-자식 관계가 성립한다.
서브 트리는 데이터베이스 인덱스나 이진 검색 트리와 같은 트리 기반 자료구조에서 유용하게 사용된다. 데이터가 추가되거나 삭제될 때 특정 서브 트리만을 갱신하거나 조작할 수 있다.
트리의 사례 - 의사 결정 트리 (Decision Tree) ⬇️
**💡요약:**의사 결정 트리(Decision Tree)는 트리 자료구조를 활용한 기계 학습 알고리즘으로, 분류문제(Classification) 예를 들어 스팸 메일 분류, 질병 진단 등과 회귀문제(Regression) 예를 들어 집값 예측 등을 해결할 때 자주 사용된다. 트리의 각 노드는 특정 조건에 따라 데이터를 분류하는 기준이 되고, 가지(branch)를 따라가면서 최종적인 결정에 도달하는 구조이다.
예를 들어, 고객의 대출 신청을 승인할지 말지를 결정하는 의사 결정 트리를 생각해볼 수 있다. 각 단계에서 조건에 따라 데이터를 분류하며 진행된다.
루트 노드:
"고객의 신용 점수가 700 이상인가?"라는 질문을 한다.
예(Yes)와 아니오(No)로 가지가 나뉜다.
부모 노드 (첫 번째 분기):
신용 점수가 700 이상인 경우, 다음 질문으로 넘어간다: "고객의 소득이 50,000 이상인가?”
신용 점수가 700 미만이면 대출을 거절한다.
자식 노드 (두 번째 분기):
소득이 50,000 이상이면 대출을 승인한다.
소득이 50,000 미만이면 대출을 거절한다.
위의 의사 결정 트리는 각 분기점에서 어떤 기준으로 데이터를 분류했는지 명확하게 보여주기 때문에 해석이 쉽다. 데이터를 여러 번 분할하면서 복잡한 비선형 관계를 다룰 수 있게 된다. 마지막으로 트리 형태로 데이터의 분류 과정을 시각적으로 표현할 수 있어 직관적이다.
트리의 사례 - 트리형 네트워크 토플로지⬇️
**💡요약:**트리의 사례는 네트워크에서도 찾아볼 수 있다. 트리형 토폴로지는 여러 스위치나 허브가 계층적으로 연결된 네트워크이다. 예를 들어, 회사의 네트워크 구성을 트리형 토폴로지로 구성하면 다음과 같은 구조가 될 수 있다.
루트 노드 (Top-level Switch):
- 최상위에는 중앙 스위치가 있다. 이 스위치는 다른 하위 네트워크 장비(예: 하위 스위치, 허브 등)로 연결된다.
부모 노드 (Intermediate Switches):
- 중앙 스위치에서 하위 스위치들이 연결된다. 이 하위 스위치들은 각기 다른 부서나 층에 있는 장비들을 관리한다.
자식 노드 (End Devices):
- 각 스위치에 연결된 장비들이 하위 노드(자식 노드) 역할을 한다. 이 장비들은 실제로 네트워크를 사용하는 컴퓨터, 프린터, 서버 등의 기기들이다.

트리형 토폴로지는 계층적으로 구조를 확장할 수 있다. 각 노드가 자식 노드를 가지기 때문에 대규모 네트워크에 적합하다. 또한 네트워크를 계층적으로 나눌 수 있어 부서별 또는 층별로 네트워크 관리가 용이하다. 단점으로는 최상위 루트 노드(중앙 스위치)가 고장나면 전체 네트워크에 큰 영향을 미칠 수 있다는 점이 있다. 이 방식은 주로 대형 조직이나 학교, 병원 등에서 각 부서나 층별로 네트워크를 나누어 관리하는데 자주 사용한다.
**트리의 사례 - 파스 트리 (Parse Tree)**⬇️
**💡요약:**파스 트리는 프로그래밍 언어의 문법이나 수식을 문법적으로 해석하는데 사용되는 트리 구조로, 코드의 구문 구조를 계층적으로 표현하여 컴파일이나 인터프리팅 과정에서 중요한 역할을 한다.
3 + 5 × 2
이 표현식을 구문 분석하여 파스 트리로 나타내면 다음과 같다.
루트 노드는 연산자로 시작한다. 이 경우, 최종 연산자인
+가 루트 노드가 된다.부모 노드로서
+의 왼쪽과 오른쪽 자식 노드로 각각 숫자 3과 곱셈 연산이 있다.곱셈 연산자
*는 다시 자신의 자식 노드로 숫자 5와 숫자 2를 가진다.

파스 트리는 루트에서부터 처음 시작해 계층적으로 하위 요소를 표현하는 구조이다. 상위 연산자가 하위 연산자나 피연산자들을 포함하고, 이를 기반으로 계산이나 처리가 이루어지기 때문이다. 마지막으로 파스 트리는 컴파일러나 인터프리터에서 코드를 구문 분석할 때 필수적으로 사용된다. 소스 코드를 파싱하여 트리 구조로 변환하고, 이를 바탕으로 프로그램이 올바르게 작성되었는지 검사하거나, 코드를 실행하는 데 필요한 정보를 추출하는 역할을 한다.
트리의 활용 분야 ⬇️
💡요약: 트리 자료구조는 이산적인 분석(Discrete), 컴퓨터 과학, 머신 러닝 등에서 매우 중요한 역할을 하며, 복잡한 문제를 해결하거나 데이터를 효율적으로 탐색하고 분석하는 데 필수적인 도구로 사용되고 있다. ICT(
Information and Communications Technology) 기술의 발전으로 트리의 활용 범위가 계속해서 넓어지고 있다.
이산적인 경우의 수 분석(Analysis of discrete cases)
트리는 경우의 수(Possible case) 를 분석할 때 많이 사용된다. 복잡한 문제에서 모든 가능한 경우의 수를 탐색하거나 분석할 때 트리 구조가 유용하다.
예시: 전기회로망 분석(Electrical circuit analysis), DNA 분석, 분자 구조식 설계(Molecular structure design) 등에서 트리가 다양한 가능성을 효율적으로 탐색하고 분석하는 데 사용된다.
컴퓨터 공학적 분석:
트리는 자료 탐색, 문법 분석, 게임 트리 등 컴퓨터 공학에서 매우 중요한 역할을 한다.
예시:
자료 탐색: 이진 탐색 트리(Binary Search Tree)와 같은 자료구조를 통해 데이터를 빠르게 탐색할 수 있다.
문법의 파싱: 프로그래밍 언어에서 코드를 분석할 때 **파스 트리(Parse Tree)**를 사용해 문법 구조를 분석한다.
게임 트리: 체스나 바둑과 같은 게임에서 가능한 모든 수를 탐색해 최적의 수를 찾을 때 게임 트리를 사용한다.
머신 러닝과 인공지능(AI):
트리는 머신 러닝과 인공지능에서 널리 사용된다. 의사 결정 과정을 시각적으로 표현하고, 데이터를 분류하는 데 도움을 준다다.
예시:
의사 결정 나무(Decision Tree): 특정 데이터를 분류하거나 회귀 분석할 때 의사 결정 트리를 사용해 각 단계에서 최적의 선택을 할 수 있다.
자연어 처리(NLP): 문장을 트리 구조로 파싱해 문법적 의미를 분석한다.
음성 인식, 추론, 최적화에서도 트리를 사용해 복잡한 문제를 효율적으로 해결한다.
트리를 표현하는 방법은 크게 3가지로 분류할 수 있다. 첫번째 인접 리스트 먼저 살펴보자
트리의 표현 #1 - 인접 리스트 (Adjacency List) ⬇️
💡요약: 인접 리스트로 표현하므로써 공간 절약의 효과가 있다. 노드들이 자신과 연결된 노드들만 저장하므로, 트리에서 발생하는 불필요한 정보는 저장하지 않기 때문이다. 또한 탐색 효율성도 증가한다. 특정 노드에 연결된 다른 노드를 찾는 과정이 인접 리스트로 빠르게 처리될 수 있다.
이러한 인접 리스트 방식은 트리뿐만 아니라 그래프와 같은 자료구조를 표현하는 데도 매우 유용하다. 각 노드에 연결된 다른 노드를 리스트로 저장함으로써 탐색, 삽입, 삭제와 같은 작업을 효율적으로 수행할 수 있기 때문이다.

트리 구조 (왼쪽 그림):
숫자 1을 루트 노드로 하는 트리가 있다. 각 노드는 다른 노드들과 부모-자식 관계로 연결되어 있다
예시 트리:
1번 노드는 6번 노드와 4번 노드와 연결되어 있다.
6번 노드는 3번 노드와 1번 노드와 연결되어 있고, 4번 노드는 2번, 1번, 7번 노드와 연결되어 있다.
인접 리스트 (오른쪽 그림):
각 노드는 자신과 연결된 노드들을 리스트로 저장하고 있다. 이를 인접 리스트(Adjacency List) 라고 부른다.
인접 리스트는 노드마다 연결된 자식 노드들을 표현하는 방식이다. 예를 들어, 1번 노드는 6번 노드와 4번 노드와 연결되어 있으므로, 1번 노드의 리스트에는 6과 4가 들어가게 된다.
트리의 표현 #2 - 일차원 배열 (Array) ⬇️
💡요약: 이진 트리를 배열로 나타내는 방식 중 하나는 레벨 순서대로 배열에 저장하는 방법이다. 이 방법을 사용하면, 트리의 부모와 자식 노드 간의 관계를 배열의 인덱스를 통해 쉽게 표현할 수 있게 된다. 예를 들어, 부모 노드는 배열에서 인덱스 n에 위치하며, 그 자식 노드는 각각 인덱스 2n+1 (왼쪽 자식)과 2n+2 (오른쪽 자식)에 위치하게 된다. 이 방식은 트리 구조를 저장할 때 배열 기반의 저장 방식을 이해하는 데 유용한 예시가 될 수 있다.

왼쪽 그림 (트리 구조):
이진 트리(binary tree)의 형태를 보여주고 있으며, 루트 노드가 9이다.
그 아래로 레벨별로 노드들이 배열되어 있다.
오른쪽 배열 (배열 A):
이진 트리를 배열 A에 레벨 순서대로 저장한 결과를 보여준다.
배열의 각 인덱스에 해당하는 노드 값들이 레벨 순서에 맞게 저장되어 있다.
트리의 표현 #3 - 파이썬 딕셔너리,부모-자식 관계(Linked Representation):⬇️
💡요약: 각 노드가 좌우로 어떤 자식 노드를 가지고 있는지를 명확히 표현하고 있다.

상단 행에 있는 A, B, C, D, E, F, G는 트리의 노드를 나타낸다.
두 번째 행에 있는 left는 각 노드의 왼쪽 자식을, 세 번째 행에 있는 right는 오른쪽 자식을 나타낸다.
노드 A = 왼쪽 자식: B , 오른쪽 자식: C
2️⃣ 이진 검색 트리 (Binary Search Tree)
💡Keyword: 레코드, 필드, 검색키, 삭제 케이스 3가지
이진 트리는 각 노드가 최대 두 개의 자식 노드를 가질 수 있는 트리 구조이다. 이진 검색 트리는 검색을 효율적으로 하기 위해 각 노드에 들어가는 값들이 특정 규칙을 따른다.
효율적인 탐색, 삽입, 삭제:
이진 검색 트리는 탐색, 삽입, 삭제 작업을 효율적으로 수행할 수 있도록 설계되었다.
탐색 속도는 트리가 균형 잡혀 있는 경우 O(logn)로 매우 빠르다. 즉, 트리의 깊이가 최소화되면 탐색 시간이 크게 줄어든다. 예를 들어, 특정 값을 찾을 때, 부모 노드와 비교해 값을 탐색 범위를 절반으로 줄이기 때문에 매우 효율적이다.
불균형 트리 문제:
- 이진 검색 트리는 균형이 중요하다. 만약 트리가 불균형(한쪽으로 치우침)하게 되면, 최악의 경우 시간 복잡도가 O(n)이 되어 연결 리스트처럼 동작할 수 있다. 이를 방지하기 위해 자기 균형 이진 검색 트리(예: AVL 트리, 레드-블랙 트리)가 사용되기도 한다.
응용 분야:
데이터베이스나 파일 시스템에서 검색이 많이 요구되는 경우, 이진 검색 트리가 적합한 자료구조이다. 효율적인 데이터 접근을 위해 자주 사용된다.
예를 들어, 사전 검색, 이름 검색, 로그 기록 탐색 등에서 이진 검색 트리가 활용된다.
중복 값 처리:
- 이진 검색 트리는 중복된 값을 허용하지 않기 때문에, 중복된 값이 있는 경우 특별한 규칙을 적용하거나, 중복을 허용하는 자료구조(예: 해시 테이블)를 사용할 수 있다.
이진 검색 트리의 규칙
각 노드는 하나의 값을 가진다.
각 노드의 값은 모두 달라야 한다. 즉, 중복된 값은 허용되지 않는다.
부모 노드의 값은 항상 왼쪽 자식의 값보다 크고, 오른쪽 자식의 값보다 작아야 한다.
왼쪽, 오른쪽의 하위 트리도 각각 다시 이진 검색 트리의 규칙을 만족해야 한다. 즉, 모든 하위 트리에서도 동일한 규칙이 적용된다.
이진 검색 트리의 주요 구성 요소 #1 ⬇️
💡요약: 이진 검색 트리를 활용하여 데이터를 저장할 때, 검색키는 데이터를 찾는 기준이 되고, 레코드는 해당 검색키에 연관된 모든 데이터를 포함하는 구조이다. 이를 통해 대규모 데이터에서도 빠른 검색과 효율적인 관리가 가능해진다.

검색키 (Search Key): 이진 검색 트서 데이터를 저장할 때 검색 기준이 되는 값이다. 검색키인 학번을 기준으로 이진 검색 트리를 구축하면, 각 학번에 해당하는 레코드를 빠르게 찾을 수 있게 된다. 검색키는 데이터에서 유일한 값이어야 하며, 중복된 키는 허용되지 않는다.
레코드 (Record): 검색키와 연결된 전체 데이터를 포함하는 행을 레코드라고 한다. 예시에서는 한 학생의 정보가 하나의 레코드로 구성되며, 이름, 생년월일, 학과 등의 정보가 포함된다. 예를 들어, 학번이 103인 학생 홍길동의 전체 레코드에는 홍길동의 생년월일(020708)과 학과(정보보안학과) 정보가 포함된다.
필드 (Field): 각 레코드 내에서 개별 항목을 의미하는 값을 뜻한다. 예시에서는 이름, 생년월일, 학과가 각각의 필드이다. 데이터베이스에서는 **열(column)**로 표현된다. 어떤 필드를 검색 기준으로 삼을지에 따라 성능이 달라질 수 있다. 일반적으로 검색에 가장 유용한 고유 값(예: 학번)이 선택된다. 결론적으로 필드는 데이터를 구조화하는 데 중요한 역할을 한다. 이진 검색 트리에서는 주로 검색키만을 기준으로 검색을 하지만, 검색 후에는 관련된 필드 정보가 활용된다.
이진 검색 트리의 다양한 형태 3가지 ⬇️

💡요약: 이진 검색 트리(BST: Binary Search Tree)가 완전 이진 트리가 아닌 경우도 포함된다는 것을 설명하고 있는 예제이다. 즉, 이진 검색 트리는 노드의 배치에 따라 다양한 구조를 가질 수 있다는 것을 보여주고 있다. 하지만 불균형한 트리는 성능에 큰 영향을 미칠 수 있다는 점을 알아두자. 트리가 불균형할 경우 탐색, 삽입, 삭제 작업의 시간 복잡도가 **O(n)**으로 늘어날 수 있기 때문이다.
이진 검색 트리에서는 균형이 중요합니다. 불균형한 트리는 성능 저하를 유발할 수 있으므로, 이를 방지하기 위해 자기 균형 이진 트리(예: AVL 트리, 레드-블랙 트리)를 사용하여 균형을 유지하는 방법도 고려해야 한다. 이 트리들은 자동으로 균형을 맞추기 때문에 탐색과 삽입, 삭제가 **O(log n)**의 시간 복잡도를 보장한다.
첫 번째 트리 (왼쪽):
트리의 구조가 한쪽으로 치우친 경우이다. 모든 자식 노드가 왼쪽으로만 존재하는 형태로, 트리의 깊이가 불필요하게 깊어질 수 있다.
이 경우 탐색, 삽입, 삭제와 같은 연산이 최악의 경우 연결 리스트처럼 동작하여 **O(n)**의 시간 복잡도를 가질 수 있게 된다.
두 번째 트리 (가운데):
균형이 맞지 않은 트리이다. 왼쪽에 노드가 조금 더 많이 배치되어 있고, 오른쪽에는 5만 배치되어 있는 모습이다.
이진 검색 트리의 기본 규칙인 왼쪽 자식은 부모보다 작고, 오른쪽 자식은 부모보다 크다는 규칙은 유지된다.
이 구조도 불균형이기 때문에 일부 연산이 비효율적으로 처리될 수 있다.
세 번째 트리 (오른쪽):
비교적 균형 잡힌 트리입니다. 각 노드의 왼쪽과 오른쪽에 자식 노드가 고르게 분포되어 있다.
트리의 높이가 최소화되어 있어 탐색, 삽입, 삭제 같은 연산이 효율적으로 이루어질 수 있다. 이진 검색 트리의 이상적인 형태에 가깝다.
이진 검색 트리의 검색 ⬇️

탐색 과정:
탐색할 값 x를 트리의 루트 노드 t와 비교한다.
t는 현재 노드의 값을 나타내며, 트리의 각 노드는 left와 right로 각각의 왼쪽 및 오른쪽 자식을 가지게 된다.
비교 기준:
x == t: 탐색할 값 x가 현재 노드 t의 값과 같다면, 해당 노드를 찾은 것
x < t: 탐색할 값 x가 현재 노드 t의 값보다 작다면, 왼쪽 서브트리로 이동해서 계속 탐색 진행
x > t: 탐색할 값 x가 현재 노드 t의 값보다 크다면, 오른쪽 서브트리로 이동해서 탐색을 이어간다.
탐색 예시:
트리 구조: 루트 노드에 값이 10인 트리가 있다고 가정해보자
만약 x = 7을 찾고자 한다면:
x(7) < 10이므로, 왼쪽 서브트리로 이동한다.
왼쪽 서브트리의 루트 값이 5라면, x(7) > 5이므로 오른쪽 서브트리로 이동한다.
오른쪽 서브트리에서 값이 7인 노드를 찾으면, 탐색이 완료되게 된다.
이진 검색 트리의 검색 의사코드 ⬇️
💡요약: 이진 검색 트리의 탐색 알고리즘은 재귀적으로 동작하며, 노드의 값을 비교하여 왼쪽이나 오른쪽 서브트리로 이동하면서 값을 찾아낸다. 이 과정은 트리가 균형을 유지할 때 매우 효율적이며, 대규모 데이터에서 자주 사용되는 방법이다.

treeSearch(t, x): t: 트리의 루트 노드, x: 검색하고자 하는 값(키)
1. 기본 조건 (종료 조건):
먼저, t가
NIL(트리의 끝을 의미하거나, 노드가 없을 때) 또는 현재 노드의 키 값이 x와 동일한 경우, 즉 찾고자 하는 값을 찾은 경우, 해당 노드 t를 반환한다.이는 탐색이 성공한 경우, 해당 값을 포함한 노드가 반환되고, 실패한 경우
NIL을 반환하게 된다.
2. 값이 더 작은 경우:
만약 x < key[t] (찾고자 하는 값이 현재 노드의 값보다 작은 경우):
왼쪽 서브트리로 이동한다.. 즉,
treeSearch(left[t], x)를 호출한다.이는 트리의 왼쪽 자식 노드를 새로운 루트로 설정하여 다시 검색을 시작하는 재귀 호출이다.
3. 값이 더 큰 경우:
만약 x > key[t] (찾고자 하는 값이 현재 노드의 값보다 큰 경우):
오른쪽 서브트리로 이동한다. 즉,
treeSearch(right[t], x)를 호출한다.마찬가지로, 오른쪽 자식 노드를 새로운 루트로 설정하여 다시 재귀적으로 탐색을 시작하게 된다.
이진 검색 트리의 검색의 성공과 실패 ⬇️
💡요약: 성공적인 탐색은 트리 안에 존재하는 값까지 정확하게 경로를 따라가는 경우를 의미한다. 반면, 실패하는 탐색은 값이 존재하지 않아서 트리의 말단(리프) 또는 없는 자식 노드에 도달하는 경우를 의미한다.

(a) 성공적인 검색:
왼쪽 그림은 성공적인 검색을 보여주고 있다.
루트 노드 t에서 시작해, 검색하려는 값 x를 찾기 위해 노드 r을 거쳐 아래로 이동하는 경로가 표시되어 있다.
탐색 경로를 따라 내려가면서 x값을 발견한 시점에서 탐색이 성공적으로 종료된다.
이 상황은 탐색하려는 값이 트리 안에 존재하는 경우이다.
(b) 실패하는 검색:
오른쪽 두 그림은 실패한 검색을 나타내고 있다.
첫 번째 그림에서는 루트 노드 t에서 출발해, r 노드까지 이동하지만 e에 도달한 시점에서 더 이상 자식 노드가 없는 상태가 되었다 이 경우, 탐색하려는 값이 트리에 존재하지 않기 때문에 실패하게 된다.
두 번째 그림 역시 탐색 과정에서 값이 존재하지 않음을 나타내고 있다. 결국 루트에서부터 내려가는 탐색 경로를 따라가지만, 값이 없는 경우 탐색이 실패로 끝난다.
탐색이 실패하면, 일반적으로 NULL코드나 에러코드와 같은 특정 값을 반환하여 사용자에게 값이 없음을 알리고 그 후 추가적인 로직(값 추가, 오류 메시지 출력 등)을 수행하게 된다.
이진 검색 트리의 삽입 규칙 예제 ⬇️

왼쪽 자식: 삽입할 값이 부모 노드의 값보다 작은 경우, 왼쪽 자식으로 삽입됨
오른쪽 자식: 삽입할 값이 부모 노드의 값보다 큰 경우, 오른쪽 자식으로 삽입
이 규칙을 따라가면서 삽입할 위치를 찾고, 알맞은 위치에 새로운 값을 삽입하게 된다.
이진 검색 트리의 삽입 의사코드 ⬇️
💡요약: 이진 검색 트리에서 값을 삽입하는 과정은 크기 비교를 통해 적절한 위치를 찾고, 빈 자리에 새로운 노드를 생성해 삽입하는 것이다. 알고리즘은 재귀적으로 동작하며, 트리의 구조가 삽입 후에도 유지되도록 해야한다..

treeInsert(t, x) t: 트리의 루트 노드, x: 삽입하고자 하는 값(키)
기본 조건 (t가 NIL일 때):
트리의 해당 자리에 **NIL(빈 노드)**이 있으면, 새로운 노드를 생성하여 그 자리에 삽입한다.
새로운 노드 r을 생성하고, 그 노드의 **key[r]**에 x 값을 저장한다..
새로운 노드의 left와 right 자식 포인터는 NIL로 설정하고, r을 반환한다.
삽입할 값 x가 현재 노드의 값보다 작은 경우:
**x < key(t)**이면, 삽입할 값이 현재 노드의 값보다 작으므로 왼쪽 서브트리로 이동한다.
**left[t]**에 대해 재귀적으로 **treeInsert(left[t], x)**를 호출하여, 왼쪽 서브트리에 값을 삽입한다.
작업이 완료된 후, 트리의 루트 노드 t를 반환한다.
삽입할 값 x가 현재 노드의 값보다 큰 경우:
**x > key(t)**이면, 삽입할 값이 현재 노드의 값보다 크므로 오른쪽 서브트리로 이동한다.
**right[t]**에 대해 재귀적으로 **treeInsert(right[t], x)**를 호출하여, 오른쪽 서브트리에 값을 삽입한다.
마찬가지로, 작업이 완료된 후 t를 반환한다.
이진 검색 트리의 삭제 3가지 케이스 소개⬇️

이진 검색 트리에서 노드를 삭제할 때 고려해야 할 세 가지 경우는 다음과 같다.
자식이 없는 리프 노드: 단순히 노드를 트리에서 제거한다.
자식이 하나인 노드: 부모 노드와 자식 노드를 직접 연결하여 삭제된 노드를 대체한다.
자식이 두 개인 노드: 오른쪽 서브트리의 최소값(또는 왼쪽 서브트리의 최대값)을 찾아 삭제할 노드를 대체한 후, 해당 후계 노드를 삭제한다.
이진 검색 트리의 삭제 의사코드 ⬇️
💡요약: 이 알고리즘은 삭제하려는 노드의 자식 수에 따라 처리를 달리하는데, 자식이 둘일 때는 후계 노드(오른쪽 서브트리의 최소값)를 찾아 대체하는 방식이 사용되고 있다.

Case 1: r이 리프 노드인 경우: 리프 노드는 자식이 없는 노드이므로 단순히 r을 삭제하면 된다.
Case 2: r의 자식이 하나만 있는 경우: r의 자식 노드가 하나만 있을 때, 부모 노드가 r의 자식을 직접 가리키도록 연결을 변경한다. 즉, 부모 노드와 자식 노드를 직접 연결한다.
Case 3: r의 자식이 둘인 경우: r의 오른쪽 서브트리에서 최소값 노드(s)를 찾고, s를 r의 자리로 옮긴다. 그 후 s 노드를 삭제하여 중복을 없앤다.
이진 검색 트리의 삭제 동작 Case 1 ⬇️

이진 검색 트리의 삭제 동작 Case 2 ⬇️
💡요약: 자식이 하나인 노드를 삭제하는 것은 비교적 간단합니다. 부모 노드와 자식 노드를 직접 연결하면 되기 때문에, 트리 구조가 쉽게 유지된다. 또한 데이터 무결성을 유지하는 것이 중요하다. 이진 검색 트리는 왼쪽 자식이 부모보다 작고, 오른쪽 자식이 부모보다 커야 하는 규칙이 있어, 삭제 후에도 이 규칙이 유지되어야 한다.

(a) r의 자식이 하나뿐임:
삭제하고자 하는 노드 r(값 30)은 자식 노드가 하나만 있는 경우이다. 이 자식 노드는 48이다.
노드 r을 삭제하기 위해, r의 부모와 자식 노드를 직접 연결해주어야 한다.
(b) r을 제거함:
- r을 트리에서 제거한다. 이제 r의 부모 노드(값 28)는 r 대신 **r의 자식 노드(48)**와 연결할 준비를 한다.
(c) r의 자리에 r의 자식을 놓음:
r의 부모 노드인 28이 **r의 자식 노드(48)**와 연결되었다.
이로써 트리의 연결 구조는 유지되며, r은 트리에서 제거된 상태가 된다.
이진 검색 트리의 삭제 동작 Case 3 ⬇️
💡요약: 자식이 두 개 있는 노드를 삭제할 때는 간단히 삭제할 수 없고, 후계자(오른쪽 서브트리의 최소값 또는 왼쪽 서브트리의 최대값)를 찾아 대체하는 방식이 필요하다. 후계 노드를 찾고, 그 자리를 정리하는 과정이 필요하므로 자식이 없는 노드나 자식이 하나인 노드를 삭제하는 것보다 상대적으로 복잡하다. 이 과정은 후계 노드 선택, 트리의 균형 유지 등이 중요한 포인트라고 할 수 있다.


1. (a) r의 직후 원소 s를 찾음:
삭제하려는 노드 **r(28)**이 자식이 두 개 있는 경우, **r을 대체할 노드(s)**를 찾아야 한다.
여기서는 r의 오른쪽 서브트리에서 가장 작은 노드(즉, 오른쪽 서브트리의 최소값 노드) **s(30)**를 찾았다. **s(30)**는 r을 대체할 노드로 선택된다.
2. (b) r을 제거함:
- **r(28)**이 트리에서 제거되었다. 이제 **s(30)**이 r의 자리로 이동할 준비를 하게 된다.
3. (c) s를 r 자리로 옮김:
**s(30)**가 **r(28)**의 위치로 이동한다. 즉, r을 대체하는 노드로 s가 자리하게 된다.
이제 **s(30)**은 트리 구조에서 r이 원래 차지하고 있던 위치에 자리하게 되었다.
4. (d) s가 있던 자리에 s의 자식을 놓음:
**s(30)**의 이전 위치를 정리해야 한다. **s(30)**이 이동한 후 그 자리에 s의 자식 노드(있는 경우)를 연결한다.
이 예시에서는 **s(30)**의 자식이 38이므로, 38을 s가 있던 자리에 놓는다.
이 방법을 사용하면 트리의 구조적 안정성을 유지할 수 있게된다.
3️⃣ 세그먼트 트리 (Segment Tree)
💡Keyword: O(log n)시간 복잡도, O(2n)공간 복잡도, A[N] = A[2N] + A[2N + 1] 트리초기화, 세그먼트 트리 인덱스 = 주어진 질의 인덱스 + 2^k - 1 배열인덱스를 트리 인덱스로 변환,
세그먼트 트리의 개념과 구현 단계 ⬇️
세그먼트 트리는 주어진 데이터의 구간 합, 최대값, 최소값 등의 구간 연산을 빠르게 처리할 수 있도록 설계된 트리 자료구조이다. 세그먼트 트리는 크게 3가지로 구현 된다.
1. 트리 초기화하기: 주어진 데이터 배열을 바탕으로 세그먼트 트리를 생성하는 과정이다. 각 노드가 특정 구간의 값을 대표하며, 이를 초기화한다.
2. 질의 값 구하기: 트리에서 구간 합, 최소값, 최대값 등의 쿼리를 빠르게 처리한다.
3. 데이터 업데이트하기: 배열의 값이 변경될 때, 해당 값이 포함된 구간의 값을 업데이트하는 과정이다.
세그먼트 트리의 동작 1# - 트리 초기화 1단계 ⬇️

리프 노드의 개수가 데이터의 개수 이상이 되도록 트리 리스트를 만듦:
세그먼트 트리는 주어진 데이터의 개수를 포함할 수 있는 완전 이진 트리 형태로 구성됩니다.
트리 리스트의 크기는 2^k ≥ N을 만족하는 k의 최소값을 구한 후, 2^k * 2를 트리 배열의 크기로 정의한다.
여기서 N은 주어진 데이터의 개수이다. 트리의 높이를 결정할 때, 데이터의 개수를 수용할 수 있도록 2의 거듭제곱 형태로 정의하고, 그 크기에 2를 곱한 값이 최종 트리 배열의 크기가 된다.
주어진 샘플 데이터는
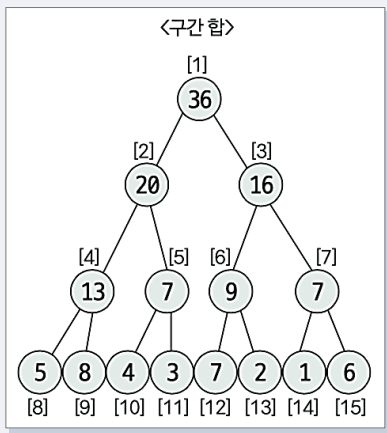
{5, 8, 4, 3, 7, 2, 1, 6}으로, N = 8.2^3 ≥ 8이므로, 트리 리스트의 크기는 2^3 * 2 = 16으로 정의된다.
세그먼트 트리의 동작 #1 - 트리 초기화 2단계 ⬇️

리프 노드에 원본 데이터를 입력: 주어진 원본 데이터를 리프 노드에 입력하여 주어진 데이터 배열의 각 요소를 확인한다. 이때 리프 노드가 트리 배열에서 시작하는 위치는 2^k 인덱스이다. 예시에서 k = 3이므로 리프노드가 시작하는 인덱스는 8이 된다. 즉, 트리 배열의 8번 인덱스부터 원본 데이터가 순서대로 입력되는 것이다. 예시에서는 [8, 9, 10, 11, 12, 13, 14, 15] 인덱스에 해당하는 값들이 각각 {5, 8, 4, 3, 7, 2, 1, 6}으로 채워지게 된다.
세그먼트 트리의 동작 #1 - 트리 초기화 3단계⬇️

리프 노드에는 이미 주어진 데이터를 삽입했으므로, 이제 리프 노드를 제외한 부모 노드에 값을 채워야 한다.
자식 노드의 인덱스를 이용한 부모 노드 값 채우기:
부모 노드의 값은 그 아래 두 자식 노드의 값을 더해 계산된다.
부모 노드의 값은 A[N] = A[2N] + A[2N + 1] 형태로 계산되며, 왼쪽 자식 노드는 2N, 오른쪽 자식 노드는 2N + 1 위치에 있다.
역순으로 계산:
중간 노드들의 값을 채우는 과정은 리프 노드 바로 위의 부모 노드부터 루트 노드까지 역순으로 계산된다.
즉, 트리의 하단에서부터 상단으로 구간 값을 계산하며 올라가며, 마지막으로 루트 노드가 전체 구간의 합을 저장하게 된다.
세그먼트 트리의 동작 #1 - 트리 초기화 4단계 ⬇️
위에서 설명한대로 따라하면 다음과 같이 표현할 수 있다. 아래는 실제 트리 모양으로 구조화 된 트리배열이다.

세그먼트 트리의 동작 #2- 질의문을 받았을 때: 배열 인덱스를 트리 인덱스로 변환 1단계 ⬇️
💡요약: 세그먼트 트리가 완성된 후, 질의(구간 합, 최댓값, 최솟값)를 받으면, **리프 노드 인덱스로 변환**한 후, 해당 구간에 대한 값을 계산하게 된다.
배열의 인덱스는 트리의 맨 아래 리프 노드에 대응한다. 세그먼트 트리에서는 트리의 크기가 배열보다 크기 때문에, 배열의 인덱스를 트리의 인덱스로 변환해야 한다.
세그먼트 트리의 리프 노드는 배열에서 주어진 데이터가 배치된 위치에 대응하며, 배열의 인덱스를 기준으로 계산 되게 된다. 주어진 배열의 인덱스를 세그먼트 트리의 리프 노드 인덱스로 변환하는 공식은 아래와 같다.
세그먼트 트리 인덱스 = 주어진 질의 인덱스 + 2^k - 1

여기서 k는 트리에서 리프 노드가 시작하는 인덱스를 결정하는 값이다.
예를 들어, k = 3인 경우, 배열의 인덱스 i를 세그먼트 트리 인덱스로 변환할 때 i + 7이 된다.
샘플에서 k 값이 3인 경우:
- 샘플에서 k = 3일 때, 주어진 질의 인덱스가 예를 들어 0이라면, 세그먼트 트리에서 해당 인덱스는 0 + 7 = 7로 변환된다.
세그먼트 트리의 동작 #2- 질의문을 받았을 때: 배열 인덱스를 트리 인덱스로 변환 2단계 ⬇️
💡요약: 시작 인덱스와 종료 인덱스로부터 값을 구하면서 부모 노드로 이동한다. 각 단계에서는 현재 노드가 선택되는 조건과 부모 노드로 이동하는 과정이 반복된다. 각 노드가 선택되는지 여부는 짝수 또는 홀수 인덱스인지에 따라 결정되며, 부모 노드로 이동하면서 질의가 점점 상위 구간으로 축소되게 된다.

시작 인덱스가 홀수인지 확인 (
start_index % 2 == 1):- 시작 인덱스가 홀수일 때, 해당 노드를 선택한다. 이 노드는 구간에 포함되며, 선택된 값을 구간 결과에 포함시킨다.
종료 인덱스가 짝수인지 확인 (
end_index % 2 == 0):- 종료 인덱스가 짝수일 때, 해당 노드를 선택한다. 이 역시 구간에 포함되는 노드이다.
시작 인덱스를 부모 노드로 이동:
- 선택이 완료된 후, 시작 인덱스는 (start_index + 1) / 2로 이동한다. 이는 현재 노드의 부모 노드로 이동하는 것을 의미한다.
종료 인덱스를 부모 노드로 이동:
- 마찬가지로, 종료 인덱스도 (end_index - 1) / 2로 이동하여 부모 노드로 넘어간다.
반복:
- 이 과정을 반복하다가, end_index가 start_index보다 작아지면 루프를 종료하고, 질의가 완료된다.
세그먼트 트리의 동작 #3- 질의값 구하기⬇️
💡요약: 구간 합, 최댓값 구하기, 최솟값 구하기 등 여러 가지 구간 질의를 처리할 때, 노드를 선택하는 방식은 동일하며, 마지막에 연산하는 방식만 다르다. 선택된 노드들에 대해 더하기를 할지, 최댓값이나 최솟값을 선택할지는 질의 유형에 따라 달라진다. 세그먼트 트리는 이렇게 다양한 구간 질의를 효율적으로 처리할 수 있도록 설계된 자료구조이다.
질의하는 값의 종류에 따라 마지막에 연산하는 방식이 달라진다:
구간 합: 선택된 노드들의 값을 모두 더함.
최댓값: 선택된 노드들 중에서 최대값을 선택.
최솟값: 선택된 노드들 중에서 최소값을 선택.
예를 들어:
구간 합을 구할 때는, 선택된 노드들의 값을 모두 더해서 구간 합을 계산함
최댓값을 구할 때는, 선택된 노드들 중 가장 큰 값을 선택함
최솟값을 구할 때는, 선택된 노드들 중 가장 작은 값을 선택함
세그먼트 트리의 동작 #2- 질의값(구간 합) 구하는 2가지 단계 소개 ⬇️
💡요약: 세그먼트 트리에서 질의값을 구하는 과정은 크게 2가지 나눌 수 있다. 첫 번째 방법은 모든 리프 노드를 직접 계산하기 때문에 느리고 두 번째 방법은 부모 노드로 이동하면서 구간을 나누어 계산하므로 더 빠르고 효율적이다. 두가지 방법 모두를 살펴보자
리프 노드에서 시작하여 구간에 해당하는 값을 찾는다.
부모 노드로 이동하면서 구간을 점점 좁혀간 뒤 끝까지 부모 노드로 이동하여 구간 값을 모두 선택한 후, 결과를 계산한다.
end_index < start_index가 되어 더 이상 선택할 노드가 없게되면 질의가 종료된다.
구간 합, 최댓값, 최솟값을 구하는 방법은 모두 동일한 과정을 거치며, 마지막에 어떤 연산(덧셈, 최댓값, 최솟값)을 하는지에 따라 결과가 달라진다.
세그먼트 트리의 동작 #2 -
질의값(구간 합) 구하기 예제 첫번째 방법: 리프 노드에서 시작 ⬇️

배열에서 2번 인덱스부터 6번 인덱스까지의 값의 합을 구하고 싶다면, 그냥 배열에서 하나하나 더하는 대신, 세그먼트 트리를 이용하면 더 빠르게 합을 구할 수 있다. 주어진 트리에서 2번 인덱스부터 6번 인덱스까지의 합을 구해보자
배열 = [5, 8, 4, 3, 7, 2, 1, 6]
1) 리프 노드 인덱스로 변환
처음으로, 배열에서 구간을 정한다. 여기서는 2번 인덱스부터 6번 인덱스까지이다. 사진에서 볼 수 있듯이 배열의 인덱스는 트리의 맨 아래 리프 노드에 대응한다. 세그먼트 트리에서는 트리의 크기가 배열보다 크기 때문에, 배열의 인덱스를 트리의 인덱스로 변환해야 한다.
변환 공식은:
트리의 리프 노드 인덱스 = 배열 인덱스 + 2^k - 1
#k는 리프 노드가 시작하는 위치를 결정하는 값
2) 변환 과정:
배열의 2번 인덱스는 트리에서 9번 인덱스로 변환된다.
start_index = 2 + 7 = 9배열의 6번 인덱스는 트리에서 13번 인덱스로 변환된다.
end_index = 6 + 7 = 13
즉, 배열의 2번 인덱스에서 6번 인덱스까지의 값은 세그먼트 트리에서 9번 노드에서 13번 노드로 대응된다. (아래 참조)

이 값들을 모두 더하면:
8 + 4 + 3 + 7 + 2 = 24
트리의 구조상, 단순히 리프 노드를 더하는 것보다 부모 노드로 이동하면서 구간을 나누어 합을 구할 수도 있다. 예를 들어, 시작과 끝 인덱스가 홀수나 짝수일 때, 부모 노드로 이동하면서 중간 계산을 할 수 있다. 다음 예제에서 더 자세히 다뤄본다.
세그먼트 트리의 동작 #2 -
질의값(구간 합) 구하기 예제 두번째 방법: 부모 노드로 이동하며 구간 값 계산 1 ⬇️


1. start_index와 end_index의 현재 상태:
현재 start_index = 9, end_index = 13이다.
이때, start_index는 홀수(9)이고, end_index도 홀수(13)이다.
2. start_index 선택 및 부모 노드로 이동:
start_index % 2 == 1이므로, 노드 9번을 선택하게 된다. 이 노드는 구간에 포함되므로 구간 합을 구할 때 사용된다.
이후 start_index를 부모 노드로 이동시킨다.
start_index는 노란 형광펜 처럼
(start_index + 1) / 2 = (9 + 1) / 2 = 5로 바뀐다.즉, 5번 노드로 이동합니다.
3. end_index 선택 및 부모 노드로 이동:
end_index % 2 == 1이므로, 노드 13번은 선택하지 않게 된다. 선택하지 않는다는 뜻은 연산에 사용되지 않고 부모 노드로 이동한다 뜻이다.
end_index는
(end_index - 1) / 2 = (13 - 1) / 2 = 6으로 변경됩니다.- 즉, 6번 노드로 이동한다.
세그먼트 트리의 동작 #2 -
질의값(구간 합) 구하기 예제 두번째 방법2 : 구간합을 구하는 마지막 단계 ⬇️


1. start_index와 end_index의 상태:
처음에 start_index = 5, end_index = 6이다.
start_index % 2 == 1 → 5번 노드 선택 (구간 합에 포함).
end_index % 2 == 0 → 6번 노드 선택(구간 합에 포함).
2. 부모 노드로 이동:
start_index는
(start_index + 1) / 2로 부모 노드로 이동:- 즉,
(5 + 1) / 2 = 3으로 이동한다.
- 즉,
end_index는
(end_index - 1) / 2로 부모 노드로 이동:- 즉,
(6 - 1) / 2 = 2로 이동한다.
- 즉,
3. 구간 합 계산 종료:
end_index < start_index가 되어 더 이상 선택할 노드가 없으므로, 질의가 종료된다.
이때 선택된 노드는 5, 6, 7번 노드이다.
5번 노드의 값: 8
6번 노드의 값: 9
7번 노드의 값: 7
따라서, 구간 합은
8 + 9 + 7 = 24가 된다.
이 방법은 구간 합, 최댓값, 최솟값을 구할 때 모두 사용되며, 연산 방식만 마지막에 달라진다.
세그먼트 트리의 동작 - 데이터 업데이트 하기 ⬇️

💡요약: 5번 인덱스의 값을 7에서 10으로 업데이트하는 과정이다. 세그먼트 트리에서 값이 변경되면, 해당 리프 노드뿐만 아니라 부모 노드들도 그 차이를 반영하여 값을 수정하게 된다. 여기서 5번 노드의 값이 7에서 10으로 변경됨에 따라 부모 노드와 루트 노드의 값이 변화한 것을 확인할 수 있다.
1. 데이터 업데이트 과정: 구간 합의 경우, 변경된 값과 원래 값의 차이가 부모 노드로 올라가면서 변경 사항을 반영하게 된다. 즉, 값이 업데이트되면 해당 노드뿐만 아니라 부모 노드들까지 변화가 전달되어, 최종적으로 루트 노드의 값도 바뀌게 된다.
2. 5번 인덱스 업데이트 예시: 원래 5번 노드의 값은 7이었다. 이 값을 10으로 변경하면서, 세그먼트 트리의 부모 노드들도 그 차이를 반영해야 한다. 즉, 값이 3만큼 증가했으므로 부모 노드들도 그만큼 변경되어야 한다.
3. 변경 사항이 부모 노드로 전달: 5번 인덱스의 값이 10으로 변경된 후, 변경된 값(3)은 부모 노드들로 전달되었다. 6번 노드의 값이 변경된 후, 그 상위 노드인 12번 노드, 루트 노드까지 이 변화가 반영된다. 이로 인해 전체 트리 구조의 값이 다시 계산되어 최종적으로 루트 노드의 값까지 반영되게 된다.
학습정리






