Contents
1️⃣ 정렬 알고리즘 복습 (Review of Sort Algorithms)
2️⃣ 해시 테이블 (Hash Table)
3️⃣ 해시 함수 (Hash Function)
1️⃣ 정렬 알고리즘 복습
(Review of Sort Algorithms)
💡요약: 정렬(Remind)은 크게 비교 정렬(Comparison Sort) 특수 정렬(Special Sort)로 나뉜다. 비교 정렬은 원소를 하나씩 비교해야 해서 시간이 많이 걸릴 수 있지만, 모든 종류의 데이터에 적용할 수 있다. 반면, 특수 정렬은 데이터의 값에 따라 위치를 바로 정할 수 있어 더 빠르게 정렬할 수 있지만, 특정 상황에만 사용할 수 있다.

☑️ 비교 정렬 (Comparison Sort)
두 원소를 비교 연산을 통해 정렬한다. 예를 들어, 숫자 3과 5를 비교하여 어떤 숫자가 더 작은지 판단한 후 순서를 정하는 방식이다. 시간복잡도는 최악의 경우 O(n log n)이다. (최대한 효율적으로 정렬하려고 해도 이 정도 시간이 걸린다.)
비교 정렬 예제: 버블 정렬 (Bubble Sort)
- 배열 [5, 3, 8, 1]이 주어지면, 인접한 원소들을 비교하며 더 작은 수가 앞쪽으로 이동하도록 한다. 각 원소를 반복해서 비교하므로 시간복잡도는 O(n^2)이 된다.

☑️ 특수 정렬 (Special Sort)
각 원소의 값에 따라 바로 자리를 결정하여 정렬한다. 예를 들어, 숫자 3이 주어졌을 때 이미 할당된 위치로 이동시켜 정렬한다. 이 방식에서는 비교 연산 없이 O(n)의 시간복잡도로 정렬이 가능해진다. (비교할 필요가 없어 더 빠르다.)
특수 정렬 예제: 계수 정렬 (Counting Sort)
배열 [3, 1, 4, 1, 3]이 주어졌을 때, 각 숫자가 몇 번 나왔는지 세어 적절한 위치에 배치한다.
비교 연산이 없어 더 빠르게 실행되며, 시간복잡도는 O(n)이다.
검색과 저장 효율성을 높이기 위한 자료구조의 기본 개념 #1:자료의 저장과 검색 (Storage and Search)
검색 트리(Search Tree)
해시 테이블(Hash Table)
💡요약: 검색 트리는 데이터를 정렬하고 비교하여 저장하기 때문에 균형 잡힌 상태에서 빠르게 작동할 수 있지만, 완전한 상수 시간에 비할 수는 없다. 반면, 해시 테이블은 특정 값을 기반으로 위치를 계산하기 때문에 매우 빠른 검색과 저장이 가능하지만, 충돌이 발생할 가능성도 있어 이를 해결하는 방식이 필요하다.

☑️검색 트리 (Search Tree)
데이터를 저장할 때 비교 연산을 통해 트리 구조에서 데이터를 검색하거나 위치를 정한다. 예를 들어, 숫자 8을 트리에 삽입하려면 기존의 값들과 비교하여 적절한 위치에 저장한다. 시간복잡도는 균형잡힌 트리의 경우 O(log n)으로, 검색과 저장이 빠르게 수행될 수 있다.
검색 트리 예제: 이진 검색 트리 (Binary Search Tree)
- [5, 3, 8, 1]이 주어졌을 때, 5를 루트로 하고 작은 값들은 왼쪽, 큰 값들은 오른쪽에 배치하여 트리를 만든다. 예를 들어, 3과 5를 비교하여 3이 왼쪽에, 8이 오른쪽에 위치한다.

☑️해시 테이블 (Hash Table)
각 원소의 값에 따라 특정한 위치(주소)를 계산하여 바로 그곳에 저장하거나 검색하는 방식이다. 예를 들어, 값이 3이라면 미리 정해진 위치로 바로 이동하여 저장한다. 이 방식은 O(1)의 상수 시간으로 매우 빠르게 수행될 수 있다.
해시 테이블 예제: 간단한 해싱 예제
- 키가 3이면 해시 함수에 따라 미리 정의된 위치에 3을 저장한다. 예를 들어, "해시 함수(key % 10)"를 사용하여 값 3을 위치 3에 저장할 수 있다.
검색과 저장 효율성을 높이기 위한 자료구조의 기본 개념 #2:자료의 저장과 검색 (Storage and Search)
버킷 정렬
해시테이블
💡요약: 자료의 저장과 검색 (Storage and Search)에서 사용되는 여러 데이터 구조와 그 시간 복잡도 (Time Complexity)를 비교한 것이다. 다양한 데이터 구조는 각기 다른 검색 시간을 제공한다. 해시 테이블은 일반적으로 가장 빠르지만, 모든 상황에 적합한 것은 아니다. B-트리와 이진 검색 트리는 상대적으로 빠르며, 배열은 단순하지만 검색에는 시간이 오래 걸릴 수 있다.

배열 (Array)
배열은 단순히 데이터를 순차적으로 저장하는 구조로, 특정 데이터를 찾으려면 전체를 탐색해야 한다.
시간복잡도는 O(n)으로, 크기가 커질수록 검색 속도가 느려진다.
예) [2, 4, 6, 8] 배열에서 숫자 8을 찾으려면 처음부터 순서대로 비교하기 때문에 시간복잡도는 O(n)이 된다.
이진 검색 트리 (Binary Search Tree)
데이터가 정렬된 구조로, O(log n)의 시간복잡도로 빠르게 검색할 수 있지만, 불균형해지면 O(n)까지 느려질 수 있다는 단점이 있다.
예) 이진 검색 트리에서 [2, 4, 6, 8] 배열 중 숫자 8을 찾으려면, 중간값과 비교하며 왼쪽 또는 오른쪽으로 이동한다. 정렬된 트리에서 O(log n)의 시간복잡도로 검색이 가능하다.
B-트리 (B-Tree)
- 데이터베이스에서 자주 사용되는 구조로, 균형이 잘 잡혀 있어 O(log n)의 시간복잡도로 안정적인 검색 속도를 보장한다.
해시 테이블 (Hash Table)
특정 키 값을 기반으로 데이터를 저장하고 검색하기 때문에 O(1)의 시간복잡도로 가장 빠르게 데이터를 찾을 수 있다.
예) 해시 테이블에서 키가 8인 값을 찾으려면, 해시 함수를 사용하여 바로 위치를 알아내어 찾을 수 있다. 시간복잡도는 O(1)이다.
버킷 정렬 (Bucket Sort)과 해시 테이블 (Hash Table)의 차이점
💡요약: 두 방법 모두 데이터를 효율적으로 정렬하거나 검색하기 위해 특정 위치에 데이터를 저장하는 방식을 사용하지만, 그 방법과 용도가 다르다. 특수정렬에 해당하는 버킷 정렬은 데이터의 값을 기준으로 정해진 범위에 따라 버킷에 데이터를 나눠 정렬하는 방법이다. 반면, 해시 테이블은 해시 함수를 사용하여 데이터의 위치를 계산해 저장하고 검색하기 때문에 검색 속도가 빠르다. 각 방식은 특정 용도에 적합하며, 데이터의 특성에 따라 선택할 수 있다.

☑️ 버킷 정렬 (Bucket Sort)
배열의 원소에 특정 숫자를 곱한 후, 정수부를 이용해 데이터가 속할 버킷 위치를 계산한다. 예를 들어, 0.38, 0.48과 같은 소수들을 15를 곱한 후 정수부로 나누어 각 버킷에 분배하는 방식이다.
이 방식은 데이터의 범위가 일정한 경우 효과적으로 사용할 수 있으며, 데이터가 각 버킷에 나누어지기 때문에 정렬에 적합하다.
들어, [0.78, 0.17, 0.39, 0.26]이라는 데이터를 10개의 버킷에 나눠 정렬한다고 가정합니다. 각 데이터에 10을 곱하고 정수부를 기준으로 버킷에 배치한 후, 각 버킷을 정렬하여 결과를 얻을 수 있다.

☑️ 해시 테이블 (Hash Table)
해시 함수를 사용해 데이터의 저장 위치를 계산한다. 예를 들어, 값이 0.38이라면 해시 함수에 따라 지정된 위치에 바로 저장된다.
이 방식은 빠르게 데이터를 검색하거나 삽입할 수 있어 빠른 데이터 검색에 적합하다.
키-값 쌍으로 구성된 데이터를 해시 테이블에 저장한다고 가정해보자. 예를 들어, 키가 8인 데이터를 저장하려면 해시 함수에서 위치를 계산하여 그 위치에 저장하고, 키를 통해 해당 데이터를 빠르게 찾을 수 있다.
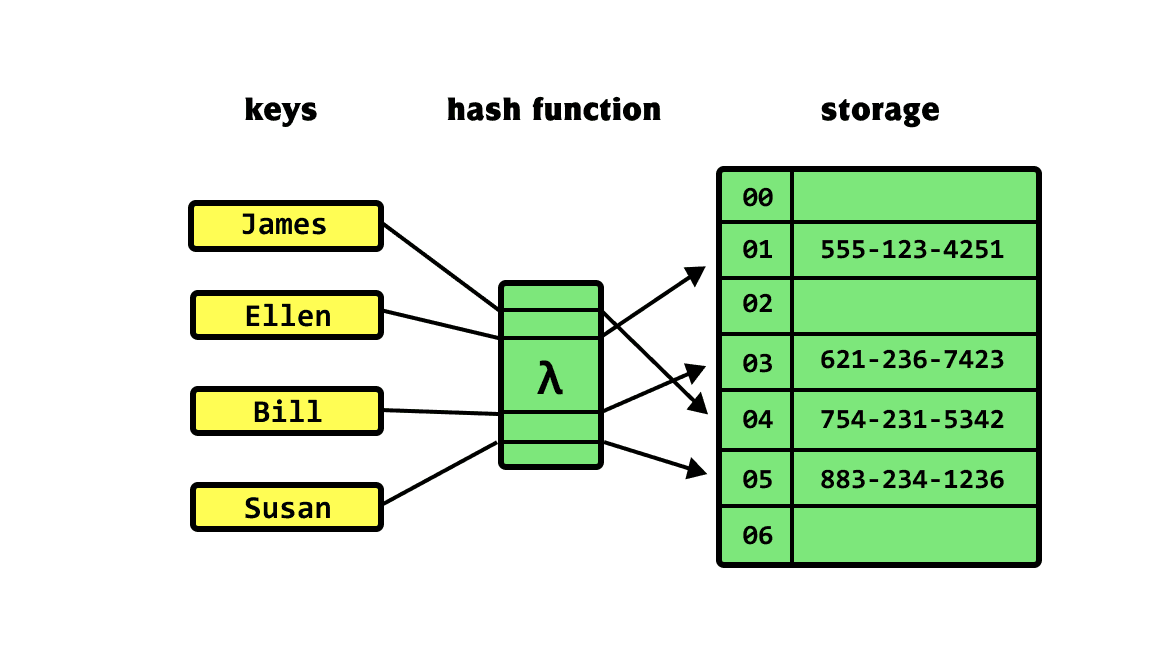
2️⃣ 해시 테이블 (Hash Table)
해시테이블의 정의
💡요약: 해시 테이블은 특정 값의 위치를 빠르게 계산하여 데이터를 저장하고 검색할 수 있는 자료 구조이다. 즉 빠른 데이터 접근이 필요한 상황에서 활용한다. 그러나 비교 연산을 지원하지 않기 때문에, 최대값이나 최소값을 찾는 용도로는 부적합하다.
해시 테이블의 정의
- 해시 테이블은 원소가 저장될 자리가 원소 자신의 값을 기반으로 결정되는 구조이다. 즉, 해시 테이블은 데이터를 키-값(key-value) 쌍으로 저장하는 자료구조이다.
상수 시간 (Constant Time)에 삽입, 삭제, 검색이 가능하다. 평균적으로 O(1) 시간이 소요되며, 빠르게 처리해야 하는 상황에서 매우 유용하다.
빠른 응답이 필요할 때 사용된다. 예를 들어, 데이터베이스에서 특정 사용자의 데이터를 빠르게 찾아야 할 때 사용된다.
최대값이나 최소값을 찾는 작업과 같은 비교 연산에는 적합하지 않다. 해시 테이블은 특정 값을 찾는 데는 빠르지만, 값 간 비교가 필요한 작업에는 사용할 수 없다.
💡예시: 학생들의 학번을 키로, 이름을 값으로 저장하는 해시 테이블이 있다고 가정하자.
학번이 12345인 학생의 이름을 찾고 싶다면, 해시 함수를 통해 학번에 해당하는 위치를 찾아 즉시 이름을 검색할 수 있다.
해시 함수(Hash Function)의 정의
💡요약: 해시 테이블 (Hash Table)과 해시 함수 (Hash Function)는 서로 다른 개념이다. 그러나 해시 테이블은 해시 함수가 필요하며, 해시 함수는 해시 테이블을 사용하는 데 중요한 역할을 한다.
해시 테이블: 해시 함수를 통해 계산된 위치에 데이터를 저장하고 검색하는 자료구조이다.
해시 함수: 입력 데이터를 고정된 범위의 해시 값으로 변환하는 계산 방식이다.
정의: 해시 함수는 임의의 크기를 가진 데이터를 입력받아 고정된 크기의 고유한 값(해시 값 또는 해시 코드)으로 변환하는 함수이다.
역할: 주어진 데이터(예: 키 값)를 특정한 숫자나 위치로 변환하여 해시 테이블에서 해당 데이터가 저장될 위치를 계산하는 역할을 한다.
특징: 해시 함수는 같은 입력에 대해 항상 같은 해시 값을 반환하며, 이 값은 고정된 범위 내에 있다.
예제: 예를 들어, 문자열 "apple"을 해시 함수에 넣으면
4라는 해시 값이 나온다고 가정할 때, "apple"은 해시 테이블의 4번 위치에 저장되게 된다.
해시테이블과 해시함수의 관계와 차이점
해시 함수는 해시 테이블의 동작에 필수적이다. 해시 함수가 없다면, 해시 테이블은 데이터를 빠르게 저장하고 찾을 위치를 계산할 수 없기 때문이다.
해시 함수는 데이터의 위치를 결정하는 계산 방식이며, 해시 테이블은 그 위치에 데이터를 저장하고 관리하는 자료구조이다.
해시 테이블이 데이터를 효율적으로 저장하고 찾기 위해 해시 함수를 필요로 하지만, 해시 함수 자체는 특정한 위치에 데이터를 저장하는 것이 아니라 단순히 데이터를 고정된 범위의 숫자로 변환하는 역할을 한다.
예를 통해 이해해보자
해시 함수 사용: "apple"이라는 키를 해시 함수에 넣으면
4라는 숫자가 나온다.해시 테이블에 저장: 해시 테이블은 이
4라는 해시 값을 이용해 4번 슬롯에 "apple" 데이터를 저장한다.데이터 검색: 나중에 "apple"을 검색할 때, 해시 함수는
4라는 값을 다시 반환하고, 해시 테이블은 4번 슬롯에서 데이터를 빠르게 찾는다.
해시 테이블의 구조 (Structure of Hash Table)
💡요약: 해시 테이블은 해시 함수를 통해 입력된 키를 특정 위치로 변환하여 빠르게 데이터를 저장하거나 검색할 수 있게 하는데, 데이터를 고유한 슬롯에 저장함으로써 검색 시간을 크게 줄여준다.

검색 키 (Key)
- 데이터를 찾기 위해 사용하는 검색 키가 입력된다. 예를 들어, 학생의 학번이나 물건의 ID가 검색 키가 될 수 있다.
해시 함수 (Hash Function)
- 해시 함수는 입력된 검색 키를 특정한 해시 값 (Hash Value)으로 변환하여 해시 테이블 내에서 데이터가 저장될 주소를 계산한다. 이 함수는 키를 고유한 위치로 매핑해주기 때문에, 데이터가 어떤 슬롯 (Slot)에 저장될지를 결정한다.
해시 테이블의 슬롯 (Slot/Bucket)
- 해시 값에 의해 결정된 위치인 슬롯에 데이터가 저장된다. 해시 테이블은 이러한 슬롯이 배열처럼 배치된 구조로, 각 슬롯에는 특정 키에 대응하는 데이터가 저장된다.
💡예시: 학생의 학번을 키로, 이름을 값으로 저장하는 해시 테이블이 있다고 가정하자. 학번이 12345인 학생의 이름을 저장하려면, 해시 함수를 통해 학번을 해시 값으로 변환하여 저장할 슬롯을 결정하게 된다. 나중에 학번 12345를 검색하면, 같은 해시 함수로 계산된 슬롯에서 해당 학생의 이름을 즉시 검색할 수 있다.
해시 테이블의 예 (Example of Hash Table)
💡요약: 해시 테이블은 해시 함수 (Hash Function)를 사용하여 데이터를 특정한 위치에 저장하는 자료 구조이다. 아래 예시에서는 입력 값을 해시 테이블에 저장하기 위해 간단한 해시 함수 h(x) = x mod 13 을 사용한다. 입력 값을 고르게 분포시키는 것은 해시 테이블의 효율적인 공간 사용과 빠른 검색 성능 (Efficient Search Performance)을 위해 매우 중요하다.

해시 함수 (Hash Function) h(x) = x mod 13
- 주어진 입력 값을 13으로 나눈 나머지 값을 테이블의 위치로 사용하는 방식이다. 예를 들어, 값이 25인 경우 25 mod 13 = 12 가 되어 12번 위치에 저장된다.
해시 테이블
각 입력 값이 해시 함수를 통해 계산된 위치에 저장된다. 이로 인해 데이터를 빠르게 검색할 수 있게 된다.
예를 들어, 입력 값이 13이라면 13 mod 13 = 0 이 되어, 테이블의 0번 위치에 저장된다.
중요 포인트 (Key Point)
- 입력 원소가 해시 테이블에 고르게 분포되어야 공간 활용도가 높아지고 검색 성능이 향상된다. 만약 모든 값이 특정 위치에 몰리게 되면, 해시 테이블의 성능이 저하될 수 있다.
💡예) 예시 입력 값: [25, 13, 16, 15, 7]
25: 25 mod 13 = 12 → 12번 위치에 저장
13: 13 mod 13 = 0 → 0번 위치에 저장
16: 16 mod 13 = 3 → 3번 위치에 저장
15: 15 mod 13 = 2 → 2번 위치에 저장
7: 7 mod 13 = 7 → 7번 위치에 저장
나머지 연산 (Modulo Operation)
나머지 연산, 또는 모듈로 연산 (Modulo Operation)은 어떤 숫자를 다른 숫자로 나눈 후, 그 나눗셈의 나머지를 구하는 연산이다.
예제: 25 mod 13
25 ÷ 13 = 1.9 와 같이 나누면, 몫은 1이다.
그러나 나머지 연산에서는 소수점 아래 숫자를 무시하고, 정수 몫만 고려다. 즉, 25 ÷ 13 에서 몫이 1이라는 뜻은 “25 = 13 × 1 + 나머지”라는 것을 의미한다.
나머지를 계산해 보면: 25 − (13×1) = 25 −13 = 12 따라서, 25 mod 13=12 된다.
요약하자면
25 ÷ 13 에서 1.9라는 값은 단순히 나누기 결과이다.
그러나 나머지 연산에서는 소수점 아래는 무시하고, 25 = 13 × 1 + 12 로 나머지인 12를 반환하게 되기때문에 25 mod 13 = 12이다.
해시 테이블 활용 사례 (Usage of Hash Table 1#) - 캐시 매핑의 구조 (Structure of Cache Mapping)
💡요약: 캐시 매핑은 데이터 접근 시간을 줄이는 기술로써 주 메모리의 데이터를 캐시에 효율적으로 저장하고 관리하기 위한 방식이다. 컴퓨터가 데이터를 빠르게 처리하기 위해 해싱 (Hashing)을 사용하여 데이터가 캐시 메모리 (Cache Memory)에 저장될 위치를 결정하는 것이다.
☑️ 메모리 주소 (Memory Address)
- 캐시에 저장하고자 하는 데이터를 식별하기 위해 메모리 주소가 사용된다. 이 주소는 데이터의 고유 위치를 나타내며, 메모리 주소가 캐시에서의 위치를 결정하는 데 사용된다.
☑️ 해싱 (Hashing)
- 해시 함수 (Hash Function)가 메모리 주소를 입력받아, 캐시 메모리에서 데이터가 저장될 위치를 계산한다. 이 과정에서 메모리 주소가 특정한 태그 (Tag)로 변환되어, 캐시 메모리의 슬롯 중 하나에 저장되게 된다.
☑️ 캐시 메모리 (Cache Memory)
- 태그와 해시 함수에 의해 결정된 위치인 캐시 메모리의 슬롯에 데이터가 저장된다. 캐시 메모리는 빠르게 접근할 수 있는 메모리로, 자주 사용되는 데이터를 저장해 데이터 접근 속도를 높이는 데 사용된다.
💡예시: 주 메모리에서 주소가 1234인 데이터를 캐시에 저장한다고 가정해보자
이 주소는 해시 함수를 통해 특정 캐시 슬롯 번호로 변환된다. 예를 들어, 해시 함수가 주소 1234를 4번 슬롯으로 매핑하면, 이 데이터는 캐시 메모리의 4번 슬롯에 저장된다. 나중에 주소 1234의 데이터를 요청할 때, 캐시에서 4번 슬롯을 빠르게 참조하여 데이터를 찾을 수 있게 된다.
해시 테이블 활용 사례 (Usage of Hash Table 2#) - 심볼 테이블의 역할과 구조(Structure of Symbol Table)
💡요약: 심볼 테이블은 컴파일러가 프로그램의 심볼을 빠르게 찾아 사용할 수 있도록 해시 테이블을 사용해 심볼 정보를 저장하는 구조이다. 변수와 함수 등의 정보를 효율적으로 저장하고 관리하기 위해 사용되는 컴파일 과정에서 중요한 역할을 한다.

심볼 테이블의 정의
- 심볼 테이블은 컴파일러의 Semantic Analysis (의미 분석) 과정에서 변수, 함수, 데이터 타입 등의 정보를 저장하는 데이터 구조이다. 이 테이블은 코드의 각 심볼(변수나 함수 등)에 대한 정보를 가지고 있어, 컴파일 과정에서 심볼을 빠르게 찾을 수 있도록 도와준다.
심볼 테이블의 구성 요소
심볼 테이블에는 각 심볼의 이름, 데이터 타입, 메모리 위치 등의 정보가 저장된다. 예를 들어, 변수
m과n, 함수foo가 심볼 테이블에 저장되며, 각 심볼의 타입이나 속성 정보가 함께 저장된다.이러한 정보들은 해시 테이블 (Hash Table)로 저장되어, 빠른 검색과 관리를 가능하게 한다. 해시 테이블을 이용해 심볼을 저장함으로써, 필요한 심볼을 빠르게 찾을 수 있어 성능이 향상된다.
💡예제: 변수 int x = 10;과 함수 void foo()가 있는 프로그램을 가정하자.
컴파일러는 변수 x와 함수 foo를 심볼 테이블에 저장한다. 심볼 테이블에는 x의 타입이 int라는 정보와, foo가 함수라는 정보가 저장된다. 나중에 코드에서 x와 foo가 다시 호출될 때, 컴파일러는 심볼 테이블에서 해당 정보를 빠르게 찾아 사용할 수 있다.
❓심볼테이블, 캐시매핑의 차이점
(Difference between Symbol Table and Cache Mapping)
💡요약: 심볼 테이블은 컴파일러에서 코드 내의 변수나 함수 같은 심볼 정보를 빠르게 찾기 위해 해시 테이블을 사용한다. 주로 정적인 정보를 저장하고, 코드 분석에 도움을 준다. 이에 반면 캐시 매핑은 컴퓨터 시스템에서 자주 사용하는 데이터를 빠르게 접근하기 위해 해시 테이블을 활용한 캐시에 저장한다. 동적인 데이터를 관리하며, 실행 속도 향상을 목적으로 한다.
1. 공통점
해시 테이블 사용: 두 개념 모두 해시 테이블을 기반으로 데이터를 저장하고 검색하는 구조를 사용한다. 해시 테이블은 데이터를 빠르게 찾을 수 있는 자료구조로, 해시 함수 (Hash Function)를 통해 데이터를 특정 위치에 매핑하여 저장하는 방식이다.
빠른 검색: 심볼 테이블과 캐시 매핑 모두 해시 테이블을 이용해 빠르게 데이터를 찾고자 하는 목적이 있다.
2. 차이점
☑️ 심볼 테이블 (Symbol Table)
주로 컴파일러에서 사용: 심볼 테이블은 주로 컴파일러에서 사용된다. 컴파일러는 프로그램 코드에서 변수, 함수, 데이터 타입 등을 해시 테이블에 저장하여 심볼(기호)을 빠르게 참조할 수 있게 한다.
- 컴파일러는 컴퓨터에 설치된 소프트웨어 프로그램으로서, 보통 하드 디스크나 SSD에 저장되어 있다가 필요할 때 메모리(RAM)로 불러와 프로그램을 번역하고 최적화하는 역할을 한다.
코드 분석에 초점: 심볼 테이블은 프로그램이 실행되기 전에 코드 내에서 사용된 심볼의 정보를 저장하고 관리한다. 예를 들어, 변수가 어떤 데이터 타입인지, 함수의 매개변수는 무엇인지 등의 정보를 추적한다.
정적인 정보 저장: 프로그램이 실행되기 전에 필요한 정보들을 미리 저장해 두고, 실행 중 변하지 않는 정보를 주로 다룬다.
☑️ 캐시 매핑 (Cache Mapping)
주로 컴퓨터 시스템에서 사용: 캐시 매핑은 컴퓨터 시스템의 메모리 관리에서 사용된. 프로세서가 자주 사용하는 데이터를 캐시에 저장하여 빠르게 접근할 수 있도록 돕는다.
동적인 데이터 저장: 캐시는 주로 프로그램 실행 중에 자주 사용되는 데이터를 저장하기 때문에, 데이터가 지속적으로 바뀌고 갱신된다.
효율적인 메모리 사용: 캐시 매핑은 메모리 접근 시간을 줄여 시스템 성능을 높이기 위한 목적이 있다. CPU가 메모리에 직접 접근하는 것보다 캐시에 접근하는 것이 훨씬 빠르기 때문에, 자주 사용되는 데이터가 캐시에 저장된다.
해시 테이블 활용 사례 (Usage of Hash Table 3#) - 데이터베이스 해시 조인 알고리즘 (Hash Join Algorithms in Database)
💡요약: 해시 조인은 두 테이블의 데이터를 해시 함수를 통해 매핑하여 효율적으로 조인 작업을 수행하는 알고리즘이다. 해시 함수 덕분에, 두 테이블을 직접 비교하는 것보다 더 빠르게 일치하는 데이터를 찾을 수 있게 된다.

선행 테이블 (Build Table)
- 조인 과정에서 첫 번째 테이블이 선행 테이블로 선택된다. 이 테이블의 각 데이터를 해시 함수로 처리하여 해시 테이블에 저장한다. 이를 통해 데이터의 위치를 빠르게 찾을 수 있게된다.
후행 테이블 (Probe Table)
- 두 번째 테이블은 후행 테이블로 사용된다. 이 테이블의 데이터도 해시 함수로 처리되어, 선행 테이블의 해시 테이블에서 일치하는 데이터가 있는지 확인한다.
해시 함수 (Hash Function)
- 해시 함수는 선행 테이블과 후행 테이블의 데이터를 동일한 기준으로 변환하여, 같은 값은 같은 위치로 매핑된다. 이를 통해 조인 작업을 빠르게 수행할 수 있다.
추출 버퍼 (Output Buffer)
- 일치하는 데이터가 발견되면, 그 데이터는 추출 버퍼에 저장된다. 이렇게 추출된 데이터는 최종 결과로 반환된다.
💡예제: 학생 테이블(Student)과 성적 테이블(Grade)이 있고, 두 테이블을 학생 ID를 기준으로 조인한다고 가정한다.
먼저 학생 테이블(Student)을 선행 테이블로 설정하고, 학생 ID를 해시 함수로 변환하여 해시 테이블에 저장합니다.
성적 테이블(Grade)의 각 학생 ID를 해시 함수로 변환하여, 학생 테이블의 해시 테이블에서 일치하는 ID를 찾습니다.
일치하는 ID가 있으면, 해당 데이터는 추출 버퍼에 저장되고 최종 결과로 반환다.
해시 테이블과 암호학적 해시 함수의 차이점
(Difference between Hash Table and Cryptographic Hash Function)
💡요약: 해시 테이블은 데이터의 효율적인 저장과 검색을 위해 설계된 반면, 암호학적 해시 함수는 보안을 위해 설계되어 데이터의 무결성과 인증을 보장한다. 즉, 두 방식은 해시 함수를 사용하지만, 목적과 사용 분야가 다르다.
☑️해시 테이블 (Hash Table)
해시 테이블은 데이터를 빠르게 저장하고 검색하기 위한 자료구조 (Data Structure)로 이를 이용해 데이터가 저장될 위치를 계산하여, 빠른 데이터 접근이 가능하다.
이 자료구조는 주로 데이터의 빠른 저장 및 검색을 위해 사용되며, 중복 레코드를 쉽게 검색할 수 있다는 장점이 있다.
예) 학생 ID를 키로, 이름을 값으로 저장하는 해시 테이블을 가정해보자. 학번이
12345인 학생의 이름을 빠르게 검색하고 저장할 수 있다.
☑️암호학적 해시 함수 (Cryptographic Hash Function)
암호학적 해시 함수는 임의의 데이터를 일정한 길이의 데이터로 변환하는 함수 (Function)이다. 보안 목적의 해시 함수는 데이터의 무결성을 보장하고, 해시 값만으로 원래 데이터를 복원할 수 없기 때문에 주로 인증에 사용된다.
이 함수는 전송 데이터의 무결성을 보장하며, 데이터가 변조되지 않았는지 확인할 때 사용된다.
예) "password123"라는 비밀번호를 암호학적 해시 함수로 변환하면, 해시 값으로 변환된다. 이 해시 값은 원래의 비밀번호를 알 수 없게 하여, 비밀번호 검증에만 사용된다.
❓암호학적 해시 함수는 데이터의 무결성을 보장을 어떻게 하나요?
암호학적 해시 함수는 임의의 입력 데이터를 고정된 길이의 해시 값으로 변환한다. 예를 들어, "Hello World"라는 문장을 SHA-256 해시 함수에 넣으면 항상 고정된 길이의 해시 값이 생성되는데, 입력 데이터가 조금이라도 변경되면 완전히 다른 해시 값이 생성되기 때문에, 데이터를 변경하거나 위조하는 것이 어렵다.
또한 데이터 전송 전, 송신자는 원본 데이터의 해시 값을 생성하고 함께 전송한다. 수신자는 받은 데이터에 동일한 해시 함수를 적용하여 해시 값을 생성한 후, 송신자가 보낸 해시 값과 비교하게 된다.
두 해시 값이 일치하면 데이터가 전송 중 변조되지 않았음을 확인할 수 있다.
두 해시 값이 다르면 데이터가 변조되었을 가능성이 높다.
❓심볼테이블, 캐시매핑, 데이터베이스 해시조인 알고리즘, 그리고 암호학적 해시 함수 이 네가지 개념은 해시함수를 이용한 사례❓
이 네 가지 개념은 모두 해시 함수를 사용하는 사례이지만, 심볼 테이블, 캐시 매핑, 데이터베이스 해시 조인은 빠른 검색과 저장을 위한 용도로 해시 함수를 사용하고, 암호학적 해시 함수는 보안과 무결성 검증을 목적으로 해시 함수를 사용한다는 차이점이 있다.
네 가지 개념에서 해시 함수의 사용 목적
심볼 테이블 (Symbol Table)
해시 함수 사용 목적: 컴파일러가 변수, 함수 등의 심볼을 빠르게 저장하고 찾기 위해 해시 함수를 사용한다.
동작 방식: 심볼 이름을 해시 함수에 입력하여 해시 값을 생성하고, 이를 통해 심볼이 저장될 위치를 결정하여 빠르게 접근할 수 있게 한다.
주요 목적: 빠른 검색과 저장을 위해 해시 함수 사용.
캐시 매핑 (Cache Mapping)
해시 함수 사용 목적: CPU가 자주 접근하는 데이터를 캐시에 저장할 때, 메모리 주소를 캐시의 특정 위치에 매핑하기 위해 해시 함수를 사용한다.
동작 방식: 메모리 주소를 해시 함수에 넣어 특정 캐시 슬롯에 매핑하고, 이후 동일한 메모리 주소로 데이터를 빠르게 찾을 수 있게 한다.
주요 목적: 메모리 접근 속도 향상을 위해 해시 함수 사용.
데이터베이스 해시 조인 (Hash Join)
해시 함수 사용 목적: 두 테이블 간의 조인 작업을 빠르게 수행하기 위해 해시 함수를 사용하여 테이블을 매핑하고 비교한다.
동작 방식: 하나의 테이블의 데이터를 해시 함수로 매핑하여 해시 테이블을 만들고, 다른 테이블의 데이터를 이 해시 테이블과 비교하여 일치하는 데이터를 찾는다.
주요 목적: 데이터베이스에서 효율적인 조인 수행을 위해 해시 함수 사용.
암호학적 해시 함수 (Cryptographic Hash Function)
해시 함수 사용 목적: 보안을 위해 데이터를 고정된 길이의 해시 값으로 변환하여 데이터의 무결성을 검증하고, 데이터의 무작위성을 보장한다.
동작 방식: 입력 데이터를 해시 함수에 넣어 해시 값을 생성하고, 이 값으로 데이터를 비교하거나 검증합니다. 해시 값만으로는 원래 데이터를 복원할 수 없도록 설계되어 있다.
주요 목적: 데이터 무결성 보장 및 보안을 위해 해시 함수 사용.
3️⃣ 해시 함수 (Hash Function)
💡요약: 해시 함수는 검색 키를 특정 위치로 변환하여, 해시 테이블에서 데이터를 빠르게 찾는 데 사용된다. 좋은 해시 함수는 데이터를 고르게 분포시키고, 간단한 계산으로 빠르게 실행되어야 한다.

해시 함수의 정의
- 해시 함수는 주어진 검색 키 (Key)를 해시 주소 (Hash Address)로 변환하는 역할을 한다. 예를 들어, 사용자가 찾고자 하는 데이터를 해시 함수에 입력하면, 이 함수는 데이터를 해시 테이블의 특정 위치로 변환해 빠르게 접근할 수 있도록 한다.
해시 함수가 가져야 하는 특징
고르게 분포 (Uniform Distribution): 해시 함수는 입력 데이터를 해시 테이블에 고르게 분포시켜야 한다. 이렇게 하면 데이터가 특정 위치에 몰리지 않아서, 충돌이 줄어들고 검색 성능이 향상되게 된다.
간단한 계산 (Simple Calculation): 해시 함수는 계산이 간단해야 한다. 복잡한 계산이 필요하면 시간이 오래 걸리기 때문에, 해시 함수는 빠르게 계산될 수 있어야 효율적이다.
💡예) 예를 들어, "apple"이라는 키를 해시 함수에 넣으면, 이 함수는 "apple"을 해시 테이블의 5번 위치로 변환한다고 가정해 보자. 이제 "apple"을 찾고 싶을 때 해시 함수에 "apple"을 넣으면 5번 위치가 나오기 때문에, 그 위치에서 바로 데이터를 찾을 수 있게 된다.
해시 함수를 만드는 방법 - 나누기 (Division Method)
💡요약: 나누기 방식 (Division Method)은 해시 테이블보다 큰 값을 해시 테이블 범위에 들어오도록 수축하는 데 사용된다. 해시 함수를 만들 때 2의 거듭제곱이 아닌 소수를 사용해 입력 값이 해시 테이블에 고르게 분포되도록 하는 것이 중요하다. 이를 통해 공간 활용도와 검색 성능 (Space Utilization and Search Performance)이 향상되게 된다.

해시 함수 정의
- 해시 함수는 h(x)=x mod m으로 정의된다. 여기서 m은 해시 테이블 크기 (Hash Table Size)를 의미한다. 이 방식에서는 입력 값 x를 m으로 나눈 나머지를 사용하여 데이터가 저장될 위치를 결정하게 된다.
소수 사용의 중요성
- m 값으로 2의 거듭제곱이 아닌 소수 (Prime Number Not Close to Power of 2)를 사용하는 것이 좋다. 소수를 사용하면 해시 값이 더 고르게 분포되어 충돌 (Collisions)을 줄이고 성능이 향상된다.
중요 포인트 (Key Point)
- 2의 거듭제곱에 가까운 값을 m으로 사용할 경우, 입력 값의 하위 비트에 의해 해시 값이 결정되므로 분산 효과가 적어진다. 이는 특정 위치에 데이터가 몰리게 되어 충돌이 증가할 수 있다.
💡예시 입력 값: [1,025,390]
해시 테이블 크기 m = 1,601
해시 함수 h(x)=x mod 1,601
계산: 1,025,390 mod 1,601=750
결과: 값 1,025,390은 해시 테이블의 750번 위치에 저장된다.
해시 함수를 만드는 방법 - 곱하기 (Multiplication Method)
💡요약: 곱하기 방식은 해시 테이블보다 작은 범위의 값을 해시 테이블 크기로 확장하여 데이터를 고르게 분포시키는 방식이다. 곱하기 방식은 상수 A와 해시 테이블 크기 m을 사용하여 데이터의 위치를 고르게 분포시키는 해시 함수의 한 방법이다. 특히 m을 2의 거듭제곱으로 설정하면 메모리 효율성과 계산 속도 (Memory Efficiency and Calculation Speed)가 향상된다.

해시 함수 정의
- 해시 함수는 다음과 같이 정의된다 : h(x)=⌊m(x A mod 1)⌋ 여기서 A는 0과 1 사이의 상수로 설정된다. A 값은 고정된 상수이며, 주로 무리수 또는 소수로 설정해 고른 분포를 돕는다.
해시 테이블 크기 m
- m은 소수일 필요가 없으며, 보통 2의 거듭제곱 (Power of 2)으로 설정한다. 이로 인해 메모리 사용과 계산이 용이해진다.
예제 설명
- 예를 들어, m = 65,53, A = 0.6180339887, x = 1,025,390 이면 h(x) = ⌊65,536 × (1,025,390 × 0.6180339887 mod1)⌋ = 57,125 즉, 입력 값 x는 해시 테이블의 57,125번 위치에 저장된다.
중요 포인트 (Key Point)
- 이 방법을 사용할 때 2의 거듭제곱에 가까운 수를 사용하면 하위 비트가 해시 값에 영향을 덜 미쳐 고른 분포를 이끌어낸다.
💡예시 입력 값: [1,025,390]
해시 테이블 크기 m = 65,536
상수 A = 0.6180339887
해시 함수: h(x) = ⌊m(xA mod 1)⌋
계산: h(1,025,390) = 57,125
결과: 값 1,025,390은 해시 테이블의 57,125번 위치에 저장된다.
나누기 방식 (Division Method)과 곱하기 방식 (Multiplication Method)의 공통점과 차이점
💡요약: 두 방식은 목적과 상황에 따라 선택할 수 있으며, 나누기 방식은 간단한 해시 테이블에, 곱하기 방식은 충돌을 최소화해야 하는 경우에 적합하다.

공통점
해시 값을 계산하여 데이터를 분포
- 두 방법 모두 입력 값(키 값)을 해시 테이블 내의 특정 위치로 변환하기 위해 해시 값을 계산한다. 이 해시 값을 통해 데이터를 고르게 분포시키는 것을 목표로 한다.
효율적인 데이터 검색을 위한 목적
- 두 방식 모두 해시 테이블에 효율적인 데이터 저장과 검색을 위해 설계되었다. 해시 값을 통해 저장 위치를 결정하므로, 해시 테이블에서 데이터를 빠르게 찾을 수 있다.
충돌을 줄이기 위한 설계
- 두 방법 모두 해시 테이블의 특정 슬롯에 데이터가 몰리지 않도록 설계되어 충돌을 줄이려는 목적을 가지고 있다. 고르게 분포된 해시 값을 생성해 충돌이 발생할 확률을 낮추는 것을 목표로 한다.
차이점
1. 나누기 방식 (Division Method)
계산 방식: 나누기 방식은 입력 값을 특정 정수로 나눈 나머지를 해시 값으로 사용한다. 즉, 해시 함수는 다음과 같은 형식을 가집니다:
h(x) = x mod m 여기서 x는 키 값, m은 해시 테이블의 크기(보통 소수를 사용).
m의 선택: 보통 소수 (Prime Number)를 선택한다. 소수를 사용하면 입력 값이 고르게 분포되는 경향이 있어, 충돌이 줄어든다.
장점: 계산이 상대적으로 간단하고 빠르다다.
단점: 특정 패턴의 데이터가 입력될 경우, 충돌이 발생할 확률이 높아질 수 있다. 특히 m이 2의 거듭제곱일 경우, 데이터가 특정 비트에 따라 몰릴 가능성이 있다.
2. 곱하기 방식 (Multiplication Method)
계산 방식: 곱하기 방식은 입력 값에 상수를 곱하고, 소수 부분을 추출하여 해시 테이블의 크기에 맞게 조정하는 방식이다. 다음과 같은 형식을 가진다:
h (x) = ⌊m( x A mod 1)⌋ 여기서 A는 0과 1 사이의 상수 (보통 무리수), m은 해시 테이블 크기이다.
A의 선택: 상수 A는 보통 0.6180339887 (황금 비율)과 같은 무리수 값이 사용된다. 이 값은 데이터의 고른 분포를 도와준다.
장점: 곱하기 방식을 사용하면 데이터의 패턴과 상관없이 입력 값이 고르게 분포될 가능성이 높아진다. m을 2의 거듭제곱으로 설정할 수 있어 계산이 효율적이다.
단점: 나누기 방식에 비해 계산이 다소 복잡할 수 있다. 하지만 현대 컴퓨터에서는 큰 부담이 되지 않는다.




