Graph Algorithms: BFS, DFS, Spanning Tree (Prim's and Kruskal's Algorithms)
Contents
1️⃣그래프의 개요(Overview of Graph)
2️⃣그래프의 유형 (Type of Graph)
3️⃣그래프의 표현 (Graph Representation)
4️⃣너비 우선 탐색 (Breadth First Search)
5️⃣깊이 우선 탐색 (Depth First Search)
6️⃣최소 신장 트리(Shortest Spanning Tree)
1️⃣그래프의 개요(Overview of Graph)
💡요약: 그래프(Graph)는 개체와 개체 간의 관계를 표현하는 자료구조이다. 이를 통해 현실 세계의 다양한 관계를 모델링할 수 있으며, 그래프는 다양한 분야에 적용된다. 예를 들어, 두 지점 간 이동 거리, 통신 장비 간 통신 비용, 또는 단어와 단어 간의 연관도를 나타낼 때 사용된다.

✅ 그래프(Graph)의 정의
개체와 개체 간의 관계를 표현하는 자료구조 (A data structure representing relationships between entities).
노드(Node)와 엣지(Edge)로 구성된다.
✅그래프의 응용 예 (Examples of Graph Applications)
정점과 정점 간의 이동 거리 (Distance between points).
통신 장비 간의 통신 비용 (Communication cost between devices).
단어와 단어 간의 연관도 (Association between words).
그래프 #1: 길찾기 알고리즘 (Applications of Graphs - Pathfinding Algorithms)
💡요약: 길찾기 알고리즘은 그래프를 활용하여 최단 경로를 찾는 방법 (Methods for finding the shortest path using graphs)을 보여준다. A* 알고리즘은 길찾기 알고리즘에서 가장 대표적인 예시로, 다양한 실생활 문제에 활용된다.
✅ 길찾기 알고리즘 적용 예 (Examples of Pathfinding Algorithm Applications)
내비게이션 (Navigation): Google Maps와 같은 앱에서 목적지까지의 최단 경로를 계산.
게임의 경로 탐색 (Pathfinding in Games): 캐릭터가 장애물을 피하고 목적지까지 이동.
대중교통 안내 (Public Transport Guidance): 최적의 환승 경로 계산.
✅길찾기 알고리즘의 엔진 (Engine of Pathfinding Algorithms)
최단 경로를 찾는 대표적인 방법은 A* 알고리즘 (A* Algorithm)이며, 이를 기반으로 다양한 변형이 개발되었다.
A* 알고리즘은 그래프 알고리즘의 대표적 사례이 (A representative example of graph algorithms).
그래프 #2: 라우팅 알고리즘 (Applications of Graphs - Routing Algorithms)
💡요약: 라우팅 알고리즘은 통신 네트워크에서 최적의 경로를 찾는 방법 (Finding the optimal route in communication networks)을 설명한다. 다익스트라(Dijkstra) 알고리즘은 라우터 간의 최단 경로 탐색에 사용되는 대표적인 알고리즘이다. 또한, RIP, OSPF, IGRP와 같은 라우팅 프로토콜에서 그래프 알고리즘이 핵심 역할을 한다.
✅라우팅 알고리즘 (Routing Algorithm)
통신 네트워크에서 IP 주소 간의 최적 경로 탐색 (Finding the best routing path between IP addresses in a communication network).
주요 프로토콜 (Key Protocols):
RIP (Routing Information Protocol): 주기적으로 정보를 교환하며 경로를 업데이트.
OSPF (Open Shortest Path First): 링크 상태 기반의 최단 경로 알고리즘.
IGRP (Interior Gateway Routing Protocol): 복수의 메트릭을 사용해 경로를 계산.
✅라우팅 알고리즘의 엔진 (Engine of Routing Algorithms)
라우터 간의 최단 경로를 찾기 위해 다익스트라 알고리즘 (Dijkstra Algorithm)이 주로 사용됨.
다익스트라 알고리즘은 그래프 기반 탐색 알고리즘의 대표적 예 (A representative example of graph-based search algorithms).
그래프 #3: 적용 분야 (Applications of Graphs)
💡요약: 그래프는 다양한 분야에서 복잡한 문제를 시각화하고 해결 (Visualizing and solving complex problems)하는 데 사용된다. 대표적으로 모델링, 통신, 경로 탐색 (Modeling, Communication, Pathfinding) 분야에서 중요한 역할을 한다.
✅ 모델링 (Modeling): 그래프는 다양한 과학적 및 공학적 문제를 모델링하는 데 사용된다.
반도체 회로 설계 (Semiconductor Circuit Design): 회로 내 전류 흐름을 그래프로 표현.
DNA 분석 (DNA Analysis): DNA 염기서열의 유사성을 그래프 형태로 비교.
사회과학적 모델링 (Social Science Modeling): 사람들 간의 관계를 그래프로 분석해 네트워크 구조 이해.
✅ 통신 (Communication): 그래프는 네트워크와 통신 구조 최적화에 필수적이다.
IP 라우팅 (IP Routing): 인터넷 데이터 패킷의 최적 경로 탐색.
IoT 네트워킹 (IoT Networking): 스마트 기기 간 효율적인 연결 경로 설계.
이동 통신 중계기 최적화 (Optimization of Mobile Communication Relays): 신호 전달의 품질을 높이기 위한 최적 경로 계산.
✅ 경로 탐색 (Pathfinding): 현실 세계의 경로 문제를 해결하는 데 사용된다.
내비게이션 (Navigation): 최단 시간 경로 탐색.
게임 경로 탐색 (Game Pathfinding): 캐릭터의 최적 이동 경로 계산.
지능형 교통 시스템 (Intelligent Traffic Systems): 차량 흐름을 최적화하고 교통 혼잡 완화.
2️⃣그래프의 유형 (Type of Graph)
- 단순 무향 그래프(Simple Undirected Graph)
정점(Node)와 간선(Edge)으로 구성된 간단 그래프이다.
간선에 방향이 없으며 (Edges are undirected), 관계는 양방향으로 간주된다.
적용 예 (Applications)
친구 관계 분석 (Analyzing Friendships): 소셜 네트워크에서 사람들 간의 관계를 시각화.
도로 연결성 확인 (Checking Road Connections): 도시 간 도로 연결 여부를 모델링.
혼인 관계 분석 (Analyzing Marriage Relationships): 가족 관계를 무향 그래프로 표현.

각 원(circle)은 사람을 나타내는 정점(Node)이다.
선(line)은 두 사람이 친밀한 관계(Friendly Relationship)에 있는 것을 나타낸다.
예시:
철수 ↔ 준호: 친밀감 있음.
승우 ↔ 재상: 친밀감 있음.
간선의 방향이 없으므로 관계는 양방향적이다.
- 가중치 무향 그래프 (Weighted Undirected Graph)
노드(Node)와 엣지(Edge)로 구성된 그래프.
엣지에 가중치(Weight)를 포함하여 두 노드 간의 관계 정도를 수치로 표현한다.
방향성이 없으며 (No Direction), 관계는 양방향으로 간주된다.
적용 예 (Applications)
사람 간 친밀감 분석 (Analyzing relationships between people): 친구 간 친밀도를 정량화.
도시 간 거리 측정 (Measuring distances between cities): 도시간 이동 거리나 비용 계산. Dijkstra 알고리즘을 사용해 최단 경로를 계산 가능
공항 간 비행 시간 분석 (Analyzing flight times between airports): 최단 비행 경로를 찾는 데 사용.

노드(Node): 철수, 영희, 준호 등 사람을 나타낸다.
엣지(Edge): 사람들 간의 친밀감을 나타내며, 가중치(Weight)는 친밀감의 정도를 나타낸다.
예: 철수와 영희 간의 친밀감 = 9.
준호와 재상 간의 친밀감 = 5.
엣지의 가중치가 클수록 관계가 더 강함을 의미한다.
- 단순 유향 그래프 (Simple Directed Graph)
노드(Node)와 방향이 있는 간선(Edge)으로 구성된 그래프.
간선은 방향성을 가지며 (Edges have direction), 관계는 한쪽으로만 적용된다.
상호 대칭적이지 않은 관계를 모델링할 때 사용된다.
적용 예 (Applications)
기업 간의 제품 공급 관계 (Product supply relationships between companies): A 회사가 B 회사에 제품을 공급하지만 반대는 아님.
생산 공정의 순서 관계 (Sequence relationships in production processes): 제품 생산 단계 간의 의존성 표현. 자동차 공장 조립 과정 진행 사항 A→B→C 등
도로 시스템 (Road Systems): 일방통행 도로 모델링.

노드(Node): 철수, 영희, 재상 등 사람을 나타낸다.
간선(Edge): 사람 간의 애정 흐름을 나타냄.
철수 → 영희: 철수가 영희를 좋아함.
준호 → 승우: 준호가 승우를 좋아함.
각 관계는 한쪽 방향으로만 연결되어 있음.
- 가중치 유향 그래프 (Weighted Directed Graph)
노드(Node)와 방향이 있는 간선(Edge)으로 구성된 그래프.
제일 복잡한 구조
간선(Edge)은 방향을 가지며 가중치(Weight)는 관계의 강도, 비용, 또는 거리를 나타낸다.
방향성이 있으므로 관계는 상호 대칭적이지 않을 수 있음 (Relationships may not be mutual).
적용 예 (Applications)
도시 간 이동 비용 (Inter-city travel costs): A도시에서 B도시로 이동하는 비용이 B에서 A로 이동하는 비용과 다를 때, 혹은 A도시에서 B도시를 거쳐 C도시까지 가는 이동 거리 계산 등
물류 네트워크 (Logistics Networks): 물건을 한 지점에서 다른 지점으로 운반하는 비용.
소셜 네트워크 (Social Networks): 한 사람이 다른 사람을 얼마나 좋아하거나 신뢰하는지를 점수로 표현.

노드(Node): 철수, 영희, 준호, 승우 등 사람을 나타낸다.
간선(Edge): 사람 간 애정의 흐름.
예: 철수 → 영희(가중치 9): 철수가 영희를 많이 좋아함.
영희 → 동근(가중치 6): 영희가 동근을 좋아함.
각 간선의 가중치(Weight)는 관계의 강도, 예를 들어 애정의 크기를 나타냄.
3️⃣그래프의 표현 (Graph Representation)
개체의 개수가 수백, 수만개가 된다면 육안으로 식별하기 불가능해진다. 컴퓨터 공학에서는 그림이 아닌 자료구조를 이용하여 그래프를 표현한다.
그래프 표현 #1 인접 행렬 이용 - 단순 무향 그래프
(Graph Representation Using Adjacency Matrix - Simple Undirected Graph)
💡요약: 인접 행렬 (Adjacency Matrix)은 그래프를 수학적으로 표현하는 방식으로, 노드 간의 연결 여부를 행렬로 나타낸다. (Represents node connections as a matrix). 단순 무향 그래프에서는 간선이 양방향이고 대칭적인 특성을 가진다.
✅인접 행렬의 정의 (Definition of Adjacency Matrix)
정점(Node)의 총 개수가 n이라면, n × n 행렬을 생성한다.
행렬의 각 값은 노드 간의 연결 유무 (Presence of a connection)를 나타낸다.
1: 연결되어 있음.
0: 연결되어 있지 않음.
단순 무향 그래프에서는 대각선 방향으로 대칭 행렬 (Symmetric Matrix)이 된다.

철수 ↔ 영희 (철수 1, 영희 2)
연결되어 있다. 그림에서 철수(1)와 영희(2) 사이에 간선이 존재한다.
- 따라서 인접 행렬에서 행(1), 열(2) = 1.
철수 ↔ 승우 (철수 1, 승우 6)
연결되어 있다. 그림에서 철수(1)와 승우(6) 사이에 간선이 존재한다.
- 따라서 인접 행렬에서 행(1), 열(6) = 1.
✅ 인접 행렬의 장점과 단점 (Advantages and Disadvantages)
장점 (Advantages):
구현이 단순하고, 노드 간 연결 여부를 빠르게 확인 가능.
정적(Static) 그래프에서 효율적.
단점 (Disadvantages):
노드가 많을수록 메모리 사용량 증가.
희소 그래프(Sparse Graph)에서는 비효율적.
그래프 표현 #2 인접 행렬 이용 - 가중치 무향 (Graph Representation Using Adjacency Matrix - Weighted Undirected Graph)
💡요약: 인접 행렬 (Adjacency Matrix)은 그래프의 노드 간 관계를 가중치로 표현 (Represents relationships between nodes with weights)하는 자료구조이다. 가중치 무향 그래프 (Weighted Undirected Graph)에서는 간선이 양방향이며, 가중치(Weight)는 두 노드 간 관계의 크기나 강도를 나타낸다. 인접 행렬에서 대각선 방향으로 대칭 행렬 (Symmetric Matrix)이 된다.
✅가중치 무향 그래프의 정의 (Definition of Weighted Undirected Graph)
노드(Node)와 간선(Edge)으로 구성되며, 간선에 가중치(Weight)가 포함된다.
대칭 행렬: A [i] [j] = A [j] [i]
가중치가 0인 경우: 해당 노드 간에 연결이 없음.

노드(Node): 철수(1), 영희(2), 동근(3), 준호(4), 재상(5), 승우(6).
간선의 가중치(Edge Weight):
철수(1) ↔ 영희(2): 9.
철수(1) ↔ 준호(4): 5.
철수(1) ↔ 승우(6): 6.
영희(2) ↔ 동근(3): 9.
동근(3) ↔ 재상(5): 5.
재상(5) ↔ 승우(6): 1.
행렬로 표현:
A[1][2]=9, A[3][5]=5 등.
대칭적이므로 A [i] [j] = A [j] [i]
✅ 간단한 예제: 도시 간 이동 비용
노드(Node): 도시를 나타냄(서울, 부산, 대구 등).
간선(Edge): 도시 간 연결 여부.
가중치(Weight): 두 도시 간 이동 비용.
서울 ↔ 부산: 300km (행렬에서 300).
부산 ↔ 대구: 150km (행렬에서 150).
문제: 최소 비용으로 모든 도시를 연결하는 경로 찾기.
- Kruskal 또는 Prim 알고리즘 사용.
그래프 표현 #2 인접 행렬 이용 - 단순 유향 (Graph Representation Using Adjacency Matrix - Simple Directed Graph)
💡요약: 단순 유향 그래프 (Simple Directed Graph)는 간선에 방향성이 있는 그래프 (A graph where edges have direction)를 표현한다. 인접 행렬에서는 행과 열의 교차점 값이 간선의 존재 여부를 나타낸다. (Shows whether an edge exists between nodes). 비대칭 행렬 (Asymmetric Matrix)이 특징으로, 방향에 따라 값이 달라질 수 있다.
✅ 단순 유향 그래프의 정의 (Definition of Simple Directed Graph)
노드(Node)와 방향이 있는 간선(Edge)으로 구성.
간선은 한쪽 방향으로만 연결되며, 역방향으로는 연결되지 않을 수 있음.
인접 행렬에서:
값이 1: 해당 방향으로 간선이 존재.
값이 0: 해당 방향으로 간선이 없음.
실생활 시나리오: Twitter 팔로우 관계를 분석하거나, 정보 흐름을 추적할 때 활용한다.

노드(Node): 철수(1), 영희(2), 동근(3), 준호(4), 재상(5), 승우(6).
간선(Edge):
철수(1) → 영희(2): 연결 (행렬[1][2] = 1).
철수(1) → 승우(6): 비연결 (행렬[1][6] = 0).
영희(2) → 동근(3): 연결 (행렬[2][3] = 1).
동근(3) → 재상(5): 비연결 (행렬[3][5] = 0).
준호(4) → 승우(6): 비연결 (행렬[4][6] = 0).
승우(6) → 재상(5): 연결 (행렬[6][5] = 1).
✅ 장점과 단점
장점 (Advantages):
방향성을 명확히 표현 가능.
노드 간 관계를 수학적으로 쉽게 확인.
단점 (Disadvantages):
큰 그래프에서 비어 있는 값이 많으면 메모리 비효율적.
희소 그래프(Sparse Graph)에 비효율적.
그래프 표현 #3 인접 행렬 이용 - 가중치 유향 (Graph Representation Using Adjacency Matrix - Weighted Directed Graph)
💡요약: 가중치 유향 그래프 (Weighted Directed Graph)는 방향과 가중치를 동시에 표현한다. 인접 행렬 (Adjacency Matrix)에서는 각 원소가 가중치 (Weight)를 나타내며, 방향성을 포함하기 때문에 비대칭 행렬 (Asymmetric Matrix)이 된다.
✅ 가중치 유향 그래프의 정의 (Definition of Weighted Directed Graph)
그래프의 노드(Node)와 방향을 가진 간선(Edge)으로 구성.
간선에는 가중치(Weight)가 포함되며, 이는 관계의 강도나 크기를 나타냄.
행렬에서는:
A[i][j] = 가중치
A[i][j] = 0: 간선이 없음을 의미.

노드(Node): 철수(1), 영희(2), 동근(3), 준호(4), 재상(5), 승우(6).
간선(Edge)와 가중치(Weight):
철수(1) → 영희(2): 가중치 9 (A[1][2]=9).
철수(1) → 준호(4): 가중치 8 (A[1][4]=8).
철수(1) → 승우(6): 가중치 6 (A[1][6]=6).
영희(2) → 동근(3): 가중치 9 (A[2][3]=9).
동근(3) → 재상(5): 가중치 5 (A[3][5]=5).
재상(5) → 승우(6): 가중치 1 (A[5][6]=1).
준호(4) → 승우(6): 가중치 5 (A[4][6]=5).
✅ 장점과 단점
장점 (Advantages):
간선의 가중치와 방향을 명확히 표현 가능.
빠르게 노드 간 관계와 가중치를 확인 가능.
단점 (Disadvantages):
희소 그래프(Sparse Graph)에서 비효율적(불필요한 0 값이 많음).
노드가 많아질수록 메모리 소모 증가.
그래프 표현 #4 : 인접 행렬 이용 장단점 (Advantages and Disadvantages of Using Adjacency Matrix)
💡요약: 인접 행렬 (Adjacency Matrix)은 그래프를 표현하는 자료구조로, 간선의 존재와 관계를 빠르게 확인할 수 있지만, 메모리와 연산 효율성 측면에서 제약이 있다. 간선의 밀도가 높을수록 효율적 (Efficient for dense graphs), 밀도가 낮으면 비효율적 (Inefficient for sparse graphs)이다.
✅ 장점 (Advantages)
간선의 존재 여부를 빠르게 확인 가능 (Can check edge existence in constant time).
행렬의 특정 원소 A [i] [j]를 확인하면 간선의 존재 여부를 바로 알 수 있다.
예: 도시 간 연결 여부를 빠르게 확인.
✅ 단점 (Disadvantages)
시간 복잡도: O(n2)
그래프를 초기화하거나 탐색할 때, 모든 n × n 원소를 처리해야 함.
예: 희소 그래프에서 간선이 거의 없을 경우 불필요한 계산이 많음.
공간 복잡도: O(n2)
그래프의 노드 개수에 비례하여 큰 메모리 공간을 차지.
예: 1000개의 노드가 있을 경우, 행렬은 1,000,000개의 원소가 필요.
✅ 그래프 밀도와 효율성 (Graph Density and Efficiency)
간선의 밀도가 정점의 개수 대비 50%이상 높은 그래프에 효율적이다. 간선의 밀도가 낮은 경우는 비효율적이다.
그래프의 밀도 = 간선의 개수 / 가능한 최대 간선 수.
밀도 ≥ 50%: 인접 행렬이 효율적.
밀도 < 50: 메모리 낭비로 비효율적.
✅ 적용 예제
효율적인 경우 (Dense Graphs):
네트워크 연결 상태 확인: 네트워크의 모든 장비가 자주 서로 연결될 때.
예: 완전 그래프 (모든 노드가 서로 연결).
비효율적인 경우 (Sparse Graphs):
- 도로 지도: 도시가 1000개여도 실제 연결된 도로는 몇백 개에 불과할 경우.
그래프 표현 #5 : 인접 리스트를 이용한 방법 - 단순 무향 (Graph Representation Using Adjacency List - Simple Undirected Graph)
💡요약: 인접 리스트 (Adjacency List)는 그래프를 효율적으로 표현하기 위한 자료구조로, 각 정점에 인접한 정점들을 리스트 형태로 저장한다. (Stores adjacent vertices for each vertex as a list). 공간 효율성이 뛰어나며, 희소 그래프 (Sparse Graph)에서 특히 효과적이다.
✅ 인접 리스트의 정의 (Definition of Adjacency List)
각 정점(Node)에 대해, 인접한 정점들을 연결된 리스트 형태로 저장한다.
노드 간의 연결 정보만 저장 (Stores only connected nodes), 불필요한 0 값 없이 효율적.
예제)
효율적인 경우 (Sparse Graphs): 도로 네트워크
도시 간 연결된 도로만 간선으로 저장.
예: 도시 A ↔ 도시 B, 도시 C ↔ 도시 D.
비효율적인 경우 (Dense Graphs):
- 완전 그래프: 모든 노드가 서로 연결된 경우, 공간 효율성이 떨어질 수 있음.

노드(Node): 철수(1), 영희(2), 동근(3), 준호(4), 재상(5), 승우(6).
인접 리스트:
철수(1): [2, 3, 4, 6]
영희(2): [1, 3]
동근(3): [1, 2, 5]
준호(4): [1, 6]
재상(5): [3, 6]
승우(6): [1, 4, 5]
✅ 장점 (Advantages)
공간 효율성 (Space Efficiency):
간선만 저장하므로 희소 그래프에서 메모리를 아낄 수 있음.
공간 복잡도: O(V + E) (정점 수 V, 간선 수 E).
인접 노드 탐색이 빠름 (Efficient Neighbor Traversal):
- 특정 노드에 인접한 노드 탐색에 적합.
✅ 단점 (Disadvantages)
간선 존재 여부 확인이 느림 (Slower Edge Existence Check):
간선을 탐색하려면 리스트를 순회해야 함.
시간 복잡도: O(V) (정점 수 V).
구현 복잡도 증가 (Increased Implementation Complexity):
- 배열보다 구현이 복잡함.
그래프 표현 #6 : 가중치 무향 그래프 (Graph Representation Using Adjacency List - Weighted Undirected Graph)
💡요약: 가중치 무향 그래프 (Weighted Undirected Graph)는 정점 간의 연결과 가중치를 저장 (Stores connections and weights between vertices)한다. 인접 리스트 (Adjacency List)를 사용하여, 각 노드에 연결된 노드와 간선의 가중치(Weight)를 함께 저장한다. 리스트의 각 항목에는 두 개의 공간이 있으며, 첫 번째는 정점 번호 (Node number), 두 번째는 가중치 (Weight)이다.
✅인접 리스트의 정의 (Definition of Adjacency List)
각 정점(Node)에 대해, 인접한 정점과 해당 간선의 가중치를 저장.
무향 그래프에서는 양방향 간선을 나타내기 위해 인접 리스트의 두 노드에 각각 추가.
예제)
효율적인 경우 (Sparse Graphs): 도로 네트워크
도시 간 이동 거리(가중치)를 저장하며, 연결된 도시만 포함.
예: 도시 A ↔ 도시 B(50km), 도시 C ↔ 도시 D(100km).
비효율적인 경우 (Dense Graphs): 노드가 많고 거의 모든 노드가 연결된 경우, 관리가 어려워질 수 있음.

✅ 장점 (Advantages)
공간 효율성 (Space Efficiency):
간선만 저장하므로 메모리 절약.
공간 복잡도: O(V+E)
가중치 정보 포함 가능 (Supports Weights):
- 각 노드의 연결 리스트에 가중치 정보를 함께 저장.
✅ 단점 (Disadvantages):
간선 존재 여부 확인이 느림 (Slower Edge Existence Check):
- 간선 확인 시 리스트를 순회해야 함.
구현 복잡도 증가 (Increased Implementation Complexity):
- 연결 리스트에 가중치까지 포함하므로 데이터 구조 관리가 복잡.
✅인접 리스트를 이용한 방법의 장단점 (Advantages and Disadvantages of Using Adjacency List)
💡요약: 인접 리스트 (Adjacency List)는 그래프를 표현할 때, 간선의 밀도가 낮은 경우(희소 그래프) 공간 효율적이며, 필요한 정보만 저장 (Stores only required information). 그러나 간선 존재 여부를 확인하거나 리스트를 구축할 때 성능의 제약이 있을 수 있다..
장점 (Advantages)
공간 효율적 (Space Efficiency):
간선의 총수에 비례하여 공간을 사용.
불필요한 0 값을 저장하지 않으므로 공간 낭비 없음 (No wasted space).
공간 복잡도: O(V+E) (정점 V, 간선 E).
희소 그래프에서 효율적 (Efficient for Sparse Graphs):
- 간선이 적을수록 메모리를 아낄 수 있음.
단점 (Disadvantages)
리스트를 구축하는 오버헤드 (Overhead of Constructing the List):
- 그래프 데이터를 리스트 형태로 변환하는 데 초기 작업이 필요.
간선 존재 여부 확인의 비효율성 (Inefficient Edge Existence Check):
특정 간선이 존재하는지 확인하려면, 리스트를 순회해야 함.
시간 복잡도: 최악의 경우 O(n) (정점 n).
밀도가 높은 그래프에서는 성능 저하 (Poor Performance for Dense Graphs):
- 모든 노드가 서로 연결된 그래프에서는 관리 복잡성이 증가.
그래프 표현 #7: 인접 배열을 이용한 방법 (Graph Representation Using Adjacency Array)
💡요약: 인접 배열 (Adjacency Array)은 그래프의 정점 간 연결 정보를 배열로 효율적으로 표현 (Represents vertex connections using arrays efficiently)한다. 인접 리스트와 유사하지만, 리스트 대신 배열을 사용하여 정점들을 저장한다. 헤더(Header)를 통해 각 정점의 인접 정점 개수를 표시하며, 리스트 오버헤드를 줄이고 빠른 접근을 제공한다.
✅ 인접 배열의 정의 (Definition of Adjacency Array)
정점(Node)마다 연결된 정점들을 배열(Array)로 저장.
헤더(Header)는 각 정점의 인접 정점 개수를 나타낸다.
연결된 정점 정보를 순차적으로 저장하므로, 연속된 메모리 공간을 사용.
효율적인 경우: 네트워크 연결 정보 저장할 경우 유용하다. 고정된 네트워크 구조에서 빠른 연결 확인 필요 시이다. 예) 도시 간 연결된 도로가 거의 변하지 않을 경우.
비효율적인 경우: 가변 그래프, 즉 간선 추가와 삭제가 빈번한 경우엔 비효율 적이다.

노드(Node): 철수(1), 영희(2), 동근(3), 준호(4), 재상(5), 승우(6).
헤더(Header):
철수(1): 인접 정점 개수 = 4, 배열 시작 위치 = 1.
영희(2): 인접 정점 개수 = 2, 배열 시작 위치 = 5.
동근(3): 인접 정점 개수 = 3, 배열 시작 위치 = 7.
준호(4): 인접 정점 개수 = 2, 배열 시작 위치 = 10.
재상(5): 인접 정점 개수 = 2, 배열 시작 위치 = 12.
승우(6): 인접 정점 개수 = 3, 배열 시작 위치 = 14.
- 배열 시작 위치 정하는 기준: 영희(2)의 인접 정점 리스트
[1, 3]은 두 개의 칸을 차지하므로 영희의 배열은5~6이고 동근(3)의 배열 시작 위치는 7로 설정된다.
- 배열 시작 위치 정하는 기준: 영희(2)의 인접 정점 리스트
배열(Array):
철수(1): [2, 3, 4, 6]
영희(2): [1, 3]
동근(3): [1, 2, 5]
준호(4): [1, 6]
재상(5): [3, 6]
승우(6): [1, 4, 5]
✅ 장점 (Advantages)
메모리 효율성 (Memory Efficiency):
리스트 포인터를 저장하지 않아 메모리 사용량 감소.
간선 밀도가 낮을 경우 공간 절약.
빠른 접근성 (Fast Access):
- 두 정점의 인접 여부를 빠르게 확인 가능.
연속된 메모리 구조 (Contiguous Memory Structure):
- 배열을 사용하므로 메모리 캐시 활용 가능.
단점 (Disadvantages):
정적 구조 (Static Structure):
- 배열 크기가 고정되므로, 간선 추가나 삭제가 어렵고 유연성이 떨어짐.
초기 설정의 복잡성 (Complex Initial Setup):
- 배열 초기화와 헤더 설정이 필요.
그래프 표현 #8: 인접 배열을 하나의 큰 배열로 처리 (Processing Adjacency Array as a Single Large Array)
💡요약: 인접 배열을 하나의 큰 배열에 통합 저장 (Stores adjacency information in a single large array)한다. 각 정점(Node)의 인접 정점 시작 위치를 헤더(Header)로 저장하여 효율적으로 접근한다. 이 방식은 메모리와 연산 효율성을 동시에 고려한 데이터 구조이다.
✅ 구조 설명
큰 배열 (Single Large Array):
모든 정점의 인접 정보를 하나의 큰 배열에 저장.
연결된 모든 정점 정보가 순차적으로 나열됨.
헤더 (Header):
각 정점의 인접 정점 정보가 배열의 어디서 시작하는지 인덱스(Index)로 표시.
예) 철수(1)의 인접 정점 정보는 4번 인덱스부터 시작, 영희(2)의 인접 정점 정보는 9번 인덱스부터 시작
효율적인 경우와 비효율 적인 경우의 예는 인접 배열과 동일하다.

노드(Node): 철수(1), 영희(2), 동근(3), 준호(4), 재상(5), 승우(6).
큰 배열 내용:
철수(1): [2, 3, 4, 6]
영희(2): [1, 3]
동근(3): [1, 2, 5]
준호(4): [1, 6]
재상(5): [3, 6]
승우(6): [1, 4, 5]
헤더(Header):
철수(1): 시작 인덱스 = 4.
영희(2): 시작 인덱스 = 9.
동근(3): 시작 인덱스 = 11.
준호(4): 시작 인덱스 = 13.
재상(5): 시작 인덱스 = 16.
✅ 장점 (Advantages)
공간 효율성 (Space Efficiency):
- 연결 정보를 하나의 배열에 통합하여 공간 낭비를 최소화.
빠른 접근성 (Fast Access):
- 헤더를 통해 특정 정점의 인접 정점 정보에 바로 접근 가능.
캐시 효율성 (Cache Efficiency):
- 연속된 메모리 구조로 캐시 활용 최적화.
✅ 단점 (Disadvantages):
정적 구조 (Static Structure):
- 간선 추가나 삭제 시 배열을 재구성해야 하는 비효율성.
구현 복잡성 (Implementation Complexity):
- 헤더와 배열의 동시 관리가 필요.
그래프 표현 #9: 인접 해시 테이블 (Adjacency Hash Table)
💡요약: 인접 해시 테이블은 그래프의 규모가 크거나 간선 검색 속도가 중요한 경우 사용되는 자료구조이다. 인접 리스트의 한계를 보완하며, 정점 간 관계를 해시 테이블로 관리한다.임의의 두 정점이 연결되었는지 빠르게 확인하는 데 유리하다.
✅ 인접 해시 테이블의 정의
각 정점(Node)에 대해 해시 테이블을 사용하여 연결된 정점과 간선을 저장.
키(Key): 연결된 정점 번호.
값(Value): 간선의 가중치 또는 연결 여부.
✅ 특징
빠른 검색 속도 (Fast Search Time):
- 해시 테이블의 특성상 평균 O(1)의 시간 복잡도로 간선 여부를 확인 가능.
공간 효율성 (Space Efficiency):
- 필요한 간선 정보만 저장하므로 메모리 절약.
대규모 그래프에 적합 (Suitable for Large Graphs):
- 정점과 간선의 수가 많아질수록 효과적.
✅ 사용 사례
두 정점이 연결되었는지 확인: 임의의 두 정점 A와 B가 연결되었는지 빠르게 검색.
- 예) 해시 테이블에서 A의 키가 B인지 확인 → 연결 여부 반환.
가중치 저장 및 검색: 두 정점 간 간선의 가중치 정보를 함께 저장.
- 예: A → B 간선의 가중치가 10이면, 해시 테이블에서 Hash[A][B] = 10.
✅ 장점 (Advantages):
검색 속도: 인접 리스트보다 빠르게 간선 검색 가능 (O(1)).
공간 효율성: 저장 공간이 간선의 수에 비례 (O(E)).
대규모 그래프에서 효율적: 정점이 많고, 간선 확인이 중요한 경우 적합.
✅ 단점 (Disadvantages):
구현 복잡성: 해시 테이블 관리를 위한 추가 코드가 필요.
해시 충돌: 해시 충돌 발생 시 성능 저하 가능.
동적 할당 비용: 해시 테이블의 동적 크기 조정으로 인한 오버헤드.
그래프 표현 #10: 에지 리스트 - 단순 그래프 (Edge List - Simple Graph)
💡요약: 에지 리스트 (Edge List)는 그래프를 간선(Edge)을 중심으로 표현 (Represents the graph by focusing on edges)한다. 각 간선의 출발 노드와 도착 노드를 두 개의 값으로 저장하여 그래프의 연결 정보를 관리한다. 간선에 대한 정보를 저장하므로, 정점과 간선의 정보를 간단하고 명확하게 표현할 수 있다.
✅ 에지 리스트의 정의 (Definition of Edge List)
그래프의 모든 간선을 하나의 리스트로 저장.
각 간선은 출발 노드와 도착 노드로 구성.
단순 그래프의 경우, 간선에 가중치가 포함되지 않음.
효율적인 경우는 네트워크 케이블 연결 정보 같은 간선 중심의 작업이다. 반대로 비효율적인 경우는 특정 노드의 인접 노드를 자주 탐색해야 하는 노드 중심 작업에서 비효율적이다.
효율적인 경우는 도시 간 이동거리(가중치)를 저장하며 간선 중심의 작업이 필요한 경우이다. 예를 들어 도시 A → 도시 B (50km), 도시 C → 도시 D (100km) 반대로 비효율적인 경우는 노드 중심의 그래프 탐색시이다. 특정 노드의 인접 노드나 간선을 자주 탐색해야하는 경우 비효율적이다.

노드(Node): 1, 2, 3, 4, 5.
간선(Edge):
1 → 2
1 → 3
3 → 4
2 → 4
2 → 5
4 → 5
✅ 장점 (Advantages):
단순하고 직관적인 구조 (Simple and Intuitive Structure):
- 간선만 저장하여 표현 방식이 단순.
공간 효율성 (Space Efficiency):
- 필요한 간선 정보만 저장하므로 메모리 절약.
✅ 단점 (Disadvantages):
간선 존재 여부 확인이 비효율적 (Inefficient Edge Existence Check):
- 특정 간선이 존재하는지 확인하려면 리스트 전체를 탐색해야 함 (O(E)O(E)O(E)).
인접 노드 탐색의 비효율성 (Inefficient Neighbor Lookup):
- 특정 노드의 인접 노드를 탐색하려면 모든 간선을 확인해야 함.
그래프 표현 #11: 에지 리스트 - 가중치 그래프 (Edge List - Weighted Graph)
💡요약: 에지 리스트 (Edge List)는 가중치 그래프의 출발 노드, 도착 노드, 가중치를 저장하는 방법이다. 간선을 중심으로 가중치 정보까지 포함하여 세 가지 값을 저장한다.
✅ 에지 리스트의 정의 (Definition of Edge List)
그래프의 모든 간선을 하나의 리스트로 저장.
각 간선은 출발 노드, 도착 노드, 가중치로 표현.

노드(Node): 1, 2, 3, 4, 5.
간선(Edge):
1 → 2 (가중치 8).
1 → 3 (가중치 3).
3 → 4 (가중치 13).
2 → 4 (가중치 4).
2 → 5 (가중치 15).
4 → 5 (가중치 2).
✅ 장점 (Advantages):
구조가 단순 (Simple Structure):
- 간선의 정보만 저장하여 관리가 간편.
가중치 포함 (Supports Weights):
- 간선의 가중치 정보를 추가로 저장 가능.
공간 효율성 (Space Efficiency):
- 필요하지 않은 0 값을 저장하지 않으므로 메모리 절약.
단점 (Disadvantages):
간선 탐색 속도 저하 (Slower Edge Search):
- 특정 간선을 찾기 위해 리스트 전체를 탐색해야 함 (O(E)).
인접 노드 탐색의 비효율성 (Inefficient Neighbor Lookup):
- 특정 노드에 연결된 모든 간선을 탐색하려면 전체 리스트를 확인해야 함.

너비 우선 탐색과 깊이 우선 탐색 (Breadth First Search and Depth First Search)
너비 우선 탐색 (BFS): 정점을 계층적으로 탐색하며, 최단 경로 문제에 유리.
깊이 우선 탐색 (DFS): 한 방향으로 깊이 탐색하며, 모든 경로 탐색 문제에 적합.
차이점: 탐색 순서와 사용 데이터 구조(Queue vs Stack/Recursive).
✅너비 우선 탐색과 깊이 우선 탐색 비교 (Comparison of Breadth First Search and Depth First Search)
💡요약: 너비 우선 탐색 (BFS)과 깊이 우선 탐색 (DFS)은 그래프를 탐색하는 두 가지 주요 방법으로, 각각의 방식이 독립적으로 유용하지만, 복잡한 알고리즘에서도 핵심적인 역할을 한다. 두 알고리즘 모두 그래프의 모든 정점을 방문 (Visit all nodes in the graph)하며, 시간 복잡도는 동일하게 O(V+E)이다.
BFS: FIFO 방식으로 먼저 들어온 데이터를 먼저 처리.
DFS: LIFO 방식으로 마지막에 들어온 데이터를 먼저 처리.
✅공통점 (Common Features)
두 알고리즘 모두 완전 탐색 알고리즘 (Complete Search Algorithms)으로, 그래프의 모든 정점을 방문한다.
시간 복잡도는 정점 수 V와 간선 수 E를 기준으로 O(V+E)이다.
V: 정점(Vertex) 수.
E: 간선(Edge) 수.
탐색할 노드 번호가 여러 개일 경우, 작은 번호의 노드부터 탐색한다.
그래프는 무향 그래프(Undirected Graph)로, 간선의 방향은 없다.
✅ 너비 우선 탐색 (Breadth First Search)
의미: 정점에서 출발하여 가장 가까운 정점부터 탐색 (Start from a node and explore the nearest nodes first).
특징:
계층적 탐색: 한 레벨의 모든 정점을 방문 후 다음 레벨로 이동.
큐(Queue)를 사용: 자료구조를 사용해서 탐색 순서를 관리한다.
사용 예:
최단 경로 문제 (Shortest Path Problems).
네트워크에서 최소 연결 탐색.
데이터를 FIFO (First In, First Out) 방식으로 처리한다.
✅ 깊이 우선 탐색 (Depth First Search)
의미: 정점에서 출발하여 한 방향으로 가장 깊이 탐색 (Start from a node and explore deeply in one direction).
특징:
재귀적 탐색: 깊이 탐색 후 돌아와서 다음 경로 탐색. 즉 한 경로를 끝까지 탐색한 뒤, 다시 돌아와 다음 경로를 탐색한다는 뜻이다.
스택(Stack) 또는 재귀(Recursive)를 사용.
사용 예:
모든 경로 탐색.
퍼즐이나 미로 문제에서 경로 찾기.
데이터를 LIFO (Last In, First Out) 방식으로 처리한다.


4️⃣너비 우선 탐색 (Breadth First Search)
💡요약: 너비 우선 탐색 (Breadth First Search, BFS)은 가까운 정점부터 차례대로 탐색 (Visit nodes level by level)을 수행한다. 방문한 정점은 다시 방문하지 않으며, 탐색 경로를 트리 형태로 시각화할 수 있다.
✅BFS의 특징
가까운 정점부터 탐색 (Explore nearest nodes first):
- 레벨별로 탐색하여 계층적인 구조로 진행.
큐(Queue)를 사용 (Uses a queue):
- 방문할 정점을 저장하여 순서대로 처리.
한 번 방문한 정점은 다시 방문하지 않음 (Does not revisit nodes):
- 이미 방문한 정점은 무시하여 무한 루프 방지.
트리 구조로 표현 가능 (Can be visualized as a tree):
- 탐색 과정을 트리 형태로 나타냄.

BFS 탐색 경로: 1 → 2 → 3 → 4 → 5 → 6 → 7 → 8
시작 정점:
정점 1에서 탐색을 시작.
- 인접한 정점 2, 3, 4를 큐에 추가.
1단계 탐색 (Level 1):
정점 2, 3, 4를 방문.
2번 노드: 더 이상 연결된 노드 없음.
3번 노드: 5와 연결 → 큐에 추가.
4번 노드: 6, 7과 연결 → 큐에 추가.
2단계 탐색 (Level 2):
정점 5, 6, 7을 방문.
6번 노드: 8과 연결 → 큐에 추가.
5, 7번 노드: 더 이상 연결된 노드 없음.
3단계 탐색 (Level 3):
- 정점 8을 방문하고 종료.
너비 우선 탐색 #1: 의사코드 (Pseudocode for Breadth First Search)
💡요약: 너비 우선 탐색 (Breadth First Search, BFS)의 의사코드는 알고리즘이 어떻게 작동하는지 단계별로 설명한다. BFS는 모든 정점을 방문 (Visit every node in the graph)하며, 한 번 방문한 정점은 다시 방문하지 않도록 처리하는데 이 과정을 큐(Queue) 자료구조를 사용하여 관리된다.

초기화 (Initialization):
모든 정점의 방문 상태를 초기화: v.visited←NO
- 이는 방문 여부를 추적하기 위함이다.
시작 정점 s를 방문 표시: s.visited ← YES
- 방문한 정점은 큐에 추가: enqueue(Q,s)
탐색 반복 (Main Loop):
큐가 비어있지 않은 동안 반복: while(Q≠∅)
큐에서 정점을 하나 꺼냄: u ← dequeue(Q)\
u에 연결된 모든 인접 정점을 확인:
방문하지 않은 정점만 탐색: if(v.visited←NO)
방문 상태 업데이트: v.visited←YES
방문한 정점을 큐에 추가: enqueue(Q,v)
종료 조건 (Termination):
- 모든 정점을 방문하면 알고리즘이 종료된다.
너비 우선 탐색 : 자료 구조 1 (Breadth First Search Data Structure Operation 1 )
💡요약: 너비 우선 탐색 (Breadth First Search, BFS)에서 자료구조 초기화가 어떻게 이루어지는지를 보여준다. BFS는 탐색 과정에서 인접 리스트 (Adjacency List), 방문 리스트 (Visited List), 그리고 큐 (Queue)를 사용해 정점을 체계적으로 탐색한다.
✅ 핵심 특징:
BFS는 정점을 체계적으로 탐색하며, 한 번 방문한 정점을 다시 방문하지 않는다.
큐와 방문 리스트를 사용하여 효율적으로 탐색 경로를 관리한다.
방문 리스트를 False로 초기화하고, 시작점만 True로 설정한다.
큐에 시작점을 추가하여 탐색 준비 완료한다.

원본 그래프 (Graph): 탐색을 시작할 정점을 선택한다. 예) 시작점 1.
인접 리스트 (Adjacency List): 그래프의 모든 노드와 해당 노드에 연결된 정점들을 저장한다.
- 1→[2,3] / 2→[5,6] / 3→[4] / 4→[6] / 5→[ ] / 6→[ ]
방문 리스트 초기화 (Visited List Initialization):
모든 정점의 방문 여부를 False로 초기화한다.
시작점은 True로 표시한다.
예: [T,F,F,F,F,F]
큐 초기화 (Queue Initialization):
탐색할 정점을 큐(Queue)에 추가한다.
탐색 정점이 1부터 시작이기 때문에 시작점 1을 큐에 넣었다. 예) [1].
너비 우선 탐색 #2: 자료 구조 2 (Breadth First Search Data Structure Operation 2 )
💡요약: 너비 우선 탐색 (Breadth First Search, BFS)은 큐(Queue)를 사용하여 정점들을 탐색하고, 탐색한 정점의 인접 노드를 다시 큐에 추가한다. 방문한 정점은 방문 리스트(Visited List)를 통해 체크하며, 탐색 순서를 효율적으로 관리한다.

큐에서 노드 꺼내기 (Dequeue a Node): 큐에서 정점을 하나 꺼낸다.
- 예) 1번 정점을 큐에서 꺼냄.
탐색 순서 기록 (Record Traversal Order): 순차적으로 정점을 탐색한다. 꺼낸 정점을 탐색 순서에 기록한다.
- 예) 현재 탐색 순서 → 1
인접 노드 확인 및 큐에 추가 (Check Adjacent Nodes and Enqueue)
인접 리스트를 확인하여 꺼낸 정점에 연결된 모든 노드를 확인.
아직 방문하지 않은 노드를 큐에 추가한다. 정점을 FIFO 방식으로 처리하기 때문에 3, 2 가 된다.
예: 1번 정점의 인접 노드 → 2, 3
- 이 노드들을 큐에 삽입: enqueue(Q,2), enqueue(Q,3)
방문 리스트 업데이트 (Update Visited List)
방문한 정점을 True로 체크하여 한번만 방문하도록 중복 방문 방지한다.
예: 2,3 / 정점 방문 상태 → T
너비 우선 탐색 #2: 자료 구조 3 (Breadth First Search Data Structure Operation 3 )
💡요약: 너비 우선 탐색 (Breadth First Search, BFS)은 큐(Queue) 자료구조를 활용하여 모든 정점을 순서대로 방문하며, 방문한 정점의 인접 노드를 다시 큐에 추가하게 된다. 큐가 비어질 때까지 탐색을 반복 (Repeat until the queue is empty)하며, 모든 노드를 방문하면 탐색이 종료된다.
✅BFS의 특징
FIFO 방식 탐색 (FIFO Traversal):
- 가장 먼저 들어간 노드를 가장 먼저 탐색.
모든 노드 방문 (Visits All Nodes):
- 모든 정점을 방문한 후 종료.
중복 방문 방지 (Avoids Revisit):
- 이미 방문한 노드는 큐에 추가하지 않음.

탐색 순서: 1 → 2 → 3 → 5 → 6 → 4
큐(Queue): 빈 상태 (모든 노드 방문 완료).
방문 리스트(Visited List): [T,T,T,T,T,T] → 모든 노드 방문.
큐에서 노드 꺼내기 (Dequeue a Node):
큐의 가장 앞에 있는 노드를 꺼낸다. (FIFO 방식).
첫 번째 노드: 1
1 과 연결된 2, 3번 노드를 큐에 추가한다.
방문하지 않은 노드 추가 (Add Unvisited Nodes):
5번 노드, 6번 노드는 아직 방문하지 않았으므로 큐에 삽입.
방문 리스트 업데이트: 5→True
노드의 연결 확인 후 종료 (Check and Stop):
- 4번 노드는 더 이상 연결된 노드가 없으므로 큐에서 제거 후 다음 노드로 이동.
이미 방문한 노드 건너뛰기 (Skip Visited Nodes):
- 6번 노드는 이미 방문된 상태이므로 다시 큐에 삽입하지 않음.
탐색 종료 (End of Traversal):
- 큐가 비어 모든 노드를 방문했으므로 탐색이 종료된다.
5️⃣깊이 우선 탐색 (Depth First Search)
✅BFS의 특징
데이터를 LIFO (Last In, First Out) 방식으로 처리.
재귀적 탐색 (Recursive Traversal): 한 방향으로 계속 탐색하며, 더 이상 탐색할 노드가 없으면 이전 노드로 되돌아간다.
스택 구조 활용 (Uses Stack Structure): 호출 스택 또는 명시적인 스택을 사용해 이전 노드로 돌아가는 동작을 관리한다.
한 경로를 끝까지 탐색한 뒤, 검색할 경우가 없을 경우 다시 돌아와 다음 경로를 탐색한다. 선형 구조처럼 이어지며 동작한다.
사용 가능 한 예로는 모든 가능한 경로 탐색 및 퍼즐, 미로 탐색 문제가 있다.
너비우선탐색(BFS)와 마찬가지로 시간 복잡도는 O(V+E)이다.
깊이 우선 탐색 #1 : 예 1/2 (Example of Depth First Search 1/2)

첫 번째 이미지 (a~e)
시작점 설정 (Start Point): 1번 노드에서 탐색 시작.
첫 번째 경로 탐색 (First Path):
1→2→3→4→5 순서로 이동.
깊이 우선 탐색 특징: 한 노드에서 연결된 다른 노드로 계속 이동하며 가능한 가장 깊은 경로를 우선 탐색.
더 이상 탐색 불가 상태 (No More Path):
5번 노드는 추가로 연결된 노드가 없으므로 탐색 종료 후 뒤로 돌아감.
2번 노드는 이미 검색한 노드이므로 진행하지 않는다.
깊이 우선 탐색 #2 : 예 2/2 (Example of Depth First Search 2/2)

두 번째 이미지 (f~h)
다음 경로 탐색 (Next Path):
6번 노드부터 새 경로 탐색 시작.
6→7→8순서로 이동.
이미 방문한 노드는 건너뜀 (예: 2번 노드).
탐색 종료 (End of Traversal):
모든 노드를 방문한 후 탐색 종료.
최종 탐색 경로: 1→2→3→4→5→6→7→8
깊이 우선 탐색 #3 : 의사코드 (Pseudocode for Depth First Search)

방문 표시 (Mark as Visited):
- 현재 노드 v를 방문했음을 기록: v.visited ← YES
인접 노드 탐색 (Explore Adjacent Nodes):
v의 인접 노드 목록 v.adjlist를 순회.
아직 방문하지 않은 노드 x에 대해 재귀 호출: DFS(x)
재귀 호출 뜻: 한 방향으로 계속 탐색하며, 더 이상 탐색할 노드가 없으면 이전 노드로 되돌아간다.
스택 구조 활용 (Stack-Like Structure):
함수 호출이 스택(Stack)처럼 작동하여 이전 노드로 되돌아가는 구조를 형성한다.
호출 스택 또는 명시적인 스택을 사용해 이전 노드로 돌아가는 동작을 관리하는 것을 스택이라고 한다.
깊이 우선 탐색 # 4: 자료구조 작동 방식 (Depth First Search Data Structure Operation)
💡요약: 깊이 우선 탐색(DFS)은 스택(Stack) 자료구조를 활용해 정점을 탐색하며, 탐색이 끝나면 다음 노드를 스택에서 꺼내 다시 탐색을 진행한다. 모든 정점을 방문할 때까지 반복하며, 각 정점의 상태를 방문 리스트(Visited List)로 관리한다.

초기화 과정
시작점 설정 (Start Point):
- 1번 노드를 시작점으로 설정.
자료구조 초기화:
인접 리스트 (Adjacency List): 그래프에서 각 노드와 연결된 정점을 저장한다.
방문 리스트 (Visited List): 시작점만 T = true, 나머지는 F = False로 초기화.
스택 (Stack): 1번 노드를 삽입.

탐색 진행
스택에서 노드 꺼내기 (Dequeue Node):
스택에서 가장 위에 있는 1번 노드를 꺼냄.
방문 리스트 업데이트: 1 → True
인접 노드 삽입 (Insert Adjacent Nodes):
1번 노드와 연결된 2,3번 노드를 스택에 삽입한다. (데이터를 LIFO (Last In, First Out) 방식으로 처리한다)
스택 상태: [2,3]
방문 리스트 업데이트: 2,3→T

재귀적 탐색
스택에서 노드 꺼내기:
스택의 맨 위 노드 3을 꺼냄.
3번 노드의 인접 노드 4를 스택에 삽입.
방문 리스트 업데이트: 4→T
다음 탐색 진행:
스택에서 4를 꺼내고, 4와 연결된 6번 노드를 스택에 삽입.
방문 리스트 업데이트: 6→T
탐색 종료 조건:
6번 노드는 더 이상 연결된 노드가 없으므로 스택에서 제거.
이전 노드로 되돌아가 다른 경로 탐색.
깊이 우선 탐색 # 5: DFS와 BFS 프로그램 (DFS and BFS Program Explanation)
💡요약: 그래프 탐색 알고리즘인 DFS(깊이 우선 탐색)와 BFS(너비 우선 탐색)의 결과를 출력하는 프로그램의 구조와 동작 방식 알아본다.
✅ 개요
이 프로그램은 DFS와 BFS 알고리즘을 사용해 그래프를 탐색하고 탐색 결과를 출력한다.
탐색은 주어진 그래프의 노드와 간선을 기반으로 수행된다.
✅ 규칙
탐색할 노드 번호가 여러 개일 경우, 작은 번호의 노드부터 탐색한다.
그래프는 무향 그래프(Undirected Graph)로, 간선의 방향은 없다.
✅입력
- 1번째 줄에 노드의 개수, 에지의 개수, 탐색할 노드 번호 그 다음 M개의 줄에는 에지가 연결하는 두 노드번호가 주어진다. (무향)
✅ 출력
- 1번째 줄에 DFS결과(스택 구조 또는 재귀 호출로 구현), 그 다음 줄에 BFS 결과(큐 구조로 구현)

예제1
- DFS 탐색 경로: 시작점 1에서 가장 깊이 있는 2 → 4 → 3 순으로 탐색.
- BFS 탐색 경로: 시작점 1에서 인접 노드 2, 3, 4를 계층적으로 탐색.
예제2
DFS 탐색 경로: 시작점 3에서 가장 깊이 있는 1 → 2 → 5 → 4 순으로 탐색.
BFS 탐색 경로: 시작점 3에서 인접 노드 1, 4, 2, 5를 계층적으로 탐색.
깊이 우선 탐색 # 6: DFS와 BFS 프로그램 - 손으로 풀기 (Solving DFS and BFS by Hand)
💡요약: DFS(깊이 우선 탐색)와 BFS(너비 우선 탐색)를 손으로 수행하는 과정이다. 인접 리스트를 먼저 구축한 후, DFS는 재귀 호출 방식, BFS는 큐 방식으로 탐색을 진행하며 방문 순서를 기록한다. DFS는 깊이 우선, BFS는 너비 우선 방식으로 탐색 결과를 도출한다.
DFS vs BFS 탐색 방식 비교
✅ DFS (깊이 우선 탐색): 한 방향으로 끝까지 탐색 후 되돌아가는 방식이다. 재귀 호출/스택을 기반으로 한다.
✅ BFS (너비 우선 탐색): 인접 노드를 먼저 탐색하며 계층적으로 진행한다. 큐를 기반으로 한다.

각 노드와 연결된 모든 노드를 표현한다.

재귀 함수 호출 (Recursive Calls):
- DFS는 재귀적으로 노드를 방문한다.
- 방문한 노드를 방문 리스트에 표시한다.
탐색 순서 (Depth First Search):
Depth 1: 1번 노드 방문.
Depth 2: 2번 노드 방문.
Depth 3: 4번 노드 방
Depth 4: 3번 노드 방문.
탐색 종료:
- 모든 노드를 방문한 후 탐색 종료.
DFS 탐색 경로:
- 1→2→4→3

큐 자료구조 사용 (Queue Data Structure):
- BFS는 큐를 사용해 인접 노드를 먼저 탐색한다.
- 큐에 노드를 삽입하고, 꺼내며 탐색을 진행한다.
탐색 순서 (Breadth First Search):
Depth 1: 1번 노드 방문.
Depth 2: 2,3,4번 노드 방문.
탐색 종료:
- 큐가 비어 모든 노드를 방문한 후 탐색 종료.
BFS 탐색 경로:
- 1→2→3→4
깊이 우선 탐색 # 7: 의사코드 설명 (DFS and BFS Program - Pseudocode Explanation)
💡요약: 노드와 간선 정보를 입력받아 두 가지 탐색 방식을 통해 결과를 출력하는 과정을 간략히 설명한다.
DFS 동작: 현재 노드를 출력 → 방문 리스트 기록 → 연결된 노드 재귀 호출.
BFS 동작: 시작 노드를 큐에 삽입 → 큐에서 노드 꺼내기 → 연결된 노드 삽입.
특징:
DFS는 재귀 호출을 기반으로 하며, 스택 구조로 동작.
BFS는 큐 자료구조를 사용하여 탐색.
✅입력과 데이터 정리

노드와 간선 정보 입력 받기 (Input Nodes and Edges):
- 노드의 개수 N, 간선의 개수 M, 시작 노드 Start의 입력값을 받는다.
그래프 데이터 저장 (Store Graph Data):
- 인접 리스트 (Adjacency List) 형태로 그래프를 저장한다. 이곳에는 각 노드의 연결 정보를 기록한다.
노드 정렬 (Sort Nodes):
- 방문할 수 있는 노드가 여러 개일 경우, 작은 번호의 노드부터 방문하기 위해 정렬한다.
✅ DFS 구현 (Depth First Search Implementation)

현재 노드 출력 (Print Current Node):
- 현재 탐색 중인 노드를 출력한다.
방문 리스트 업데이트 (Update Visited List):
- 방문한 노드를 방문 리스트에 기록한다.
재귀 호출 (Recursive Calls):
- 현재 노드의 인접 노드 중 방문하지 않은 노드를 대상으로 재귀적으로 DFS 호출을 수행한다.
초기화 및 실행 (Initialize and Run):
방문 리스트 초기화 (Initialize Visited List):
모든 노드의 방문 상태를 초기화한다.DFS 탐색을 시작점에서 실행한다.

큐에 시작 노드 삽입 (Insert Start Node in Queue):
- BFS는 큐 자료구조를 사용한다. 시작 노드를 큐에 삽입한다.
방문 리스트 업데이트 (Update Visited List):
- 방문한 노드를 방문 리스트에 기록한다.
큐에서 데이터 가져오기 (Dequeue Data):
- 큐가 빌 때까지 노드를 꺼내고 탐색을 진행한다.
인접 노드 삽입 (Insert Adjacent Nodes):
- 현재 노드와 연결된 노드 중 방문하지 않은 노드를 큐에 삽입한다.
초기화 및 실행 (Initialize and Run):
방문 리스트 초기화 (Initialize Visited List):
모든 노드의 방문 상태를 초기화한다.BFS 탐색을 시작점에서 실행한다.
깊이 우선 탐색 # 8: 파이썬 코드 (DFS and BFS Program in Python)
✅ 입력 및 그래프 데이터 저장 (Input and Graph Representation)

from collections import deque
- deque: BFS에서 사용할 큐(queue) 자료구조를 불러온다.
N, M, Start = map(int, input().split())
N(노드 수), M(간선 수), Start(시작 노드)를 입력받는다.
map(int, input().split())은 문자열 입력을 정수로 변환한다.
A = [[] for _ in range(N + 1)]
- 인접 리스트 초기화 (Initialize Adjacency List): 각 노드의 연결 정보를 저장할 리스트 A를 만든다.
for _ in range(M):
s, e = map(int, input().split())
A[s].append(e) # 양방향 간선이므로 s → e 추가
A[e].append(s) # 양방향 간선이므로 e → s 추가
- 간선 추가 (Add Edges): 입력받은 두 노드 s와 e를 서로 연결한다. 양방향 그래프이므로 서로 추가해야 한다.
for i in range(N + 1):
A[i].sort()
- 노드 정렬 (Sort Nodes): 방문할 수 있는 노드가 여러 개일 경우, 작은 번호부터 탐색하기 위해 정렬한다.
✅ DFS구현(Depth First Search)

DFS 함수: 현재 노드를 출력하고, 방문 여부를 기록한다. 인접 노드를 순서대로 탐색하며, 방문하지 않은 노드를 재귀적으로 호출한다.
visited = [False] * (N + 1) # 방문 리스트 초기화
DFS(Start)
DFS 실행: 방문 리스트를 초기화하고, 시작 노드 Start에서 탐색을 시작한다.
✅BFS 구현 (Breadth First Search)

- BFS 함수: 큐를 사용해 너비 우선으로 탐색한다. 큐에 노드를 삽입하고 꺼내며, 인접 노드를 방문한다.
visited = [False] * (N + 1) # 방문 리스트 초기화
BFS(Start) # BFS 탐색 시작
- BFS 실행: 방문 리스트를 초기화하고, 시작 노드 Start에서 탐색을 시작한다.
6️⃣최소 신장 트리(Shortest Spanning Tree)
✅ 신장 트리 (Spanning Tree)
정의 (Definition): 무향 연결 그래프(Undirected Connected Graph) G=(V,E) 에서 정점 집합 V를 그대로 두고, 간선을 최소로 선택하여 사이클이 없는 트리(Tree)를 구성한 것. 모든 정점이 서로 연결되어야 한다.
특징 (Characteristics):
- 간선의 수 = ∣V∣−1, |V|: 정점의 수.
✅ 최소 신장 트리 (Minimum Spanning Tree)
정의 (Definition): 간선들의 가중치 합이 최소가 되는 신장 트리이다.
목적 (Purpose): 모든 정점을 연결하면서 최소 비용으로 연결하는 트리 구조를 찾는 것.
- 예를 들어, 도시를 연결하는 도로 네트워크를 설계할 때 비용을 최소화하는 데 사용된다.
💡요약
✅ 신장 트리 (Spanning Tree):
모든 정점을 포함하고, 정점 간 경로가 존재하며, 사이클이 없는 트리.
간선의 수는 ∣V∣−1
✅ 최소 신장 트리 (Minimum Spanning Tree):
가중치가 있는 그래프에서 간선 가중치의 합이 최소가 되는 신장 트리.
모든 정점을 연결하면서 비용을 최소화하는 데 사용된다.
최소 신장 트리 #1: 알고리즘 간 비교 (Comparison of Minimum Spanning Tree Algorithms)
💡요약: 최소 신장 트리를 찾는 대표적인 두 알고리즘인 프림(Prim)과 크루스칼(Kruskal) 알고리즘의 차이점과 특징을 설명한다. 두 알고리즘은 모두 그리디 알고리즘(Greedy Algorithm)으로 현재 상황에서 가장 좋은 선택을 하며 진행된다.
✅ 프림 알고리즘 (Prim's Algorithm)
탐색 기준 (Search Focus):
- 정점 중심 (Vertex-Based): 시작 정점에서 출발해 인접한 간선 중 가장 작은 가중치를 가진 간선을 선택해 트리를 확장해 나간다.
해결 방식 (Solution Process):
하나의 트리에서 시작하여 점차적으로 트리를 확장하는 방식이다.
깊이 우선 탐색(DFS)과 유사한 방식으로 동작한다.
사이클 판단 (Cycle Detection):
- 정점 중심으로 진행하므로 별도의 사이클 확인 과정이 필요하지 않다.
✅ 크루스칼 알고리즘 (Kruskal's Algorithm)
탐색 기준 (Search Focus):
- 간선 중심 (Edge-Based): 모든 간선을 가중치에 따라 정렬한 뒤, 가중치가 낮은 간선부터 선택하여 트리를 만든다.
해결 방식 (Solution Process):
- 여러 트리를 생성한 뒤, 트리를 점차 합쳐서 하나의 최소 신장 트리를 완성한다.
사이클 판단 (Cycle Detection):
간선을 선택할 때 유니온-파인드(Union-Find) 알고리즘을 사용해 사이클이 발생하는지 확인한다.
사이클이 생기지 않는 간선만 선택한다.
✅ 공통점
복잡도 (Complexity): 둘 다 O(E \log V) 복잡도를 가진다. (E: 간선 수, V: 정점 수)
기법 (Approach): 두 알고리즘 모두 그리디 알고리즘을 사용한다. 현재 상황에서 가장 좋은 선택(최소 가중치)을 하며 진행한다.
✅ 요약
프림 알고리즘: 정점 중심으로 트리를 확장, DFS와 유사하며, 별도의 사이클 확인이 필요 없음.
크루스칼 알고리즘: 간선 중심으로 트리를 합침, 유니온-파인드를 사용해 사이클 생성 여부 확인.
최소 신장 트리 - 프림 알고리즘 #1 : 의사코드 (Overview of Prim Algorithm Pseudocode)
💡요약: 프림 알고리즘은 그리디 알고리즘(Greedy Algorithm)을 기반으로 최소 신장 트리를 찾는 방법이다. 이 알고리즘은 방문한 정점을 관리하는 집합 S를 이용해 진행하며, 최소 비용 간선을 선택해 트리를 확장한다. 효율적인 수행을 위해 힙(Heap) 자료구조를 사용한다.

S ← ∅S는 방문한 정점의 집합 (Set of Visited Vertices)이다. 처음에는 비어 있는 상태로 시작한다. 목적으로는 방문한 정점을 기록하기 위해 사용한다.정점 r을 방문되었다고 표시하고, 집합 S에 포함시킨다.설명: 알고리즘은 특정 시작 정점 r에서 시작하며, 이 정점을 방문했다고 표시하고 S에 추가한다.
목적: 첫 시작 정점을 기준으로 알고리즘을 진행한다.
while (S ≠ V)설명: S가 모든 정점을 포함할 때까지 반복한다. V는 전체 정점 집합이다.
목적: 모든 정점이 연결될 때까지 최소 신장 트리를 확장.
S에서 V - S를 연결하는 간선들 중 최소길이의 간선 (x, y)를 찾는다설명: 방문한 정점 집합 S와 방문하지 않은 정점 집합 V−S 연결하는 간선들 중에서 가중치가 가장 작은 간선을 선택한다.
목적: 그리디 알고리즘의 핵심. 현재 가능한 최선의 선택(가장 짧은 간선)을 통해 비용을 최소화.
정점 y를 방문되었다고 표시하고, 집합 S에 포함시킨다.설명: 간선 (x,y)에서 연결된 정점 y를 방문했다고 표시하고 S에 추가한다.
목적: 방문한 정점 집합을 업데이트해 알고리즘이 계속 진행될 수 있도록 한다.
✅ 수행 시간
- 복잡도 (Complexity):O(E \log V)이다. 간선 선택 시 효율성을 위해 힙(Heap) 자료구조를 사용하기 때문이다.
✅ 요약
작동 원리: 정점 중심으로 최소 가중치 간선을 선택하며 트리를 확장한다. S에 방문한 정점을 추가하며 진행한다.
특징: 효율성을 위해 힙 자료구조를 사용한다. 그리디 알고리즘을 기반으로 진행한다.
종료 조건: 모든 정점이 S에 포함될 때.
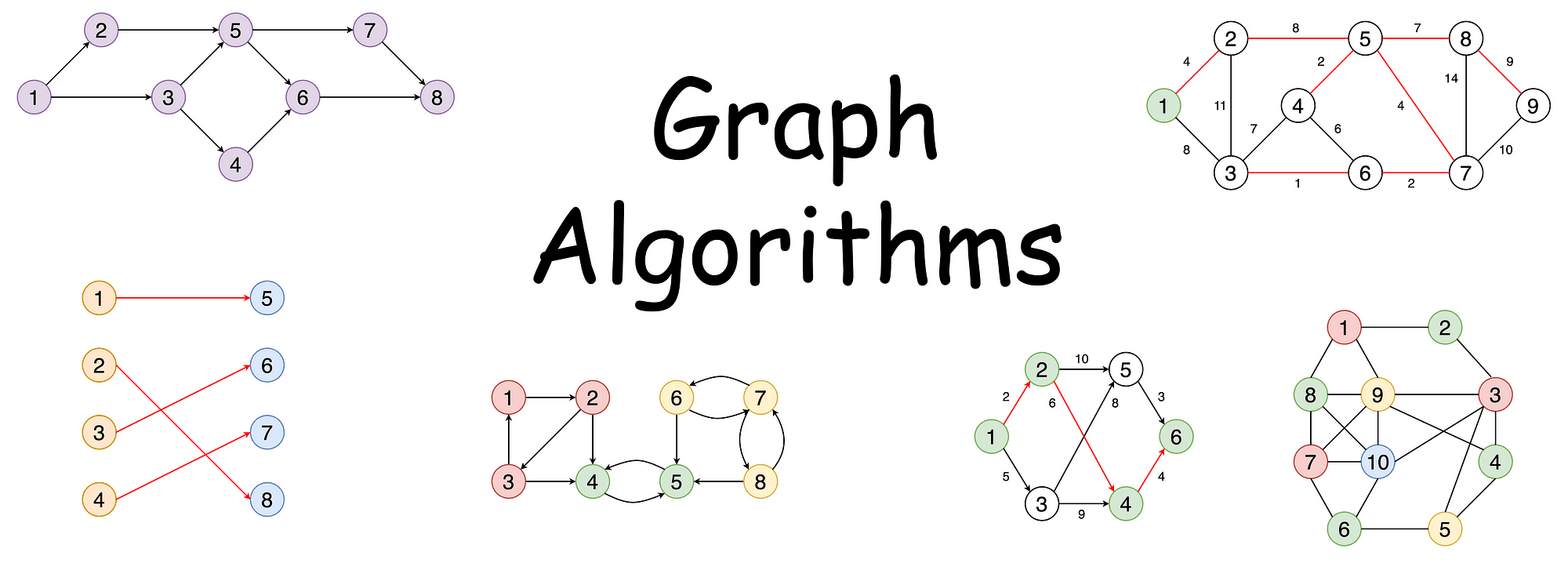
최소 신장 트리 - 프림 알고리즘 #2 : 작동 예제 (Prim Algorithm Example)
💡 요약: 프림 알고리즘은 정점 중심(Greedy)으로 최소 신장 트리를 형성한다. 각 단계에서 가장 적은 비용(최소 가중치)을 가진 간선을 선택하며 트리를 확장한다. 비용 완화(Relaxation) 과정을 통해 더 적은 비용으로 정점을 연결할 수 있는 경우 비용을 업데이트한다.
프림 알고리즘은 효율적으로 최소 신장 트리를 구할 수 있는 대표적인 그리디 알고리즘이다.

✅ (a) 초기 상태, 초기화: 시작 정점(S)의 비용을 0으로 설정하고 나머지 정점은 무한대(∞)로 초기화한다.
시작 정점: S
연결된 노드의 비용: 8,9,11
✅ (b) 첫 번째 단계, 업데이트: 정점 S와 연결된 노드의 비용을 가중치 값으로 업데이트한다.
비용 업데이트: 8,9,11
최소 비용 선택: 8 (정점 0으로 이동).
✅ (c) 두 번째 단계, 최소 비용 노드 선택: S에서 비용이 가장 작은 간선 8을 선택하여 연결된 정점(0)으로 이동한다.
0에서 새롭게 연결된 노드(10)의 비용을 업데이트.
비용 완화: 무한대(∞) → 10
✅ (d) 세 번째 단계, 최소 비용 노드 선택: 비용이 가장 작은 노드(9)로 이동.
9의 연결 노드(5, 12) 비용 업데이트. 기존 연결 노드 10은 가장 적은 비용(최소 가중치)을 가진 간선을 선택한 결과로 5로 업데이트 되었다.
- 비용 완화: 10→5, 무한대(∞) → 12

✅ (e) 네 번째 단계, 최소 비용 노드 선택: 비용이 가장 작은 노드(5)로 이동.
인접 노드(9, 8) 비용 업데이트.
- 하지만, 비용 변화 없음.
✅ (f) 다섯 번째 단계
최소 비용 노드 선택: 더 이상 갈 곳 이 없으므로 비용이 가장 작은 노드(11)로 이동.
연결 노드(8)의 비용 업데이트.
비용 완화: 무한대(∞) → 8.
✅ (g) 여섯 번째 단계, 최소 비용 노드 선택: 비용이 가장 작은 노드(8)로 이동.
연결 노드(7)의 비용 업데이트.
- 비용 완화: 12→7
✅ (h) 종료, 최소 신장 트리 완성: 모든 노드가 방문되었으므로 알고리즘 종료.
결과 트리는 (i)에 표시된 최소 신장 트리이다.
최소 신장 트리 - 프림 알고리즘 #3: 의사 코드(Prim Algorithm Pseudocode)
💡요약: 프림 알고리즘은 정점 중심의 최소 신장 트리 알고리즘이다. 시작 정점에서부터 가장 적은 비용(최소 가중치)의 간선을 선택하며 점점 트리를 확장해 나간다. 수행 과정에서 완화(relaxation) 과정을 통해 최적의 경로를 계산한다.

Prim(G, r)G = (V, E): 정점 집합 V와 간선 집합 E로 이루어져 있는 주어진 그래프이다.r: 시작 정점을 나타낸다.
S ← ∅: 방문한 정점을 저장할 집합 S를 초기화한다. 시작은 비어 있다.
for each u ∈ V: 모든 정점 u에 대해 아래 작업을 수행한다.
u.cost ← ∞각 정점의 비용(cost)을 무한대(∞)로 초기화한다. 초기에는 어떤 정점과도 연결되지 않았음을 나타낸다
r.cost ← 0시작 정점 r의 비용을 0으로 설정한다.
while (S ≠ V)아직 모든 정점을 방문하지 않았다면 반복한다.
u ← extractMin(V − S, d)방문하지 않은 정점들 중 가장 비용이 작은 정점 u를 선택한다.extractMin: 비용이 가장 작은 정점을 반환하는 함수이다.
S ← S ∪ {u}선택된 정점 u를 방문 집합 S에 추가한다.
for each v ∈ u.adjlist정점 u와 연결된 모든 인접 정점 v에 대해 아래 작업을 수행한다.
if (v ∈ V − S and w_{uv} < v.cost)v가 방문되지 않았고, 현재 간선 w_uv의 비용이 v.cost보다 작다면 비용을 업데이트한다.
v.cost ← w_{uv}v.cost 값을 vw_uv로 업데이트한다. 이 과정은 "완화(relaxation)"이라고 불린다.
v.tree ← uv의 이전 정점을 u로 설정하여 경로를 기록한다.
수행 시간: O(|E| log |V|)프림 알고리즘의 수행 시간은 O(|E| \log |V|)이다. 효율적인 구현을 위해 힙 자료구조를 사용한다.
✅ 요약
초기화: 모든 정점의 비용을 무한대로 설정. 시작 정점의 비용은 0.
반복: 비용이 가장 작은 정점을 선택하고 방문.
완화: 인접 정점의 비용을 업데이트하며 최적의 경로를 계산.
종료: 모든 정점을 방문하여 최소 신장 트리를 완성.
최소 신장 트리 - 크루스칼 알고리즘 (Kruskal Algorithm)
💡요약: 크루스칼 알고리즘은 단순하고 이해하기 쉬운 구조이지만, 사이클 검사를 포함해 조금 더 복잡한 과정이 필요하다.
크루스칼 알고리즘은 간선을 중심으로 최소 신장 트리를 찾는 알고리즘이다. 간선의 가중치를 기준으로 정렬 후, 하나씩 추가하면서 사이클(cycle) 여부를 확인한다. 이 과정에서 유니온 파인드(Union-Find) 알고리즘이 사용되어 효율적으로 사이클을 판별하게 된다.
✅ “간선을 가중치 기준으로 정렬” : 간선의 가중치를 기준으로 오름차순 정렬한다. 가장 적은 가중치의 간선부터 최소 신장 트리에 추가한다.
- 에지 리스트 (Edge List): 간선 중심의 그래프 표현 방식이다.
✅"유니온 파인드 알고리즘 포함": 간선을 추가할 때, 두 정점이 이미 같은 집합에 속해 있는지 확인한다.
사이클 판별: 유니온 파인드 알고리즘을 사용해 효율적으로 확인한다.
유니온(Union): 두 집합을 합친다.
파인드(Find): 정점이 속한 집합을 찾는다.
최소 신장 트리 - 크루스칼 알고리즘 #1: 의사코드(Kruskal Algorithm Pseudocode)
💡요약: 각 단계는 간선의 가중치 순 정렬, 간선 선택, 그리고 집합 병합을 통해 이루어진다.

- 초기화 (Initialize Disjoint Sets): 처음에는 각각의 정점이 독립적인 집합으로 초기화된다. 모든 정점은 자신만 포함된 개별 집합에 속한다.
- 간선 정렬 (Sort Edges by Weight): 모든 간선을 가중치 오름차순으로 정렬한다. 가장 적은 가중치의 간선부터 하나씩 처리한다.
While 루프 (Build the Spanning Tree): 간선의 개수가
정점의 수 - 1이 될 때까지 반복한다.- 최소 신장 트리의 정의: 트리에는 항상 간선의 개수가
정점 - 1이어야 한다.
- 최소 신장 트리의 정의: 트리에는 항상 간선의 개수가
- 최소 비용 간선 선택 (Select Minimum Edge): 정렬된 간선 리스트에서 가장 적은 비용의 간선을 선택한다.
사이클 검사 (Cycle Detection) 두 정점이 서로 다른 집합에 속해 있는지 확인한다.
- 다른 집합에 속해 있다면, 해당 간선을 선택해도 사이클이 발생하지 않게된다.
- 간선 추가 및 집합 병합 (Add Edge and Union Sets): 간선을 트리에 추가하고, 두 정점이 같은 집합에 속하도록 병합한다. 이 과정에서 유니온 파인드 알고리즘이 사용된다.
- 종료 조건 (Finish when Tree is Complete):" 트리에 필요한 간선 개수(
n - 1)가 충족되면 알고리즘이 종료된다.
✅ 복잡도
- 수행 시간: 가장 시간이 많이 소요되는 부분인 O(E log V) 간선 정렬이 가장 큰 비용이므로, 이 부분이 전체 시간 복잡도를 결정한다.
✅ 요약 크루스칼 알고리즘은 다음과 같은 순서로 동작한다.
간선을 가중치 오름차순으로 정렬한다.
사이클 여부를 확인하며 간선을 선택하고 트리에 추가한다.
간선이
n - 1개가 되면 트리를 완성하고 종료한다.
크루스칼 알고리즘은 간단하면서도 효율적인 최소 신장 트리 찾기 방법으로, 유니온 파인드 알고리즘과 함께 자주 사용된다.
최소 신장 트리 - 크루스칼 알고리즘 #2: 예시(Kruskal Algorithm Example)
💡요약: 크루스칼 알고리즘은 가중치가 낮은 간선을 순차적으로 선택하며, 사이클을 생성하지 않는 방식으로 최소 신장 트리를 만든다. 모든 노드가 연결되며 최소 신장 트리 완성되게 된다.
✅ 전체 그래프가 주어진 상태 (Initial Graph) 그래프의 모든 간선과 정점이 주어졌다. 각 간선은 가중치를 가진다. 크루스칼 알고리즘은 가중치가 가장 낮은 간선부터 순서대로 선택한다.

(a): 가장 낮은 가중치 5를 가진 간선이 선택된다. 두 정점은 별개의 집합으로 간주되므로 연결 가능.
(b): 두 번째로 낮은 가중치 7의 간선이 선택된다. 선택 후, 새로운 집합이 형성된다.
- 현재 집합: 두 개의 독립 집합.
(c): 두 독립된 집합이 하나의 집합으로 합쳐진다 (Union).
- 총 5개의 집합 중 두 개가 병합되었다.
(d): 가중치 8인 간선이 선택된다.
- 유니온 연산 후, 연결된 두 정점은 또 하나의 집합으로 합쳐진다.
(e): 집합의 총 개수가 4개로 감소.

(f): 가중치 9 간선이 선택된다.
- 현재 연결 가능한 정점들을 병합하며 4개의 연결된 노드가 생성.
(g) 선택 가능한 간선들을 추가하며 집합 간 병합을 진행.
- 사이클이 발생하지 않도록 주의하며 진행.
(i) 최종 결과 (Final Result)
최소 신장 트리 (Minimum Spanning Tree) 완성.
연결된 모든 간선의 가중치 합이 최소화된다.
최소 신장 트리 - 크루스칼 알고리즘 #3: 자료구조(Kruskal Algorithm Data Structure)

엣지 리스트는 각 간선(edge)을 표현하는 방식으로, 각각의 엣지가 시작 노드(Node 1), 도착 노드(Node 2), 가중치(Weight)로 구성된다.
- 예: 엣지
(1, 2, 8)는 노드 1과 노드 2를 연결하며, 가중치가 8임을 의미한다.
- 예: 엣지
유니온 파인드(Union-Find) 리스트는 노드들이 각각 어떤 집합에 속하는지 관리하는 자료구조이다.
처음에는 모든 노드가 독립된 집합이다. (자기 자신만 포함)
초기 상태에서 각 노드의 대표(parent)는 자기 자신이 된다.
예: 노드 1의 대표 = 1, 노드 2의 대표 = 2.

가중치란 두 노드를 연결하는 데 드는 비용이다.
크루스칼 알고리즘에서는 가중치가 작은 간선부터 순서대로 선택한다.
엣지 리스트를 오름차순(가중치가 작은 순서)으로 정렬한다.
예:
정렬 전:
(1, 2, 8),(2, 5, 5),(1, 3, 3),(3, 4, 13),(2, 4, 4),(4, 5, 2)정렬 후:
(4, 5, 2),(1, 3, 3),(2, 4, 4),(2, 5, 5),(1, 2, 8),(3, 4, 13)

정렬된 엣지 리스트에서 가장 작은 가중치를 가진 간선을 하나씩 선택한다.
사이클이 생기는지 확인하기 위해 두 노드의 대표(parent)가 같은지 확인한다:
다른 집합이라면 연결해도 사이클이 발생하지 않으므로 간선을 추가한다.
같은 집합이라면 두 노드가 이미 연결되어 있어 사이클이 발생하므로 간선을 추가하지 않는다.
예시 설명:
첫 번째 엣지
(4, 5, 2):노드 4와 노드 5의 대표를 확인한다. (각각 4와 5)
두 노드가 서로 다른 집합이므로 연결한다.
유니온(Union) 연산을 수행하여 두 집합을 하나로 합친다. (대표 4로 업데이트)
두 번째 엣지
(1, 3, 3):노드 1과 노드 3의 대표를 확인한다. (현재 대표는 1과 3)
두 노드가 다른 집합이므로 연결한다.
유니온 연산을 통해 두 집합을 합친다. (대표 1로 업데이트)
세 번째 엣지
(2, 4, 4):노드 2와 노드 4의 대표를 확인합니다. (현재 대표는 2와 4)
유니온 연산을 통해 두 집합을 합친다. (대표 2로 업데이트)
네 번째 엣지
(2, 5, 5)노드 2와 노드 5의 대표를 확인합니다. (현재 대표는 2와 4)
유니온 연산을 통해 두 집합을 합친다. (대표 2로 업데이트)
다섯 번째 엣지
(1, 2, 8)노드 1와 노드 2의 대표를 확인한다. (현재 대표는 1와 2)
유니온 연산을 통해 두 집합을 합친다. (대표 1로 업데이트)
여섯 번째 엣지
(3, 4, 13)노드 3와 노드 4의 대표를 확인한다. (현재 대표는 1과 1)
유니온 연두 노드가 같은 집합이므로 연결하지 않는다. (사이클 방지)

위 과정을 모든 엣지에 대해 반복한다.
모든 노드가 하나의 집합으로 합쳐지면 최소 신장 트리가 완성된다.
이 과정에서 사용된 엣지는 최소 비용으로 모든 노드를 연결하게 된다.
✅ 총 비용 계산

최소 신장 트리를 이루는 엣지들의 가중치를 모두 더한다.
- 예: 선택된 엣지가
(2, 5, 5),(1, 2, 8)이라면 총 비용은5+8 = 13이 된다.

Q: 크루스칼 알고리즘에서 그래프의 모든 간선과 정점이 주어졌다. 각 간선은 가중치를 가진다. 크루스칼 알고리즘은 가중치가 가장 낮은 간선부터 순서대로 선택한다. 라고 했는데 시작점이 r로 주어진 상태라면 시작점 r 부터 시작하나요 아니면 그래도 가장 낮은 간선부터 시작하나요?
A: 크루스칼 알고리즘에서는 시작점이 따로 중요하지 않다. 가중치가 가장 낮은 간선부터 시작하여 신장 트리를 만들어가는 방식이기 때문이다. 따라서, 시작점이 r로 주어졌더라도 알고리즘의 동작 방식에는 아무런 영향을 미치지 않게 된다.
✅ 예시
정점:
r, 1, 2, 3간선:
[(r, 1, 2), (1, 2, 1), (r, 2, 3), (1, 3, 4)]
간선을 가중치 순으로 정렬:
[(1, 2, 1), (r, 1, 2), (r, 2, 3), (1, 3, 4)]가중치 1인 간선 (1, 2) 선택
다음으로 가중치 2인 간선 (r, 1) 선택
가중치 3인 간선 (r, 2) 선택 (사이클이 발생하면 제외)
가중치 4인 간선 (1, 3) 선택
최종 신장 트리: (1, 2), (r, 1), (1, 3).




