Database Design and Construction : Index Essential (1/2)
인덱스의 개요, 구조와 작동원리, 생성과 관리
Contents
1️⃣ 인덱스 개요 (Overview of Index)
2️⃣ 인덱스 구조와 작동원리 (Mechanism and Structure of Index)
3️⃣ 인덱스 생성과 관리 (Create and Manage of Index)
1️⃣ 인덱스 개요 (Overview of Index)
💡Keyword: 인덱스, 검색 성능, WHERE 절, JOIN 조건, 범위 검색, NULL 값, 대형 테이블, 단일/복합/유일/비유일 인덱스, 역방향/비트맵 인덱스, 인덱스 유지 관리, 배치 처리, 캐시, 테이블 파티셔닝, NoSQL
💡인덱스 요약: 데이터에 대한 논리적 포인터의 집합으로 책의 찾아보기와 같은 역할을 한다(사실 책의 찾아보기 보단 더 어렵다). 테이블 로우의 특정값(ROWID)과 특정 컬럼의 정렬된 값을 결합하여 구조화한다. 질의문의 빠른 수행과 컬럼값의 유일성을 보장하기 위해서 사용한다.
인덱스란? 인덱스의 정의⬇️
정의: 인덱스는 데이터에 대한 논리적 포인터(Index as a Logical Pointer)의 집합으로, 책의 찾아보기 (a book's index) 와 같이 데이터를 효율적으로 찾아 전체 테이블을 스캔하지 않고도 원하는 데이터를 빠르게 찾을 수 있도록 도와준다.
ROWID와 컬럼 값의 결합 (Combination of ROWID and Column Value): 인덱스는 행 식별자와 정렬된 컬럼 값을 결합하여 데이터를 효율적으로 구조화한다.
질의 성능 (Query Performance): 인덱스는 질의문을 빠르게 실행하고, 컬럼 값의 유일성을 보장하기 위해 사용된다.
✅추가 설명: ROWID 테이블 안에서 각 행(데이터 줄)을 구분하는 고유한 번호라고 생각하시면 된다. 마치 사람들이 각자 고유한 주민등록번호가 있는 것처럼, 테이블 안의 각 데이터도 고유한 번호가 있다. 특정 컬럼의 정렬된 값의 뜻은 테이블 안의 특정 컬럼(예를 들어, 이름이나 나이 같은 데이터)의 값들을 순서대로 정렬한 것을 의미한다. 이 두 가지를 결합한다는 것은 무슨 뜻일까? 행을 구분하는 ROWID와 특정 컬럼에서 정렬된 값을 함께 묶어서 테이블 데이터를 정리하는 방식이라는 뜻이다. 쉽게 말하면, ROWID는 데이터의 고유한 주소이고, 특정 컬럼의 정렬된 값은 그 데이터를 빨리 찾기 위해 순서대로 정리하는 방법이다. 이러한 인덱스의 구조 덕분에, 데이터베이스가 더 빠르게 데이터를 찾을 수 있는 것이다.
✅참고: 버퍼 캐시와 인덱스는 데이터베이스 성능을 최적화하는 데 중요한 역할을 한다. 버퍼 캐시는 자주 접근하는 데이터를 메모리에 저장하여 디스크 I/O를 줄일 수 있다. 인덱스는 데이터를 빠르게 찾도록 도와 데이터베이스가 디스크에서 읽어야 할 데이터를 최소화하는 역할을 한다. 자주 사용하는 인덱스 데이터는 버퍼 캐시에 저장될 가능성이 높아져, 디스크 접근을 줄이고 질의 성능을 향상시킬 수 있다. 이처럼 버퍼 캐시와 인덱스는 함께 작동하여 빠른 질의 성능과 효율적인 메모리 사용을 보장한다.
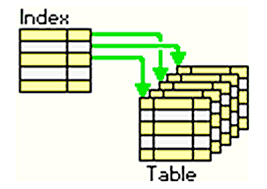
인덱스란? 인덱스의 예 ⬇️

위의 이미지는 인덱스 (Index) 가 어떻게 데이터베이스 테이블과 연결되는지를 시각적으로 설명하고 있다. 이 이미지를 통해 알 수 있는 인덱스의 특징은 무엇일까? 인덱스는 데이터베이스에서 검색 성능을 높이기 위해 특정 컬럼을 기준으로 정렬된 값과 ID (ID) 를 함께 사용하여 데이터를 빠르게 찾는 역할을 한다는 것을 보여주고 있다.
인덱스 (Index): 이 부분에서는 이름을 기준으로 정렬된 목록이 있다.각 이름 옆에 있는 ID (ID) 는 데이터가 실제로 저장된 테이블에서 해당 이름이 위치한 행을 가리키고 있다.
- 예를 들어, Andrew (Andrew) 의 ID (ID) 는 3이며, 이는 실제 테이블 (Table) 에서 Andrew (Andrew) 가 ID 3 (ID 3) 에 위치한 데이터를 의미한다. 인덱스에 있는 ID (ID) 는 실제 테이블에서 해당 데이터가 위치한 곳을 가리키고 있다. 이를 통해 특정 데이터를 더 빨리 찾을 수 있다.
테이블 (Table): 테이블은 실제 데이터가 저장된 곳이다. 각 행은 고유한 ID (ID) 를 가지고 있으며, 이름 (Name) 과 도시 (City) 와 같은 다른 정보들도 포함하고 있다.
- 예를 들어, ID 1 (ID 1) 에 위치한 Matt (Matt) 의 도시는 San Francisco (San Francisco) 이다.
인덱스란? 인덱스의 필요성 (Importance of Index)⬇️
테이블의 로우는 데이터 파일의 블록의 빈 공간에 저장됨 (Table rows are stored in empty spaces in the blocks of data files): 테이블 안의 데이터(행)는 파일의 빈 공간에 무작위로 저장된다. 그래서 인덱스가 없다면 데이터를 빠르게 찾기가 어려울 수 있다.
데이터베이스는 각 테이블의 모든 페이지에 있는 데이터를 읽어서 원하는 로우를 찾아야 함 (Database needs to read data from all pages in the table to find the desired row): 데이터베이스는 필요한 데이터를 찾기 위해 모든 데이터를 하나하나 읽어야 할 때가 있다. 인덱스가 없이 데이터를 찾으려면 데이터베이스가 테이블의 모든 데이터를 읽어야 할 수 있어, 대규모 테이블에서는 비효율적이다.
작은 크기의 테이블은 없어도 무관 (Small tables can work without an index): 테이블이 작은 경우, 인덱스 없이도 충분히 데이터를 빠르게 찾을 수 있기 때문에 인덱스가 꼭 필요하지 않을 수 있다.
대부분의 경우 데이터 접근 속도가 빨라짐 (In most cases, data access becomes faster): 인덱스를 사용하면 대부분의 경우 데이터 접근 속도가 매우 빨라진다. 이는 데이터베이스 성능 향상에 중요한 역할을 하게 된다.
인덱스란? 인덱스 장단점 (Advantages and Disadvantages of Indexes)⬇️
장점(Advantages)
빠르게 데이터를 찾아낼 수 있음 (Can quickly locate data): 인덱스는 데이터를 더 빨리 검색할 수 있도록 도와주기 때문에 검색 속도가 크게 향상되어 대규모 테이블에서도 효율적이다.
유일 인덱스로 만들면 UNIQUE 제약 조건도 강화할 수 있음 (If created as a unique index, it can also enforce UNIQUE constraints): 인덱스는 테이블의 특정 컬럼 값들이 중복되지 않도록 보장할 수 있다. 이를 통해 UNIQUE 제약 조건 (UNIQUE constraints) 을 강화할 수 있게 된다.
단점(Disadvantages)
인덱스 자체가 추가적인 공간을 차지하고, 인덱스를 유지 관리하는데 추가적인 시간이 소비됨 (Indexes themselves take up additional space and require extra time for maintenance): 인덱스는 추가적인 저장 공간을 차지하며, 이를 유지 관리하는 데도 시간이 든다.
인덱스를 이용해서 데이터를 검색할 때는 시간이 줄어들지만, 데이터를 추가하고 수정할 때는 인덱스 때문에 시간이 더 걸림 (Although searching data with indexes is faster, adding or updating data can take longer due to the index): 인덱스가 있는 경우, 데이터를 검색하는 속도는 빨라지지만, 데이터를 추가하거나 수정할 때는 인덱스를 업데이트해야 하기 때문에 오히려 시간이 더 소요된다.
✅참고: 인덱스를 유지 관리하는 데 시간이 소요된다는 것은 주로 데이터의 변경 작업과 관련이 있다. 데이터가 변경될 때마다 인덱스가 자동으로 업데이트되어야 하기 때문이다. 삽입, 수정, 삭제 작업 시 인덱스를 다시 정렬하거나 갱신하는 과정이 필요한데, 이 과정은 추가적인 성능 부담을 유발할 수 있다. 또한, 인덱스가 오래되면 재구성 작업도 필요할 수 있다.
인덱스를 사용하면 데이터 검색 속도가 크게 빨라지고, 데이터 무결성을 보장하며, 대규모 데이터를 효과적으로 관리할 수 있는 이점 때문에 인덱스는 대부분의 데이터베이스 시스템에서 필수적으로 사용되고 있다.
인덱스 생성 기준 - 인덱스를 생성해야 하는 이유 (When to Create an Index)⬇️
SQL문에서 컬럼이 WHERE 절 또는 JOIN 조건에서 자주 사용될 때 (When a column is frequently used in WHERE clauses or JOIN conditions in SQL statements)
- 쿼리에서 자주 조건으로 사용되는 컬럼은 인덱스를 통해 검색 속도를 높일 수 있다. 특히 WHERE 절 (WHERE clause) 나 JOIN 조건 (JOIN condition) 에 자주 등장하는 컬럼은 인덱스를 생성하면 성능이 크게 향상된다.
컬럼에 광범위한 값이 포함될 때 (When a column contains a wide range of values) (범위 검색)
범위 검색 (Range queries) 이 자주 필요한 컬럼 즉, 값의 분포가 넓은 컬럼에 대해 특정 범위 내의 데이터를 찾는 경우를 의미한다.
날짜 범위 검색 (Date range queries): 어떤 특정 기간에 발생한 데이터를 검색해야 하는 경우, 예를 들어 "2023년 1월 1일부터 2023년 3월 31일까지의 거래"를 조회한다면, 날짜 컬럼에 인덱스를 적용하면 더 빠르게 해당 기간에 속하는 데이터를 찾을 수 있게 된다.
가격 범위 검색 (Price range queries): 특정 가격 범위에 해당하는 제품을 검색할 때도 가격 컬럼에 인덱스가 있으면 빠르게 검색할 수 있다. 예를 들어, "100달러에서 200달러 사이의 상품"을 찾는 경우이다.
컬럼에 많은 수의 NULL 값을 포함할 때 (When a column contains many NULL values)
NULL 값이 많은 컬럼에 인덱스를 적용하면, NULL이 아닌 값이나 NULL 값을 빠르게 검색할 수 있게 된다. NULL 도 “특정 조건” 이기 때문이다.
NULL데이터베이스에서 "아무 값도 없는 상태"를 의미한다. 예를 들어, 어떤 사람이 전화번호를 입력하지 않으면 그 필드에 NULL 값이 들어간다. 이처럼 데이터가 없는 칸에 NULL이 들어가게 된다.NULL이 아닌 값을 찾고 싶을 때: 예를 들어, "전화번호가 입력된 사람만 검색하고 싶다"라는 쿼리가 있을 수 있다고 하자. 이때 인덱스가 있으면 NULL 값이 아닌 데이터를 더 빨리 찾을 수 있다. "전화번호가 있는 사람만 찾기" (
WHERE phone_number IS NOT NULL)예를 들어, NULL 값이 많은 테이블에서 NULL 값이 아닌 데이터를 찾으려면, 인덱스가 없을 때는 테이블의 모든 데이터를 일일이 확인해야 하지만, 인덱스가 있으면 그 과정을 생략하고 바로 필요한 부분만 찾아서 성능을 향상시킬 수 있다는 뜻이다.
대형 테이블이고 대부분의 질의가 10%~15% 이하로 로우를 읽어 들일 것으로 예상할 때 (When the table is large and most queries are expected to read 10% to 15% or less of the rows)
대형 테이블 (Large tables) 에서 질의가 전체 데이터의 일부만 읽는 경우(약 10~15% 이하), 인덱스를 사용하면 데이터를 빠르게 찾아 성능을 크게 향상시킬 수 있다.
좀 더 덧붙여서 설명하자면 만약 인덱스가 없다면, 데이터베이스는 테이블의 모든 행을 처음부터 끝까지 확인하면서, 내가 원하는 데이터가 어디에 있는지 찾아야 한다. 이건 아주 비효율적일 수 밖에 없다. 특히 데이터가 수천만 건일 때는 시간이 오래 걸릴 것이다. 하지만 인덱스가 있으면, 데이터베이스는 테이블 전체를 읽지 않고도 필요한 부분만 바로 찾아서 가져올 수 있게된다.
인덱스 생성 기준 - 인덱스를 생성하지 않아야 하는 이유 (When Not to Create an Index) ⬇️
테이블에 자료의 양이 적을 때 (When the table contains a small amount of data)
- 데이터가 적을 때는 인덱스를 사용하는 것보다 그냥 테이블 전체를 읽는 것이 더 빠를 수 있다. 데이터 양이 적으면 인덱스를 통해 얻을 수 있는 성능 향상이 크지 않기 때문에 인덱스가 불필요할 수 있다.
컬럼이 WHERE 조건으로 자주 사용되지 않을 때 (When the column is not frequently used in WHERE clauses)
- 인덱스는 주로 WHERE 절 (WHERE clauses) 에서 데이터를 빠르게 검색하기 위해 사용된다. 만약 컬럼이 조건으로 자주 사용되지 않는다면, 인덱스를 만들 필요가 없다. 자주 사용되지 않는 인덱스는 그저 추가적인 공간만 차지하게 되기 때문이다.
질의 대부분이 10% ~ 15% 이상 데이터를 읽어올 것으로 예상될 때 (When most queries are expected to read more than 10% to 15% of the data)
- 테이블의 대부분 데이터를 한 번에 읽어야 하는 경우에는 인덱스를 사용하는 것이 의미가 없다. 이럴 때는 인덱스를 건너뛰고 전체 데이터를 한 번에 읽는 것이 더 효율적이다.
테이블에 빈번하게 삽입, 수정, 삭제가 일어날 때 (When the table is frequently inserted, updated, or deleted): 삽입 (Insert), 수정 (Update), 삭제 (Delete)
- 작업이 자주 일어나는 테이블에 인덱스가 있으면, 그때마다 인덱스를 업데이트해야 하기 때문에 성능이 떨어질 수 있다. 데이터를 많이 변경하는 테이블은 인덱스를 유지 관리하는 비용이 크기 때문에, 인덱스를 적용하지 않는 것이 더 효율적이다.
✅참고: 결론적으로, 모든 상황에서 인덱스가 필요한 것은 아니며, 데이터의 크기, 쿼리 사용 패턴, 데이터 수정 빈도 등을 고려하여 인덱스를 적용하는 것이 중요하다. 테이블에 빈번하게 삽입, 수정, 삭제가 일어날 때는 인덱스 없이 어떤 방법을 쓰는게 좋을까? 그럴때는 완전히 인덱스를 없애는 것이 아니라, 꼭 필요한 기본 키 (Primary Key) 나 유니크 제약 조건 (Unique constraints) 을 위한 인덱스만 유지하는 것이 좋다.
인덱스 종류 - 논리적 분류 (Logical Classification of Indexes) ⬇️
💡요약: 단일 컬럼 인덱스는 하나의 컬럼에만 적용되며, 간단한 검색에 사용된다. 복합 인덱스는 여러 컬럼을 조합해 쿼리 성능을 높일 수 있다. 유일 인덱스는 데이터의 유일성을 보장하고, 비유일 인덱스는 중복 데이터를 허용한다. 함수 기반 인덱스는 특정 컬럼의 값을 계산하여 저장하고 검색을 최적화한다.
단일 컬럼 인덱스 (Single Column Index):
- 하나의 컬럼으로 인덱스를 구성 (An index is created using a single column): 말 그대로, 한 가지 컬럼만을 기반으로 인덱스를 만드는 방식이다. 쿼리에서 하나의 조건에 따라 검색할 때 유리하다.
복합 인덱스 (Composite Index):
- 두 개 이상의 컬럼으로 인덱스를 구성 (An index is created using two or more columns) (최대 32개까지 가능): 여러 개의 컬럼을 조합하여 인덱스를 만들 수 있다. 예를 들어, 이름과 나이를 함께 조회할 때 성능을 높일 수 있다. 이 방식은 여러 조건을 동시에 사용하는 쿼리에서 유리하다.
유일 인덱스 (Unique Index):
- 중복된 값이 존재하지 않는 인덱스 (An index that does not allow duplicate values): 해당 컬럼에 있는 값이 중복되지 않도록 보장하는 인덱스이다. 이 인덱스를 통해 데이터 무결성을 유지할 수 있으며, PRIMARY KEY 와 유사한 역할을 한다.
비유일 인덱스 (Non-Unique Index):
- 중복된 값이 허용되는 인덱스 (An index that allows duplicate values): 중복 값을 허용하는 인덱스이다. 동일한 값을 가진 여러 행이 존재해도 상관없는 경우 사용된다.
함수 기반 인덱스 (Function-Based Index):
- 함수나 표현식으로 컬럼 값을 계산하여 인덱스에 저장 (An index that stores values calculated from a function or expression on a column): 특정 컬럼 값을 함수나 계산식으로 변환한 결과를 인덱스에 저장하는 방식이다. 예를 들어, 문자열을 소문자로 변환한 값을 인덱싱하여 대소문자 구분 없이 검색할 수 있도록 할 수 있다.
인덱스 종류 - 물리적 분류 (Physical Classification of Indexes)⬇️
💡요약: 역방향 인덱스는 연속된 데이터의 균형을 유지하기 위해 값을 뒤집어서 저장하는 방식이다. 비트맵 인덱스는 값이 반복되거나 데이터가 적을 때 바이너리 형태로 데이터를 저장해 성능을 향상시킨다. 비트맵-조인 인덱스는 여러 테이블의 데이터를 조인한 후 빠르게 검색할 수 있도록 도와준다. 유일 인덱스는 중복 없이 데이터의 유일성을 보장한다.
역방향 인덱스 (Reverse Key Index):
B-Tree 인덱스에서 컬럼의 값을 뒤집어서 배열 (In a B-Tree index, the values of the column are stored in reverse order): 값의 순서를 뒤집어서 저장하는 방식이다.
연속된 데이터의 경우 이전의 데이터를 지우면 한쪽으로 치우치는 현상이 발생하고 균형이 깨지는 것을 방지 (Prevents imbalances caused by deleting sequential data): 예를 들어, 연속된 숫자가 있는 경우, 데이터가 한쪽으로 치우치지 않도록 값의 순서를 뒤집어서 인덱스를 저장한다. 이를 통해 균형 유지가 가능하다.
비트맵 인덱스 (Bitmap Index):
인덱스에 저장된 컬럼의 값을 바이너리로 저장 (Column values are stored as binary in the index): 데이터의 각 값을 바이너리(0과 1) 형태로 변환하여 저장한다. 비트맵 인덱스는 값의 종류가 적고, 반복되는 데이터가 많을 때 성능이 향상된다.
예를 들어, "남성", "여성"과 같은 성별 데이터를 비트로 저장하는 것이 더 효율적일 수 있다.
비트맵-조인 인덱스 (Bitmap Join Index):
기본 구조는 비트맵 인덱스와 동일 (The structure is the same as a bitmap index): 비트맵 인덱스와 유사하게 바이너리 형태로 저장된다.
두 개 이상의 테이블 조인 결과에 대해서 정의되어 생성된 인덱스 (Created based on the result of a join between two or more tables): 여러 테이블을 조인할 때 성능을 높이기 위해 사용된다. 특히, 서로 다른 테이블의 데이터를 합친 후에도 빠르게 검색할 수 있다.
유일 인덱스 (Unique Index):
- 중복된 값이 존재하지 않는 인덱스 (An index that does not allow duplicate values): 이미 논리적 분류에서 설명했듯이, 중복된 데이터가 없도록 보장하는 인덱스이다. 유일성(Unique) 을 보장하는 데 매우 유용하다.
2️⃣ 인덱스 구조와 작동원리
(Mechanism and Structure of Index)
💡Keyword: Index Scan, Range Scan, Unique Scan, Full Scan, Fast Full Scan, Skip Scan, ROWID, Index Tree Structure, B-트리 (B-Tree), 리프 블록 (Leaf Block), 브랜치 블록 (Branch Block), 인덱스 최적화 (Index Optimization), I/O 성능 (I/O Performance), 검색 성능 (Query Performance), 정렬 순서 (Sort Order), 멀티블록 I/O (Multiblock I/O)
B-Tree 인덱스 - Balance Tree, 균형 트리⬇️
💡요약: B-트리는대부분의 데이터베이스에서 사용되고 있는 매우 중요한 인덱스 구조이다. 균형 트리 (Balanced Tree) 구조 덕분에 데이터 검색 속도가 빠르고 일정하게 유지되는 것이다. 대부분의 DBMS는 B-트리 인덱스를 사용하여 데이터를 효율적으로 검색하는 일반적인 형태의 인덱스 저장구조이다. 하지만 데이터 변경 작업(삽입, 수정, 삭제)이 많을 경우에는 성능이 저하될 수 있다.
균형트리는 양쪽 노드의 높이 차가 1 이하인 트리로 원하는 값을 찾고자 할 때 일정한 성능을 보장 (Balanced trees ensure consistent performance when searching for values, with a height difference of no more than 1 between the nodes):
B-트리는 균형 잡힌 트리 구조로, 트리의 양쪽 끝 노드들의 높이가 거의 동일하다. 즉, 어느 방향으로든 검색 속도가 일정하게 유지된다는 장점이 있다.
트리의 한쪽으로만 데이터가 치우치지 않기 때문에, 검색 성능이 일정하게 보장된다.
대부분의 DBMS는 B-Tree 구조를 사용하여 인덱스를 표현 (Most DBMS use B-Tree structures to represent indexes):
- 대부분의 데이터베이스 관리 시스템(DBMS)은 B-트리 구조를 사용해 데이터를 인덱싱한다. 이는 데이터가 빠르고 효율적으로 검색될 수 있도록 돕는 역할을 한다.
데이터의 검색(SELECT) 시에 뛰어난 성능을 보일 수 있음 (It provides excellent performance during data searches (SELECT)):
- B-트리는 데이터 검색 시(SELECT) 매우 빠르고 효율적이다. 트리 구조 덕분에 원하는 데이터를 빠르게 찾아낼 수 있다.
데이터의 변경(INSERT, UPDATE, DELETE) 시에 성능이 나빠짐 (Performance worsens during data changes (INSERT, UPDATE, DELETE)):
- 그러나 B-트리는 데이터 변경 작업이 많이 일어날 때, 예를 들어 삽입, 수정, 삭제 (INSERT, UPDATE, DELETE) 시에는 성능이 저하된다. 트리의 구조를 계속 유지해야 하기 때문이다. 이로 인해 검색에는 좋지만, 변경 작업에는 성능이 떨어질 수 있다.
B-Tree 인덱스 - 인덱스의 구성 #1 ⬇️
💡요약: 아래의 이미지는 B-Tree의 구조를 시각적으로 보여주고 있다. B-Tree는 데이터베이스에서 인덱스로 자주 사용되는 자료 구조이며, 효율적인 데이터 검색을 위해 계층적으로 데이터를 배치한다. B-Tree는 상단의 Branch Blocks 이 데이터 범위를 구분하고, 하단의 Leaf Blocks 에 실제 데이터가 저장되는 구조이다.

Branch Blocks (가지 블록):
가지 블록 (Branch Blocks) 은 트리의 상단에 위치하며, 데이터 범위 (Data Range) 를 기준으로 하위 블록들을 가리키고 있다.
예를 들어, 왼쪽 첫 번째 Branch Block은 0에서 40 사이의 데이터를 담당하고 있으며, 이 블록 아래에 더 세부적인 Leaf Blocks 이 있다. 이러한 Branch Blocks 들이 중간에 위치해 트리 구조를 형성하며, 상위에서 하위로 내려갈수록 더 구체적인 값들을 가리키어 데이터 범위를 좁혀 나간다.
Leaf Blocks (리프 블록):
리프 블록 (Leaf Blocks) 은 트리의 맨 아래에 있는 노드로, 실제 데이터 레코드 (ROWID) 를 포함하는데 이를 이용해서 실제 데이터를 조회할 수 있다.
예를 들어, Leaf Blocks 에는 "0
10", "1119" 등으로 범위가 나눠져 있으며, 각 블록이 구체적인 데이터와 ROWID (행의 고유 식별자)를 포함하고 있다.
B-Tree 인덱스 - 인덱스의 구성 #2 ⬇️
💡요약: 인덱스는 브랜치 블록 (Branch Block) 과 리프 블록 (Leaf Block) 으로 구성됩니다. 브랜치 블록은 데이터를 찾기 위한 경로를 제공하고, 리프 블록은 실제 데이터를 가리키는 ROWID를 포함 한다. 인덱스 깊이 (Index Height) 는 검색 성능에 영향을 미칠 수 있으며, 깊이가 클수록 더 많은 탐색 단계가 필요하다.브랜치 블록은 키 값 (Key Value) 과 주소 정보 (Address Information) 를 통해 데이터의 위치를 빠르게 찾을 수 있게 하고 리프 블록은 실제 위치 정보인 ROWID를 가지고 있기 때문에 실제 데이터를 빠르게 찾을 수 있게한다.
리프 블록은 항상 인덱스 키 값 순으로 정렬되어 있어, 범위 스캔 (Range Scan) 으로 특정 범위의 데이터를 빠르게 찾을 수 있다. 정방향(Ascending) 과 역방향(Descending) 스캔이 모두 가능하며, 양방향 연결 리스트 구조로 데이터를 두 방향 모두에서 쉽게 탐색할 수 있게 한다. Oracle과 SQL Server는 모두 null인 값을 인덱스에 저장하는 방식에서 차이가 있다: Oracle은 저장하지 않지만, SQL Server는 저장한다.
브랜치 (Branch) 블록과 리프 (Leaf) 블록으로 구성 (Composed of branch and leaf blocks):
- 인덱스는 크게 두 가지로 나뉜다. 위에서 언급 했듯이 브랜치 블록은 데이터를 빠르게 찾아가는 경로를 제공하고, 리프 블록은 실제 데이터의 위치를 나타낸다.
인덱스 깊이 (Height):
- 인덱스 깊이 (Height) 는 루트에서 리프 블록까지의 거리이다. 이 깊이가 클수록 인덱스를 탐색하는데 더 많은 단계가 필요하므로 성능에 영향을 미친다.
키 값 (Key Value)과 주소 정보 (Address Information):
- 루트와 브랜치 블록은 각 하위 노드들이 포함한 데이터의 범위를 나타내는 키 값 (Key Value) 과, 그 값을 가진 데이터를 찾기 위한 주소 정보 (Address Information) 를 포함하고 있다. 이를 통해 데이터베이스는 원하는 데이터를 빠르게 찾을 수 있게 한다.
리프 블록 (Leaf Block):
- 리프 블록은 인덱스 키 값 (Index Key Value) 과 그 값이 가리키는 데이터의 실제 위치 정보인 ROWID를 가지고 있다. 리프 블록에서 ROWID를 통해 테이블의 실제 데이터를 빠르게 찾을 수 있게 된다.
키 값이 같을 때 ROWID 순으로 정렬 (When key values are e same, sorted by ROWID):
- 만약 같은 키 값을 가진 데이터가 여러 개 있을 경우, ROWID 순으로 정렬되어 저장되게 된다. 이를 통해 데이터베이스는 데이터를 효율적으로 관리할 수 있다.
리프 블록은 항상 인덱스 키 (Index Key) 값 순으로 정렬되어 있기 때문에 범위 스캔 (Range Scan) 이 가능 (Leaf blocks are always sorted by index key values, making range scans possible):
- 리프 블록 안의 데이터는 인덱스 키 값에 따라 정렬되어 있다. 그래서 어떤 값을 찾을 때, 범위 스캔 (Range Scan) 을 사용할 수 있게 된다. 범위 스캔은 예를 들어 "100에서 200 사이의 값"을 빠르게 찾는 것처럼, 특정 범위에 해당하는 값들만 읽는 방법이다.
정방향 (Ascending) 과 역방향 (Descending) 스캔 둘 다 가능 (Both ascending and descending scans are possible):
- 정방향 (Ascending) 으로 데이터를 찾는 것뿐만 아니라, 역방향 (Descending) 으로도 찾을 수 있다. 이때, 양방향 연결 리스트 (Double Linked List) 구조로 되어 있어 두 방향으로 자유롭게 탐색할 수 있다.
✅간단한 예제: 예를 들어, 숫자가 1부터 100까지 있는 리스트가 있다고 생각해보자
정렬된 데이터: 이 리스트는 1, 2, 3, ..., 100 순서로 정렬되어 있다.
범위 스캔 (Range Scan): 만약 30에서 50 사이의 값을 찾고 싶다면, 1부터 29는 건너뛰고, 30부터 50까지의 값만 빠르게 찾아볼 수 있다.
정방향/역방향 탐색: 보통은 1부터 100까지 순서대로 보지만, 때로는 100부터 1로 거꾸로도 볼 수 있다.
✅ Oracle과 SQL Server에서의 차이점:
Oracle에서는 인덱스에 모두 null인 레코드가 저장되지 않는다. 즉, 인덱스를 구성하는 모든 컬럼이 null일 경우 인덱스에 해당 값이 안들어간다.
반면, SQL Server에서는 모두 null인 레코드도 인덱스에 저장된다.
인덱스 스캔(Index Scan)의 종류 ⬇️
총 5가지 종류의 인덱스 스캔 방식이 존재한다.
Index Range Scan (인덱스 범위 스캔): 범위 조건 (
BETWEEN,LIKE,>,<등)에 맞는 데이터를 스캔.Index Unique Scan (인덱스 유니크 스캔): 하나의 값을 빠르게 찾는 방식, 주로
=조건일 때 사용.Index Full Scan (인덱스 전체 스캔): 인덱스 트리 구조를 따라 모든 값을 정렬된 상태로 읽는 방식.
Index Fast Full Scan (인덱스 빠른 전체 스캔): 트리 구조를 무시하고 멀티블록 I/O로 인덱스 세그먼트를 빠르게 스캔, 순서 보장 없음.
Index Skip Scan (인덱스 스킵 스캔): 인덱스의 선두 컬럼이 조건에 없을 때 후행 컬럼으로 조건을 맞춰 스캔하는 방식, 선두 컬럼의 Distinct 값이 적고 후행 컬럼의 Distinct 값이 많을 때 유용.
아래에서 순서대로 각 인덱스 스캔의 종류에 대해 자세히 알아보자
인덱스 스캔(Index Scan) - Index Range Scan ⬇️
✅요약: 인덱스 범위 스캔 (Index Range Scan) 은 인덱스 루트 블록에서 리프 블록까지 탐색한 후 필요한 데이터 범위만 검색하는 방식이다. B-Tree 인덱스에서 가장 자주 사용되는 데이터 검색 방식이며, 특정 범위 내의 데이터만 빠르게 찾는 데 유리하다. 이 방식을 사용하면 데이터베이스가 전체 데이터를 읽지 않고도 필요한 정보만 빠르게 찾아낼 수 있게 된다.
인덱스 루트 블록에서 리프 블록까지 수직적으로 탐색한 후, 리프 블록을 필요한 범위 (Range)만 스캔하는 방식 (After vertically scanning from the index root block to the leaf block, it scans only the required range in the leaf blocks):
- 이 방식은 데이터베이스의 루트 블록에서 시작하여 리프 블록으로 내려간 다음, 그 안에서 특정 범위만 검색한다. 예를 들어, 숫자 100부터 200 사이의 값만 검색할 때 이 방식이 사용된다.
B-Tree 인덱스의 가장 일반적이고 정상적인 형태의 액세스 방식 (The most common and typical access method in B-Tree indexes):
- B-Tree 인덱스는 데이터베이스에서 가장 일반적으로 사용되는 인덱스 구조이며, 이 범위 스캔 방식이 가장 많이 쓰이는 데이터 조회 방식이다.
✅간단한 예제: 도서관에서 1번 선반에서 10번 선반까지 책이 있다고 가정
- 범위 스캔은 이 선반들 중에서 "5번 선반부터 7번 선반까지만 확인"하는 것이다. 다른 선반은 보지 않고, 필요한 범위만 빠르게 확인할 수 있기 때문에 시간을 절약할 수 있게 된다.
데이터베이스에서도 마찬가지로, 예를 들어 학생들의 성적이 저장된 테이블에서 "80점에서 90점 사이의 학생들만 찾기" 같은 작업을 할 때 인덱스 범위 스캔이 사용된다.

위 테이블의 EMPLOYEE_ID 와 EMAIL 컬럼에 각각 유니크 인덱스가 적용되어 있으며, 이는 데이터의 중복을 방지하고 빠른 검색을 가능하게 한다.
인덱스 스캔(Index Scan) - Index Range Scan ⬇️
각 쿼리는 특정 조건에 따라 employees 테이블에서 원하는 데이터를 검색하는 역할을 한다. 인덱스가 있으면 특정 조건으로 데이터를 조회할 때 필요한 데이터만 빠르게 찾을 수 있어 성능이 향상되고, 인덱스가 없으면 테이블 전체를 스캔해야 하기 때문에 성능이 저하되게 된다.

첫 번째 쿼리는 테이블 전체를 조회하기 때문에 전체 테이블 스캔 (Full Table Scan) 이 일어게 된다 즉, 테이블의 모든 데이터를 하나하나 읽는다는 뜻이다. 인덱스가 있어도 이 쿼리에는 영향을 주지 않기 때문에 인덱스를 활용할 수 없는 경우이다.
두 번째 쿼리는 last_name 이 'K'로 시작하는 데이터를 조회한다. last_name 이 'K'로 시작하는 데이터를 찾기 위해 전체 테이블 스캔을 해야 하는데 테이블의 모든 행을 처음부터 끝까지 읽으면서 조건에 맞는 데이터를 찾게 된다. 이 방식은 특히 테이블이 커질수록 매우 비효율적이게 된다. last_name 컬럼에 인덱스가 있다면, 이 쿼리는 인덱스 범위 스캔 (Index Range Scan) 을 사용할 수 있다. 인덱스가 데이터베이스에 미리 정렬된 상태로 저장되어 있기 때문에, K로 시작하는 값들만 빠르게 찾아낼 수 있게된다.
세 번째 쿼리는 email 이 'K'로 시작하는 데이터를 조회한다. 인덱스가 없다면 이 쿼리도 전체 테이블을 스캔하게 된다. email 컬럼이 'K'로 시작하는 값을 찾기 위해 모든 데이터를 읽으면서 조건을 확인해야 하기 때문에 비효율적이다. email 컬럼에 인덱스가 있다면, 이 쿼리도 인덱스 범위 스캔을 사용할 수 있다. 'K'로 시작하는 이메일만 빠르게 검색하고, 테이블의 나머지 데이터는 건너뛸 수 있기 때문에 성능이 크게 향상된다.
인덱스 스캔(Index Scan) - Index Range Scan SELECT * FROM employees;⬇️
💡요약: 첫 번째 쿼리 (SELECT * FROM employees;) 에서는 인덱스가 사용되지 않고, 전체 테이블 스캔이 발생하였다. 실행 계획에서는 테이블 전체를 스캔한 결과가 나와 있으며, 이는 인덱스가 사용되지 않은 쿼리 실행 결과임을 나타낸다.

SELECT * FROM employees;→ 테이블의 모든 데이터를 조회하는 쿼리로, 인덱스를 사용하지 않고 전체 테이블 스캔이 일어난다.쿼리 결과로 employees 테이블에서 직원 ID, 성, 이름, 이메일, 전화번호 등이 출력되었다. 쿼리가 조건에 맞는 데이터를 가져오는 것을 보여준다.

TABLE ACCESS (FULL): 이 항목은 테이블 전체를 스캔한 후 데이터를 가져오는 작업을 의미한다.
Object Name: EMPLOYEES 테이블에 대한 액세스가 이루어졌으며, 이 과정에서 인덱스가 사용되지 않았음을 보여준다.
인덱스 스캔(Index Scan) - Index Range Scan SELECT * FROM employees WHERE last_name like 'K%’;⬇️
💡요약: last_name 이 'K'로 시작하는 데이터를 범위 스캔을 통해 빠르게 찾는 쿼리이다. 범위 스캔은 인덱스를 사용하여 필요한 데이터 범위만 조회하기 때문에, 쿼리 성능이 향상된다. 이 쿼리는 인덱스가 사용되지 않았다.

이 SQL 쿼리는 employees 테이블에서 last_name(성)이 'K'로 시작하는 모든 행을 찾는 쿼리이다.
LIKE 'K%'는 'K'로 시작하는 모든 값을 의미한다. 예를 들어, King, Kochhar 같은 값들이 검색된다.
이 쿼리에서는 인덱스 범위 스캔(Index Range Scan) 을 사용해 last_name 이 'K'로 시작하는 데이터만 빠르게 스캔하였다. 인덱스를 통해 특정 범위의 데이터를 찾을 수 있어 성능이 향상된다.

TABLE ACCESS: FULL 전체 테이블 스캔을 의미한다. 즉, 이 쿼리는 인덱스를 사용하지 않고, 테이블의 모든 데이터를 읽은 후 WHERE 절의 조건에 맞는 데이터를 필터링한 것이다. Filter Predicates에 LAST_NAME LIKE 'K%' 조건이 추가되어 있다.
만약 인덱스가 사용되었다면, 실행 계획에서 "INDEX RANGE SCAN" 또는 "INDEX FULL SCAN" 등의 인덱스 관련 용어가 나왔을 것이다. 이 쿼리에서는 인덱스가 실행되지 않았다.
인덱스 스캔(Index Scan) - Index Range Scan SELECT * FROM employees WHERE email like 'K%’;⬇️

이 쿼리는 employees 테이블에서 email이 'K'로 시작하는 행들을 찾는 쿼리이다.
LIKE 'K%'는 이메일이 'K'로 시작하는 값을 의미한다. 예를 들어, KCHUNG, KGRANT 같은 값이 결과로 나온다.

- 이 쿼리는 인덱스 범위 스캔 (Index Range Scan) 을 사용하고 있다.
INDEX (EMP_EMAIL_UK): 이 실행 계획에서 EMP_EMAIL_UK 인덱스가 사용되었다. 이는 email 컬럼에 대한 유니크 인덱스이다.
Access Predicates: EMAIL LIKE 'K%'라는 조건을 기반으로 데이터에 접근하는 부분이다. 이는 'K'로 시작하는 이메일을 찾는 조건을 의미다.
TABLE ACCESS: 인덱스를 사용해 'K'로 시작하는 이메일을 먼저 찾아낸다. 그 다음, 인덱스를 통해 얻은 ROWID를 사용해 해당 데이터가 테이블의 어느 위치에 있는지를 알아낸다. 그 ROWID를 통해서 테이블에서 정확한 데이터를 찾아서 읽는다.
✅위의 쿼리들과 차이점: 이전 쿼리들에서는 TABLE ACCESS (FULL) 을 통해 전체 데이터를 읽었지만, 이번 쿼리는 INDEX RANGE SCAN을 통해 email 컬럼에서 'K'로 시작하는 데이터만 선별적으로 검색한 것이다.
인덱스 스캔(Index Scan) - Index Unique Scan ⬇️
💡요약: Index Unique Scan 은 유일한 값을 찾기 위해 사용되는 스캔 방식으로, 유니크 인덱스가 설정된 컬럼에 '=' 조건을 사용할 때 작동한다. 일치하는 값을 찾으면 바로 검색을 멈추므로, 매우 빠르게 데이터를 찾아낼 수 있다. 예시 쿼리인 employee_id = '101' 에서 employee_id가 유일한 값이므로, Index Unique Scan 을 통해 빠르게 데이터를 찾아내었다. 특히 프라이머리 키나 유니크 인덱스가 적용된 컬럼에서 데이터를 조회할 때 성능을 크게 향상시킨다.

수직적 탐색만으로 데이터를 찾는 스캔 방식 (Vertical scan method to find data):
Index Unique Scan은 데이터를 수직적으로만 탐색하는 방식이다. 이는 데이터를 빠르게 찾는 데 매우 효과적이다.
Unique 인덱스를 활용하여, 해당 컬럼에서 유일한 값을 바로 찾을 수 있다.
Unique 인덱스를 '=' 조건으로 탐색하는 경우에 작동 (Operates when scanning with '=' condition on a Unique index):
- '=' 조건을 사용할 때, 예를 들어 employee_id = '101' 같은 쿼리를 실행하면, 해당 유니크 인덱스를 통해 employee_id가 101인 데이터를 바로 찾을 수 있게 된다.
일치하는 값을 찾은 경우 바로 멈춤 (Stops immediately when a matching value is found):
- 이 방식은 일치하는 값을 찾으면 즉시 탐색을 멈추고 결과를 반환한다 테이블의 다른 행들을 더 이상 검색할 필요가 없기 때문에 매우 빠르다.

INDEX (EMP_EMP_ID_PK): 프라이머리 키 인덱스가 사용되었다.
Access Predicates: employee_id = '101' 조건이 적용되어 있다.
UNIQUE SCAN: 유일한 값이므로 한 번의 탐색으로 데이터를 찾고 종료한다.
인덱스 스캔(Index Scan) - Index Full Scan ⬇️
💡요약: Index Full Scan은 인덱스가 완벽하게 매칭되지 않을 때 사용되는 방식으로, 수평적으로 인덱스를 처음부터 끝까지 스캔하는 방식이다.
수직적 탐색 없이 인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식 (Scans the leaf blocks of the index from start to finish horizontally without vertical search):
Index Full Scan 은 데이터를 수직적으로 빠르게 찾는 것이 아닌, 인덱스의 처음부터 끝까지 수평적으로 스캔하는 방식이다.
데이터베이스는 인덱스의 모든 블록을 처음부터 끝까지 차례대로 읽는다.
대개의 경우, 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택 (Usually selected when there is no optimal index for data search):
데이터베이스에 최적의 인덱스가 없는 경우, Index Full Scan 이 차선책으로 선택된다.
즉, 인덱스가 있어도 최적화된 인덱스가 아니거나, 데이터의 일부만 필요하지 않을 때 발생한다.

위의 쿼리는 employees 테이블에서 salary가 2000 이상인 직원들의 정보를 department_id와 last_name으로 정렬해서 가져오고 있다.
실행 계획: TABLE ACCESS (FULL) 이는 테이블 전체를 스캔하고, 그 결과를 정렬(ORDER BY) 하는 과정을 보여주고 있다. 인덱스가 제대로 사용되지 않았기 때문에 테이블의 전체 데이터를 읽은 후 정렬 작업을 수행한다.
💡위의 예시처럼 employees 테이블에서 salary가 2000 이상인 직원들의 정보를 department_id와 last_name으로 정렬하는 쿼리는 특정 조건이 충족되지 않으면 인덱스를 활용하기 어렵다. 이유로는
WHERE salary > 2000는 salary 컬럼을 기준으로 조건을 걸지만,ORDER BY department_id, last_name는 정렬 기준이 다르다. 일반적으로 정렬을 위해서는 해당 컬럼들에 대한 인덱스가 필요하다. 그러나 salary에 대한 범위 조건이 걸리면서 정렬 기준과 상충되는 인덱스 사용이 어렵게 된다.만약 이 쿼리를 효율적으로 처리하기 위한 인덱스를 만들고자 한다면, 복합 인덱스를 생성할 수 있다. (아래 참조) 복합인덱스 방식은 데이터를 자주 검색하고 특정 조건과 정렬 기준이 복잡할 때 매우 유용하게 사용될 수 있다.

위의 이미지는 Index Full Scan (인덱스 풀 스캔) 의 실행 후, 새로운 인덱스를 생성하고 다시 실행한 결과를 보여준다. 새로운 위에서 언급된 복합 인덱스를 만들어 데이터를 더 빠르게 조회하려는 시도를 확인할 수 있다.
인덱스 생성 (Creating Index):
쿼리:
CREATE INDEX emp_idx_test1 ON employees(department_id, last_name, salary);이 명령어는 employees 테이블에서 department_id, last_name, salary 컬럼에 대해 복합 인덱스 (Composite Index) 를 생성하는 과정이다.
복합 인덱스는 여러 개의 컬럼에 대해 동시에 인덱스를 설정해, 해당 조건으로 검색할 때 더 빠르게 결과를 가져올 수 있도록 한다.
쿼리 실행 후 인덱스 생성 확인:
- 인덱스가 성공적으로 생성되었음을 하단의 메시지에서 확인할 수 있다. 이로 인해
SELECT department_id, last_name, salary FROM employees WHERE salary > 2000 ORDER BY department_id, last_name;이 쿼리가 더 효율적으로 실행될 수 있게 되었다.
- 인덱스가 성공적으로 생성되었음을 하단의 메시지에서 확인할 수 있다. 이로 인해
쿼리 실행 과정 (Query Execution):
쿼리:
SELECT department_id, last_name, salary FROM employees WHERE salary > 2000 ORDER BY department_id, last_name;이 쿼리는 salary가 2000을 초과하는 직원들의 정보를 department_id와 last_name을 기준으로 정렬해서 가져오는 것이다.
새롭게 생성한 복합 인덱스 덕분에 이 쿼리의 정렬(ORDER BY)과 조건(salary > 2000) 처리가 더 빨라졌다.


복합 인덱스 (Composite Index) 가 생성된 후 다시 실행된 결과와 실행 계획을 통해 쿼리가 어떻게 처리되는지 설명하고 있다.
이 쿼리는 salary가 2000을 초과하는 직원들을 찾아 department_id와 last_name을 기준으로 정렬하여 가져오는 명령어이다.
복합 인덱스는 여러 컬럼에 동시에 인덱스를 설정해, 조건과 정렬이 복합적으로 걸린 쿼리를 효율적으로 처리할 수 있도록 돕는 역할을 한다.
쿼리가 실행되었을 때, EMP_IDX_TEST1 인덱스가 사용되어 데이터를 풀 스캔 (Full Scan) 하는 방식으로 접근한다.
Access Predicates (접근 조건): salary > 2000 조건을 충족하는 데이터를 찾는다.
Filter Predicates (필터 조건): 동일하게 salary > 2000을 기준으로 데이터를 필터링한다.
쿼리 실행 시간이 0.034초로 표시되어 있으며, 이는 인덱스가 적용된 후 쿼리 성능이 매우 빠르게 처리된 것을 보여준다.
인덱스 스캔(Index Scan) - Index Full Scan의 경우와 선택 상황 ⬇️
💡요약: Index Full Scan은 대량의 데이터를 다루면서도 정렬이나 조건 검색을 효율적으로 처리하고 싶을 때 사용되는 방식이다.
인덱스 선두 컬럼이 조건절에 없을 때:
- Table Full Scan은 인덱스가 없거나 선두 컬럼(Index Leading Column)이 조건절에 사용되지 않았을 때 발생하지만 인덱스가 있다면 Index Full Scan을 통해 더 효율적으로 검색할 수 있다.
대용량 테이블에서 인덱스 사용:
- 대용량 테이블에서 Table Full Scan이 너무 많은 부담을 주는 경우에는 인덱스를 활용하는 것이 더 효율적일 수 있다. 즉, 테이블 크기가 클수록 인덱스를 사용해 일부 데이터를 검색하는 것이 더 나은 선택이다.
인덱스로 결과를 얻을 수 있는 경우:
인덱스가 충분히 유용하다면, Index Full Scan을 고려할 수 있다.
특히 ORDER BY나 GROUP BY 구문에 인덱스가 적용된 컬럼이 있을 때, 인덱스를 통해 정렬 또는 그룹화된 데이터를 빠르게 검색할 수 있다.
인덱스 스캔 단계에서 필터링:
- 인덱스 스캔을 통해 대부분의 데이터를 필터링할 수 있고, 일부 데이터에만 테이블을 액세스할 경우 Index Full Scan이 효율적일 수 있다. 즉, 인덱스를 통해 필요 없는 데이터를 걸러내고 나머지 데이터를 빠르게 조회할 수 있다.
인덱스 스캔(Index Scan) - Index Fast Full Scan ⬇️
💡요약: Index Fast Full Scan은 인덱스의 트리 구조를 무시하고, 인덱스 세그먼트 전체를 멀티블록 단위로 읽는 방식이다. 이 방식은 더 많은 데이터를 더 빠르게 읽어야 하는 상황에서 효율적이기 때문에 주로 인덱스에 포함된 컬럼들만을 빠르게 조회해야 할 때 Index Fast Full Scan을 사용한다.

Index Full Scan (인덱스 전체 스캔):
인덱스 트리 구조를 따라서 데이터를 순차적으로 스캔한다.
결과가 정렬된 순서로 반환된다.
한 번에 Single Block I/O (하나의 블록만 읽음)로 작동하며, 병렬 스캔 불가능하다.
인덱스에 포함되지 않은 컬럼까지도 조회할 때 사용 가능하다.
Index Fast Full Scan (인덱스 빠른 전체 스캔):
인덱스 트리 구조를 건너뛰고, 인덱스 세그먼트 전체를 스캔한다.
결과 순서가 보장되지 않으며, 데이터의 순서가 유지되지 않는다.
Multiblock I/O (여러 블록을 한꺼번에 읽음)로 작동하며, 병렬 스캔이 가능하다
인덱스에 포함된 컬럼만을 조회할 때 사용된다.
인덱스 스캔(Index Scan) - Index Skip Scan ⬇️
💡요약: 인덱스를 사용할 때 모든 칼럼을 조건으로 걸지 않더라도 조건에 맞는 가능성이 있는 블록만 선택하여 데이터를 검색하는 방식이다. 이 방식은 테이블의 칼럼 특성에 따라 효율적으로 데이터 검색을 수행할 수 있는 기법이다.
Index Skip Scan 방식:
루트(Root)나 브랜치(Branch) 블록에서 읽은 칼럼 값 정보를 이용해 조건에 맞는 레코드를 포함할 가능성이 있는 하위 블록(리프 블록)만 골라서 접근한다.
모든 블록을 확인하는 것이 아니라, 조건에 맞는 가능성이 있는 블록만 선택적으로 탐색하기 때문에, 성능이 더 효율적이다.
Distinct Value가 적고 많을 때:
조건절에 빠진 인덱스 선두 칼럼의 Distinct Value(고유 값 개수)가 적고, 후행 칼럼의 고유 값 개수가 많을 때 Index Skip Scan이 유용하다.
예를 들어, 성별과 이메일 칼럼이 있을 때, 성별은 고유 값이 적지만(남/여 두 가지뿐), 이메일은 매우 다양한 고유 값이 있을 수 있다. 이 경우, Index Skip Scan이 효율적으로 데이터를 검색할 수 있다.
SQL 예제:
예를 들어, 성별과 이메일로 인덱스를 구성했을 때, 다음과 같은 SQL 쿼리에서 성별이 조건에 없더라도 Index Skip Scan을 사용하여 이메일로 검색할 수 있다.
SELECT * FROM customers WHERE cust_email = 'Abbey@company.com';
3️⃣ 인덱스 생성과 관리
(Create and Manage of Index)
💡Keyword: CREATE INDEX DROP INDEX ALTER INDEX
인덱스 생성과 삭제 - 인덱스 자동 생성 #1 ⬇️
💡요약: PRIMARY KEY (기본키) 를 설정하면 자동으로 해당 컬럼들에 대해 인덱스가 생성된다. UNIQUE (유일키) 제약 조건도 자동으로 인덱스를 생성해, 중복된 데이터를 방지할 수 있다. 따라서 별도로 인덱스를 생성할 필요 없이 데이터베이스가 자동으로 인덱스가 생성된다.

기본키 (Primary Key) 와 유일키 (Unique Key) 를 사용할 때 인덱스가 자동으로 생성되는 예시를 알아보자.
- CREATE TABLE 문은 새로운 테이블을 만드는 SQL 문이다.
이 예시에서는
tbl_name이라는 테이블을 만들고, 4개의 컬럼이 정의되어 있다:key1: 문자열 타입 VARCHAR2(10), 최대 10자까지 입력 가능key2: 문자열 타입 VARCHAR2(20), 최대 20자까지 입력 가능col1: 숫자 타입 NUMBER, 이 컬럼에 UNIQUE 제약 조건이 걸려 있어 중복된 값을 허용하지 않는다.col2: 문자열 타입 VARCHAR2(100), 최대 100자까지 입력 가능
PRIMARY KEY 제약 조건이 key1과 key2에 설정되어 있어, 이 두 컬럼의 조합이 테이블 내에서 고유해야 한다.
인덱스 생성과 삭제 - 인덱스 자동 생성 #2⬇️


- 기본키와 유일키 제약 조건이 포함된 테이블이 성공적으로 생성되었음을 보여주는 결과이다.
인덱스 생성과 삭제 - 인덱스 자동 생성 #3⬇️

위의 SQL 결과는 테이블에 기본키 (Primary Key)와 유일키 (Unique Key) 제약 조건을 적용할 때, 인덱스가 자동으로 생성된다는 것을 보여주고 있다. 첫 번째 이미지는 테이블에 설정된 제약 조건을, 두 번째 이미지는 그 제약 조건에 의해 생성된 인덱스를 나타낸다.
인덱스 생성과 삭제 - 인덱스 수동 생성 #1 ⬇️
💡요약: 인덱스를 수동으로 생성할 때, CREATE INDEX 명령어로 고유 인덱스나 비트맵 인덱스를 만들 수 있으며, 기본적으로 오름차순 정렬로 인덱스가 생성된다.
CREATE [UNIQUE | BITMAP] INDEX 인덱스명
ON 테이블명 (컬럼 [ASC | DESC], 컬럼 [ASC | DESC], ...)
[TABLESPACE 테이블스페이스명];
CREATE INDEX 명령어를 사용하여 인덱스를 생성할 수 있으며, 인덱스의 종류는 기본적으로 고유 인덱스 (Unique)와 비트맵 인덱스 (Bitmap)로 나뉜다.
고유 인덱스(Unique): 중복된 값이 없는 인덱스.
비트맵 인덱스(Bitmap): 비트맵 구조로 값을 저장하는 인덱스.
컬럼 정렬에서 기본 값은 오름차순 (Ascending, ASC)으로 설정된다. 그러나 필요에 따라 내림차순 (Descending, DESC)도 설정할 수 있다.
테이블스페이스 (Tablespace)를 별도로 지정할 수 있어, 인덱스가 특정 물리적 저장 위치에 저장되도록 설정할 수 있다.
✅비트맵(Bitmap)구조로 값을 저장한다는 뜻은? 비트맵 인덱스(Bitmap Index)는 0과 1로 이루어진 비트맵 구조로 값을 저장하는 방식이다. 구체적으로 설명하자면, 각 인덱스 값마다 해당 값이 어떤 행(row)에 있는지를 나타내는 비트 벡터(0과 1로 구성된 배열)를 사용한다. 비트맵 인덱스는 특히 값의 범위가 적고, 데이터를 빠르게 검색할 때 유리합니다. 값의 범위가 적다는 뜻은 자주 변경되지 않는 컬럼에 적합하다는 뜻이기도 하다. 예를 들어, 성별, 국가 같은 값들이 자주 바뀌지 않기 때문에 비트맵 인덱스를 사용하기 좋다.
인덱스 생성과 삭제 - 인덱스 수동 생성 #2 ⬇️
💡요약: SQL은 인덱스를 생성한 후, 그 인덱스가 시스템에 반영된 것을 확인하고, 필요시 삭제하는 작업을 보여주는 예시인데 참고로 아직 삭제(DROP)는 실행되지 않았다.

CREATE UNIQUE INDEX 구문을 사용하여
idx_uni_test라는 유니크 인덱스를tbl_name테이블의col2컬럼에 생성하고 있다.SELECT 구문을 통해
user_indexes테이블에서 인덱스 목록을 조회하고 있다. 여기서 생성된 인덱스idx_uni_test가 목록에 표시된다.
인덱스 생성과 삭제 - 인덱스 삭제⬇️
✅DROP INDEX 명령을 사용해 인덱스를 삭제하면, 그 인덱스는 복구 불가능하다. 삭제된 인덱스는 데이터베이스에서 완전히 제거되기 때문에, 다시 사용하려면 직접 재생성해야 한다는 점을 기억하자. 따라서 중요한 인덱스를 삭제할 경우, 미리 백업하거나 해당 인덱스의 구성 정보를 기록해 두는 것이 좋다. 인덱스 자체는 테이블의 데이터에 영향을 주지 않지만, 성능에 중요한 역할을 할 수 있으므로 삭제 전에 신중하게 고려해야 한다.

인덱스 삭제에 대해서 살펴보자. 맨 위에 부분은 위에서 언급했으므로 스킵하고 DROP INDEX 인덱스명;을 보면, 이 쿼리를 사용하여 기존에 생성된 인덱스를 삭제할 수 있다.
CREATE UNIQUE INDEX idx_uni_test ON tbl_name(col2);명령문은tbl_name테이블의col2열에 대해 고유 인덱스를 생성하였다.DROP INDEX idx_uni_test;명령문은 방금 생성된idx_uni_test인덱스를 삭제하는 역할을 한다.
인덱스 관리 - 인덱스 분석의 과정⬇️
💡요약: 인덱스 분석 (Index Analysis) 과정을 알아보자. 데이터베이스의 인덱스는 시간이 지나고 입력, 수정 등의 작업이 일어나면서 균형이 흐트러지게 된다. 이러한 균형이 깨지면 성능이 저하될 수 있으므로, 정기적으로 인덱스를 분석하고 재구성해야 한다. 이때 ANALYZE INDEX 명령을 사용하여 인덱스를 분석하고, 그 구조의 유효성을 검사할 수 있다. 명령을 실행하면 INDEX_STATS라는 테이블에 결과가 저장된다.

인덱스는 시간이 지남에 따라 균형이 흐트러질 수 있다.
주기적으로 인덱스를 분석하고 재구성하는 것이 중요하다.
ANALYZE INDEX 인덱스명 VALIDATE STRUCTURE 명령을 사용하여 인덱스의 구조를 분석할 수 있다.
ANALYZE INDEX 인덱스명 VALIDATE STRUCTURE위 명령은 인덱스의 구조를 점검하고, 그 인덱스가 제대로 작동하는지 확인하는 명령이다. 이 명령을 사용하면 인덱스가 손상되었는지 또는 정상적으로 작동하는지 확인할 수 있게 된다. 인덱스를 오랫동안 사용하다 보면 데이터가 추가되거나 삭제되면서 구조에 문제가 생길 수 있는데, 이 명령은 그런 문제를 찾아준다.쉽게 말해, "인덱스가 잘 작동하는지 점검하는 도구"라고 생각하자. 이 명령을 실행하면 데이터베이스는 인덱스를 검사한 결과를 기록해준다.
인덱스 관리 - 인덱스 분석 실습 - 실습을 위한 emp_temp 테이블 생성 #1⬇️
💡요약: emp_temp는 employees 테이블의 복사본이라고 보면 된다. 이를 통해 실습이나 테스트 용도로 데이터를 수정하거나 실험할 수 있다.

CREATE TABLE emp_temp AS SELECT * FROM employees;이 쿼리는 employees 테이블의 데이터를 그대로 복사하여 emp_temp라는 새로운 테이블을 만든다.SELECT * FROM emp_temp;생성된 emp_temp 테이블에서 모든 데이터를 선택하여 결과를 보여준다.
인덱스 관리 - 인덱스 분석 실습 #2 인덱스 idx_emp_temp 생성 인덱스 분석 수행 ⬇️
💡요약: SQL 질의 결과1은 idx_emp_temp 인덱스가 생성된 후의 통계 정보를 보여주고 있다. 여기에는 인덱스의 높이(HEGIHT), 블록 수(BLOCKS), 리프 행 수(LF_ROWS) 등이 포함되어 있다. (맨 아래줄)

CREATE INDEX idx_emp_temp ON emp_temp(employee_id);이 명령어는emp_temp테이블의employee_id컬럼에 대해idx_emp_temp라는 인덱스를 생성하는 명령어이다.ANALYZE INDEX idx_emp_temp VALIDATE STRUCTURE;이 명령어는 인덱스의 구조를 분석하고, 그 결과를 저장한다.SELECT * FROM index_stats;마지막으로 인덱스의 분석 결과를index_stats에서 조회하여 인덱스에 대한 통계 정보를 확인하는 명령어이다.
✅index_stats란? index_stats는 Oracle 데이터베이스에서 ANALYZE INDEX 명령을 사용하여 인덱스를 분석할 때 그 결과를 저장하는 내부 테이블이다.
이 테이블에는 각 인덱스의 구조적인 통계 정보가 저장되게 된다. index_stats는 사용자가 직접 생성하거나 관리하는 테이블은 아니며, Oracle이 인덱스를 분석한 결과를 임시로 저장하는 뷰(View)라고 생각하자. 이 안에 들어가는 HEIGHT, BLOCKS, LF_ROWS 등은 인덱스의 효율성을 판단하고, 인덱스 구조에 문제가 있거나 최적화가 필요한지 여부를 확인하는 데 사용된다.
인덱스 관리 - 인덱스 밸런스 계산 (Index Balance Calculation) #1⬇️
💡요약: 인덱스 밸런스는 데이터가 변경될 때 인덱스의 성능을 유지하기 위한 중요한 요소이다. 정기적인 인덱스 밸런스 분석은 성능 문제를 미리 감지하고 해결할 수 있게 도와준다.
인덱스의 성능이 시간이 지나면서 어떻게 변하는지 알아보자
인덱스는 처음 생성되었을 때 최적의 성능을 가진다.
- (Indexes initially have optimal performance)
삽입, 삭제, 수정 작업이 반복되면 데이터가 변경되고, 인덱스의 성능이 점차 저하된다.
- (Insert, delete, and update operations cause changes in data, which may degrade the index's performance over time.)
인덱스 밸런스 (Index Balance)란 인덱스가 좌우 균형 잡힌 구조를 유지하는지 확인하는 지표이다.
- (The index balance shows if the index has a balanced structure, where nodes are evenly distributed.)
밸런스 계산 공식은 인덱스에서 삭제된 데이터의 비율을 확인하는데, 이는 성능 저하의 원인을 파악하는 데 중요한 역할을 한다.
- (The balance calculation formula checks the proportion of deleted data in the index, which is crucial for identifying performance issues.)
SELECT (del_lf_rows_len / lf_rows_len) * 100
FROM index_stats;
- 위의 명령어는 삭제된 행의 비율을 계산하는 SQL 쿼리이다.. 이 값이 클수록 인덱스의 성능 저하 가능성이 커진다.
인덱스 관리 - 인덱스 밸런스 계산 (Index Balance Calculation) #2⬇️

인덱스 밸런스는 인덱스가 치우친 정도를 숫자로 표현한다. 이 숫자가 클수록 인덱스가 불균형하게 되어 성능이 저하될 가능성이 높다.
- (It shows the skewness of the index as a number. The higher the number, the more likely the index is unbalanced and its performance degraded.)
0이 가장 좋은 상태로, 20을 넘으면 인덱스를 재구성해야 한다.
- (0 is the best state, and if the value exceeds 20, the index may need to be rebuilt.)
하단의 쿼리는 삭제된 리프 노드 길이와 전체 리프 노드 길이의 비율을 계산해, 인덱스가 얼마나 불균형한지 보여주는 역할을 한다.
- (The query at the bottom calculates the ratio between the deleted leaf node length and the total leaf node length, indicating how unbalanced the index is.)
결과값은 DEL_LF_ROWS_LEN / LF_ROWS_LEN * 100 으로, 삭제된 데이터가 전체 인덱스에 차지하는 비율을 퍼센트로 반환하게 된다.
- (The result is shown as DEL_LF_ROWS_LEN / LF_ROWS_LEN * 100, returning the percentage of deleted data in the entire index.)
인덱스 관리 - 인덱스 밸런스 계산 (Index Balance Calculation) #3⬇️
💡요약: 아래의 이미지는 첫번째 이미지의 결과인 0과는 다르게 47.660~의 결과를 보여주고 있다. 이는 대규모 삭제 연산 후 인덱스가 불균형해졌으며, 이 불균형을 바로 잡기 위해 인덱스 재구성이 필요할 수 있음을 의미하고 있다.

DELETE 문:
emp_temp테이블에서employee_id가 150 이하인 데이터를 삭제한다. 이는 인덱스에 영향을 미치며, 삭제된 데이터로 인해 인덱스가 불균형해질 수 있다.- (The
DELETEstatement removes entries whereemployee_idis less than or equal to 150 from theemp_temptable. This affects the index and could cause it to become unbalanced.)
- (The
ANALYZE INDEX 문: 인덱스
idx_emp_temp의 구조를 검증(분석)한다. 이 명령을 통해 인덱스가 얼마나 불균형한지 파악할 수 있다.- (The
ANALYZE INDEXstatement validates the structure of the indexidx_emp_tempto determine how unbalanced the index is.)
- (The
SELECT 쿼리: 인덱스의 삭제된 리프 노드와 전체 리프 노드 비율을 계산하는 공식이다. 계산 결과 47.66%로 나타나며, 이는 삭제된 데이터가 전체 데이터의 거의 절반에 해당함을 의미한다.
- (The
SELECTquery calculates the ratio of deleted leaf nodes to total leaf nodes. The result shows 47.66%, meaning almost half of the data in the index has been deleted.)
- (The
인덱스 관리 - 인덱스 재구성 (Index Rebuild) ⬇️
💡요약: 대규모 삭제 연산 후 불균형해진 인덱스의 균형을 맞추기 위해 “재구성”을 살펴보자. ALTER INDEX 명령어로 인덱스를 재구성할 수 있으며, 특히 REBUILD는 기존 인덱스를 기반으로 새로운 인덱스를 생성하지만, 컬럼의 정렬은 유지된다는 특징이 있다. (ALTER INDEX command allows you to rebuild indexes, especially with REBUILD, which creates a new index but maintains the column order.)

ALTER INDEX 명령어 (ALTER INDEX command)는 기존의 인덱스를 바탕으로 REBUILD 또는 COALESCE 옵션을 사용하여 인덱스를 재구성하는 역할을 한다.
REBUILD (재구성)는 기존 인덱스를 기반으로 새로운 인덱스를 생성한다. 그러나 컬럼의 정렬을 변경할 수는 없다.
- (REBUILD creates a new index based on the existing one, but cannot change the column order.)
또한, REVERSE 키워드를 사용하여 인덱스의 유형을 변경할 수 있다.
- (The REVERSE keyword can be used to change the type of the index.)
인덱스 관리 - 인덱스 밸런스 계산 인덱스 재구성 결과 : 밸런스 값이 0이 됨 ⬇️
💡요약: 인덱스 재구성 후 밸런스 값이 0: 인덱스를 재구성함으로써, 삭제된 행 비율이 0이 되었고, 이는 인덱스가 균형 있게 정리되었음을 알수 있다. 인덱스의 성능이 저하될 때, ALTER INDEX REBUILD 명령을 사용하여 인덱스를 새로 생성하는 것이 중요하다

ALTER INDEX idx_emp_temp REBUILD; 명령을 통해 인덱스를 재구성하고, 재구성 후 인덱스의 밸런스를 다시 분석하였다.
SELECT 구문을 통해 인덱스의 삭제된 행 비율을 확인했을 때, 밸런스 값이 0이 나온다. 이는 인덱스가 잘 재구성되었음을 의미한다.
인덱스 관리 - 인덱스 재구성 ⬇️
인덱스 성능 저하를 방지하거나 복구하기 위해 사용되는 재구성에는 두 가지 옵션, REBUILD(재구성)과 COALESCE(병합)이 있다. REBUILD는 인덱스의 전체를 다시 만드는 강력한 방법이고, COALESCE는 더 빠르고 적은 리소스를 사용하는 대신, 부분적인 최적화를 제공하는 방법이다.
REBUILD: 인덱스 전체를 재구성(Rebuilds the entire index)하는 방식이다. 인덱스를 처음부터 다시 만드는 것이기 때문에 시간이 더 걸릴 수 있지만, 성능에 가장 큰 영향을 줄 수 있다.
COALESCE: 최하위 리프 블록만 재구성(Rebuilds only the leaf blocks)하는 방식으로, 주로 삭제된 데이터로 인해 조각난 공간을 연속적인 공간으로 합쳐준다. 전체를 재구성하는 것보다 빠르고 적은 자원을 소모하지만, 효과는 상대적으로 적다.
- 조각난 공간을 연속적인 공간으로 합쳐줌 (Merges fragmented space into contiguous space) 정도의 기능을 제공한다.




