Contents
1️⃣ 자료구조의 개요
2️⃣ 자료구조의 분류와 유형별 특징
3️⃣ 파이썬의 자료형
1️⃣ 자료구조의 개요
자료구조의 개념

- 자료구조의 개념:
자료구조는 데이터를 효율적으로 저장, 접근, 수정하기 위한 함수나 명령어를 포함한 구조체를 의미한다. 즉, 데이터를 관리하고 처리하는 방식에 대한 체계적 구조를 의미한다.
- 자료구조와 알고리즘과의 관계:
자료구조는 데이터를 저장하고 관리하는 도구를 제공한다.
알고리즘은 이러한 자료구조를 사용하여 데이터를 조작하고, 특정 작업을 수행한다.
따라서, 💡자료구조는 데이터를 저장하는 방식이고, 💡알고리즘은 그 데이터를 이용해 효율적으로 문제를 해결하는 방법을 의미한다.
자료구조의 분류와 유형별 특징 #1:
자료구조의 분류

자료구조는 크게 스칼라형, 선형, 비선형으로 나눌 수 있다. 자료구조는 데이터의 저장과 접근 방식을 결정하는 중요한 개념이며, 선형 자료구조는 데이터가 순차적으로 배열되는 반면, 비선형 자료구조는 보다 복잡한 연결 관계를 가지는 특징이 있다. 스칼라형은 단일 데이터를 저장하는 기본 자료형들로 이루어져 있다.
1. 스칼라 (Scalar)
뜻: 단일 값을 가진 데이터를 의미한다.
설명: 스칼라는 크기만으로 표현되는 값을 뜻하며, 하나의 숫자, 문자 등 단일 요소를 나타낸다. 예를 들어, 정수(int), 실수(float), 문자(char) 같은 기본 자료형이 스칼라에 해당한다.
2. 선형 (Linear)
뜻: 데이터가 일렬로 나열된 구조를 의미한다.
설명: 선형 자료구조는 데이터를 순차적으로 배열하며, 데이터들이 일직선으로 연결된 형태이다. 배열(array), 리스트(list), 스택(stack), 큐(queue)와 같은 구조가 선형 자료구조에 속한다. 데이터를 차례로 처리하거나 순서대로 접근할 수 있는 특성을 가진다.
3. 비선형 (Non-linear)
- 뜻: 데이터가 여러 방향으로 연결된 구조를 의미한다.
- 설명: 비선형 자료구조는 데이터가 단순히 일렬로 나열되지 않고, 계층적이거나 복잡한 연결 구조를 가진다. 예를 들어, 트리(tree)나 그래프(graph)는 비선형 자료구조에 속한다. 이런 구조에서는 한 데이터가 여러 데이터와 연결될 수 있어, 복잡한 관계를 나타낼 수 있다.
💡요약
스칼라: 단일 값 (예: 정수, 실수, 문자)
선형: 데이터가 일렬로 나열된 순차적 데이터 구조 (예: 배열, 리스트, 스택, 큐)
비선형: 일직선으로 나열되지 않고 계층적 또는 복잡한 연결 구조 (예: 트리, 그래프)
자료구조의 분류와 유형별 특징 #2:
배열(Array)

1. 배열의 개념요약
정의: 배열은 연속된 공간에 데이터를 저장하고, 인덱스를 통해 각 값에 빠르게 접근하는 장점이 있지만 크기가 고정되어 있고 중간에 삽입/삭제가 어려운 단점이 있다. 이러한 특성으로 인해 고정된 크기의 데이터를 처리하거나, 삽입/삭제가 빈번하지 않은 경우에 적합한 자료구조입니다.
구조: 배열의 각 요소는인덱스를 가지고 있어, 인덱스를 통해 빠르게 원하는 요소를 찾아 접근할 수 있다. 배열은 메모리 상에서 연속적으로 저장된다.
인덱스(index) 배열에서 데이터의 위치를 나타내는 번호이다. 데이터는 연속된 메모리 공간에 저장되며, 각 데이터에 접근하기 위해서 인덱스를 사용한다.
2. 배열의 특징:
동일한 자료형의 값만 저장(Only values of the same data type can be stored) : 배열은 처음 선언될 때 같은 자료형의 값들로만 구성된다. 예를 들어, 정수형 배열은 오직 정수형 값만 저장할 수 있다.
크기가 고정(The size is fixed): 배열의 크기는 선언될 때 고정되며, 이후에 크기를 변경할 수 없다. 즉, 한 번 설정된 배열의 크기는 늘리거나 줄일 수 없다.
중간에 값 삽입 또는 삭제가 어려움(It is difficult to insert or delete values in the middle): 배열의 중간에 새로운 값을 삽입하거나 기존 값을 삭제하는 작업은 어려운 편이다. 이를 위해서는 다른 요소들을 이동시켜야 하므로 시간이 많이 소요되게 된다.
자료구조의 분류와 유형별 특징 #3:
리스트(List)

리스트 개념 요약:
정의: 리스트는 값과 포인터를 쌍으로 갖는 노드들이 포인터로 연결된 자료구조이다. 각 노드는 데이터 값과 다음 노드를 가리키는 포인터로 이루어져 있다.
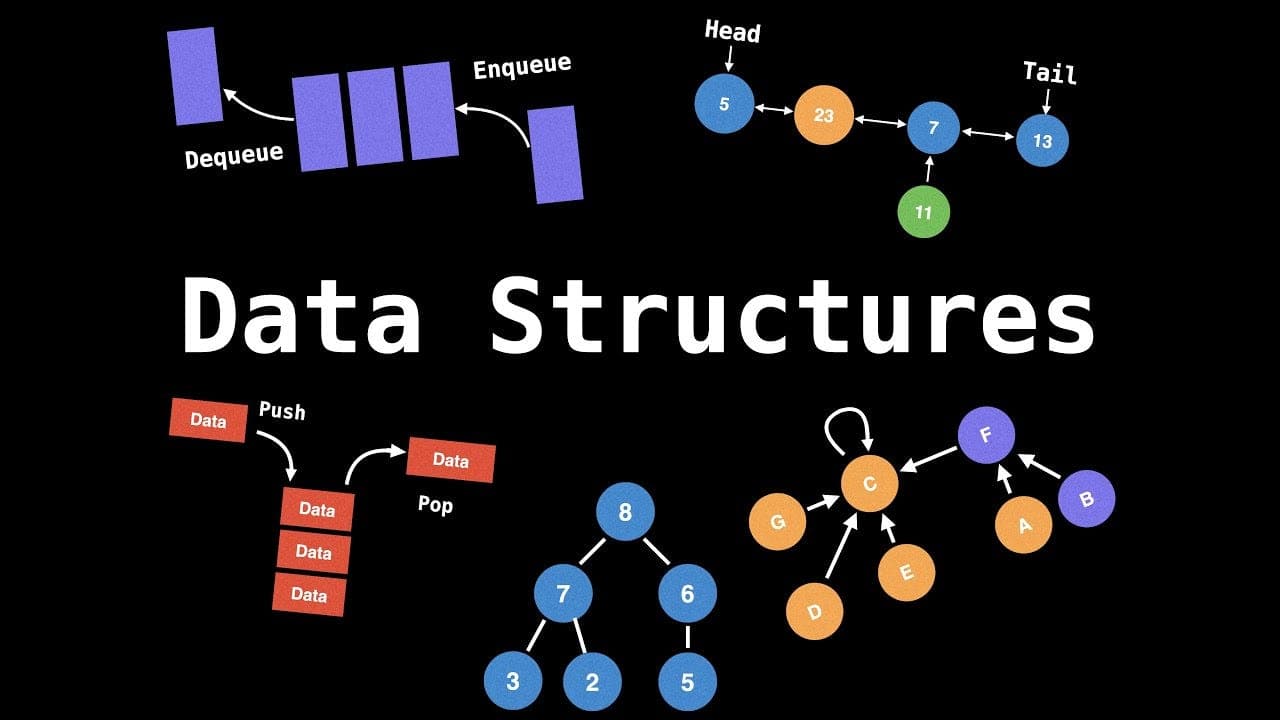
구조: 리스트의 첫 번째 노드를 Head, 마지막 노드를 Tail이라고 부르며, 각 노드는 다음 노드로 연결된다. 리스트는 배열과 달리 연속된 메모리 공간에 저장되지 않으며, 각 노드는 임의의 위치에 저장된다. 크기가 가변적이며, 중간 삽입/삭제가 용이한 장점이 있지만, 순차적으로 접근해야 한다는 단점이 있다. 리스트는 데이터를 자주 삽입하거나 삭제해야 하는 경우에 적합한 자료구조이다.
리스트의 특징:
순차적 접근(Sequential access)
- 특정 노드에 접근하려면 Head에서부터 순차적으로 접근해야 한다. 인덱스가 없기 때문에 원하는 데이터를 찾기 위해선 리스트의 앞에서부터 차례대로 탐색해야 한다.
가변적인 크기(Variable size)
- 리스트는 배열과 달리 크기가 고정되지 않고 가변적이다. 즉, 리스트의 크기는 데이터가 추가되거나 삭제될 때마다 동적으로 변한다고 할 수 있다.
삽입과 삭제가 용이(Easy insertion and deletion)
- 리스트는 중간에 새로운 값을 삽입하거나 기존 값을 삭제하는 작업이 용이하다. 포인터만 변경하면 되기 때문에, 배열처럼 데이터의 이동이 필요하지 않다.
자료구조의 분류와 유형별 특징 #4:

스택(Stack)
스택은 가장 나중에 들어온 데이터가 가장 먼저 나가는 자료구조, 즉 LIFO(Last In, First Out) 방식으로 동작한다. 삽입과 삭제는 항상 top에서 이루어진다. 파이썬의 경우 리스트를 사용하여 스택을 쉽게 구현할 수 있다. 스택은 데이터의 순서가 중요한 작업에 적합한 자료구조이다.
1. 스택의 개념
정의: 스택은 가장 최근에 삽입된 데이터가 가장 먼저 삭제되는 구조이다. 데이터의 삽입과 삭제가 한쪽 끝(top)에서 이루어진다.
연산 과정: 스택에서는 데이터를 삽입(push)하거나 삭제(pop)할 때, top에 있는 데이터가 대상이 된다. 따라서, 가장 나중에 추가된 데이터가 가장 먼저 나가게 된다.
2. 스택의 특징
삽입과 삭제는 top에서 결정: 스택은 top이라는 포인터 하나를 사용하여 삽입과 삭제를 관리한다. 모든 연산이 top을 기준으로 이루어지기 때문에, top이 바뀌면서 새로운 데이터가 추가되거나 제거된다.
리스트를 활용한 구현 가능: 파이썬에서는 리스트(List)를 활용하여 스택을 쉽게 구현할 수 있다. 리스트의 append() 메서드를 통해 데이터를 추가하고, pop() 메서드를 통해 데이터를 제거할 수 있다. 이를통해 자료구조의 스택 개념을 사용한 것을 알 수있다.
자료구조의 분류와 유형별 특징 #5:

큐(Queue)
큐는 가장 먼저 들어온 데이터가 가장 먼저 나가는 자료구조로, FIFO(First In, First Out) 방식으로 동작한다. 데이터의 삽입은 rear, 삭제는 front에서 이루어진다. 일상생활의 선착순 개념과 유사하며, 먼저 들어온 데이터가 먼저 처리되는 상황에 적합한 자료구조이다.
1. 큐의 개념:
정의: 큐는 가장 먼저 들어온 데이터가 가장 먼저 나가는 방식으로 동작하는 자료구조이다. 데이터를 삽입하는 위치는 rear이고, 데이터를 삭제하는 위치는 front이다.
연산 과정: 큐에서는 데이터가 rear에서 삽입되고, front에서 삭제됩니다. 즉, 먼저 삽입된 데이터가 먼저 나가게 되는 구조이다.
2. 큐의 특징:
양방향 포인터 사용: 큐는 데이터를 삽입할 때는 rear 포인터에서, 데이터를 삭제할 때는 front 포인터에서 작업이 이루어진다. 양방향으로 데이터의 출입이 일어나게 된다.
일상생활의 선착순과 같은 개념: 큐는 일상생활에서의 선착순과 유사한 개념이다. 예를 들어, 줄을 서서 대기하는 상황과 같아서, 먼저 온 사람이 먼저 처리되는 것과 같다.
자료구조의 분류와 유형별 특징 #6:

그래프(Graph)
그래프는 정점(Vertex)과 간선(Edge)으로 구성된 복잡한 자료구조로, 정점 간의 연결 관계를 나타낸다. 이를 효율적으로 처리하기 위해 다른 자료구조를 사용하며, 그래프는 여러 알고리즘에서 중요한 요소로 다뤄지고 있다.
1. 그래프의 개념:
정의: 그래프는 정점(Vertex, 노드)과 간선(Edge, 정점을 연결하는 선)으로 구성된 자료구조이다. 정점들은 서로 간선으로 연결되어 네트워크와 같은 구조를 형성한다.
구성 요소:
정점(Vertex): 그래프의 각 노드.
간선(Edge): 정점 간의 연결을 나타냄.
2. 그래프의 특징:
다른 자료구조의 필요성: 그래프를 표현하기 위해서는 에지 리스트(edge list), 인접 행렬(adjacency matrix), 인접 리스트(adjacency list)와 같은 다른 자료구조가 필요하다. 이는 그래프의 연결 관계를 효율적으로 저장하고 탐색하기 위해 사용된다.
알고리즘에서 중요하게 다뤄짐: 그래프는 다양한 알고리즘에서 중요한 역할을 하며, 특히 경로 탐색Pathfinding (예: 최단 경로 shortest path), 네트워크 분석(network analysis) 등에서 핵심적으로 사용된다.
자료구조의 분류와 유형별 특징 #7:

트리(Tree)
트리는 정점과 간선 간에 순환(사이클)이 없는 그래프의 일종으로, 계층적인 구조를 가진다.부모-자식 관계로 노드들이 연결된다. 트리는 그래프의 일종이지만 순환(사이클)이 없는 특징이 있으며, 데이터의 탐색과 정렬에 매우 유용한 자료구조이다. 다양한 트리의 종류는 각기 다른 용도로 사용된다.
1. 트리의 개념:
정의: 트리는 정점과 간선으로 이루어진 자료구조로, 순환(사이클)이 없는 그래프이다.트리에는 한 개의 루트 노드가 있으며, 루트에서부터 자식 노드로 연결되는 구조이다.
구성 요소:
루트(Root): 트리의 시작점이 되는 노드.
부모(Parent)와 자식(Child): 부모 노드는 다른 노드들을 가리키며, 자식 노드는 그 부모 노드로부터 연결된 노드를 말한다.
2. 트리의 특징:
루트 노드가 존재: 트리는 한 개의 루트 노드를 가지고 있으며, 루트 노드에서 시작해 다른 노드들과 연결된다.
부모-자식 관계: 루트 노드를 제외한 모든 노드는 한 개의 부모 노드를 가지고 있다. 자식 노드는 여러 개가 있을 수 있다.
다양한 트리의 종류: 트리는 여러 종류가 있으며, 이진 탐색 트리(Binary Search Tree), AVL 트리, 레드-블랙 트리(Red-Black Tree), B-트리 등이 있다. 각 트리는 삽입, 삭제, 탐색에서의 성능과 특성에 따라 사용된다.
자료구조의 분류와 유형별 특징 #8:

주요 자료구조와 연관된 알고리즘
배열 (Array):
- 정렬 알고리즘: 버블 정렬, 선택 정렬, 퀵 정렬, 병합 정렬 등 배열에 저장된 데이터를 정렬하는 알고리즘.
- 선택 알고리즘: 배열 내에서 최소값이나 최대값을 찾는 알고리즘.
스택 (Stack):
- 깊이 우선 탐색 (DFS): 그래프나 트리의 깊은 부분을 우선적으로 탐색하는 알고리즘. , 스택은 함수 호출의 기본 매커니즘과 연관이 있다.
큐 (Queue)
- 너비 우선 탐색 (BFS): 그래프나 트리의 넓은 부분을 우선적으로 탐색하는 알고리즘
그래프(Graph)
너비 우선 탐색 (BFS): 정점을 차례로 방문하는 알고리즘.
깊이 우선 탐색 (DFS): 그래프의 깊은 부분을 먼저 탐색하는 알고리즘.
최소 신장 트리 (MST): 모든 노드를 연결하는 최소 비용의 간선을 선택하는 알고리즘.
최단 경로 탐색: 그래프에서 두 정점 간의 최단 경로를 찾는 알고리즘 (예: 다익스트라 알고리즘).
트리 (Tree)
이진 탐색 트리 (Binary Search Tree): 중위순회 방식으로 데이터를 정렬하는 트리 구조.
레드-블랙 트리 (Red-Black Tree): 자동으로 균형을 유지하는 이진 탐색 트리.
B-트리: 대용량 데이터를 저장하기 위한 트리 구조로, 노드가 다수의 자식을 가질 수 있는 트리.
3️⃣ 파이썬의 자료형
파이썬의 자료형

💡요약 파이썬의 자료형은 크게 단순형과 복합형으로 나뉜다. 파이썬에서는 리스트를 사용해 배열과 리스트의 기능을 모두 구현할 수 있기 때문에, 굳이 이 둘을 구분할 필요가 없다. 이는 파이썬의 자료형이 매우 유연하다는 것을 보여주며, 인덱스 접근, 삽입, 삭제가 모두 가능하여 배열, 리스트와 같은 자료구조를 쉽게 구현할 수 있게한다.
1. 파이썬의 자료형:
단순형(Simple type): 숫자, 문자열, 불(Bool)과 같이 하나의 값을 저장하는 자료형이다.
복합형(Complex type): 리스트(List), 튜플(Tuple), 딕셔너리(Dictionary), 집합(Set)과 같은 여러 값을 저장할 수 있는 자료형이다.
2. 리스트의 특징:
배열과 리스트의 특징 모두 포함: 파이썬의 리스트는 컴퓨터 공학에서의 배열과 리스트의 특징을 모두 포함한다.
배열처럼 인덱스로 데이터에 접근할 수 있으며,
리스트처럼 삽입과 삭제가 용이하다.
구분할 필요 없음: 파이썬에서는 배열과 리스트를 구분할 필요가 없으며, 리스트 하나만으로도 배열과 리스트의 기능을 모두 구현할 수 있.
파이썬의 단순자료형(Simple datatype of Python)

💡요약 파이썬의 주요 자료형으로 숫자, 문자열, 불(boolean)이 있다. 파이썬의 자동 형변환은 편리하지만, 특히 나누기 연산과 같은 경우에는 다른 자료형으로 변환될 수 있으므로 프로그래머가 주의를 기울여야 한다.
1. 파이썬의 단순 자료형:
숫자:
정수(
int): 예를 들어23, -54, 0과 같은 값.실수(
float): 예를 들어54.23, -3.4e6과 같은 값.2진수(
bin): 예를 들어0b0101과 같은 값.8진수(
oct): 예를 들어0o67과 같은 값.16진수(
hex): 예를 들어0x4FF와 같은 값.
문자열(
str): 예를 들어"boy"와 같은 값.불(Boolean)(
bool):True,False값을 가진다.
2. 💡Key Point - 자동 형변환 주의:
파이썬은 자동으로 형변환을 수행하는 경우가 있다. 이는 편리하지만, 때때로 의도하지 않은 결과를 초래할 수 있으므로 주의해야 한다.
예를 들어,
/연산자는 실수를 반환하지만,//연산자는 정수를 반환한다. 따라서 사용 시 주의해야 한다.
파이썬의 리스트

파이썬의 리스트는 배열과 리스트 자료구조의 특성을 모두 갖추고 있으며, 인덱스를 통한 접근, 슬라이싱 기능과 함께 원소 삭제, 추가, 삽입과 같은 동작을 지원한다. 이는 리스트를 매우 유연하게 사용할 수 있게 하며, 배열과 리스트를 구분하지 않아도 파이썬에서 쉽게 자료구조를 다룰 수 있게 한다.
1. 파이썬 리스트의 선언:
리스트 선언은 대괄호(
[])로 감싸서 이루어진다.예를 들어,
list_b = [56, 2, 6, 2]와 같이 선언할 수 있다.이때, 리스트는 컴퓨터 공학에서의 배열과 리스트의 특성을 모두 가지고 있다.
2. 파이썬 리스트의 배열적 특성:
인덱스를 통한 접근: 대괄호
[]를 사용하여 리스트의 특정 인덱스에 있는 원소에 접근할 수 있다. 예:list_b[0]는56에 접근.슬라이싱:
:를 사용하여 리스트의 일부분을 가져올 수 있습니다. 예:list_b[1:3]은[2, 6]을 반환. (리스트 슬라이싱에서 사용되는[start:end]구문은 시작 인덱스는 포함하고, 끝 인덱스는 포함하지 않는 방식으로 동작)인덱스 반환:
index()메서드(method)를 통해 리스트에서 특정 값이 있는 인덱스를 찾을 수 있다.
3. 파이썬 리스트의 리스트적 특성:
삭제:
del키워드를 사용하여 리스트의 원소를 삭제할 수 있다.- 예:
del list_b[1]은list_b의 두 번째 원소를 삭제합니다.
- 예:
추가:
append()메서드를 통해 리스트 끝에 원소를 추가할 수 있다.- 예:
list_b.append(10)은 리스트의 끝에10을 추가한다.
- 예:
중간에 원소 추가:
insert()메서드를 사용하여 리스트 중간에 원소를 삽입할 수 있다.- 예:
list_b.insert(1, 99)은 인덱스 1 위치에99를 추가한다.
- 예:
첫 번째 원소 제거:
remove()메서드를 통해 첫 번째로 등장하는 특정 값을 제거할 수 있다.마지막 원소 꺼내기:
pop()메서드를 통해 리스트의 마지막 원소를 꺼내서 제거할 수 있다.
파이썬의 튜플

튜플은 리스트와 유사하지만, 원소값을 변경할 수 없다는 특징을 가진다. 튜플은 불변성을 가지고 있어, 데이터를 수정하지 않고 안정적으로 유지해야 할 때 적합하다. 선언 방식은 리스트와 유사하지만, 원소 값을 변경할 수 없다는 점이 주요 차이점이다.
1. 튜플의 선언:
튜플은 소괄호
()로 선언되며, 여러 값을 담을 수 있다.예를 들어,
tuple_c = (56, 2, 6, 2)와 같은 방식으로 튜플을 선언할 수 있다.
2. 파이썬 튜플의 특징:
불변성: 리스트와 달리, 한 번 선언된 튜플의 값은 변경할 수 없다. 즉, 튜플은 불변(immutable)한 자료형다.
사용 목적: 프로그램이 실행되는 동안 원소값을 변경할 필요가 없을 때 사용된다. 예를 들어, 좌표나 설정값과 같이 변하지 않는 데이터를 저장할 때 유용하다
나머지 기능은 리스트와 유사: 튜플은 불변성을 제외한 다른 기능들은 리스트와 유사하게 동작한다. 예를 들어, 인덱스를 사용해 값을 참조할 수 있다.
파이썬의 딕셔녀리

딕셔너리는 key와 value를 쌍으로 가지는 자료형으로, 배열처럼 인덱스로 접근하는 것이 아니라 key를 통해 사람 친화적으로 데이터 접근이 가능하다. 또한, 데이터 삽입과 삭제가 용이하지만, 중복된 key는 하나만 인식되므로 주의해야 한다.
1. 딕셔너리의 선언:
딕셔너리는 중괄호
{}를 사용해 선언되며, key와 value는 콜론(:)으로 연결된다.예를 들어,
dic_d = {1:'one', 2:'two', 3:'three'}와 같은 방식으로 선언할 수 있다.각각의 key-value 쌍은 콤마(,)로 구분된다.
2. 파이썬 딕셔너리의 특징:
Key를 사용한 접근: 배열이 인덱스로 값을 접근하는 것과 달리, 딕셔너리는 key를 사용해 값을 접근한다. 사람에게 친숙한 방식으로 데이터에 접근할 수 있다.
삽입 및 삭제 용이: 리스트처럼 데이터의 삽입과 삭제가 매우 용이하다. 딕셔너리에 새로운 key-value 쌍을 추가하거나, 기존의 key를 통해 값을 삭제할 수 있다.
중복 키 처리: Key가 중복되면, 딕셔너리는 하나의 key만 인식하고, 중복된 key 중 나중에 선언된 값을 사용하게 되므로 주의하자.
파이썬의 집합

파이썬의 집합은 중복을 허용하지 않으며, 순서가 없는 자료형이라는 특징을 가지고 있다. 수학적인 집합 연산을 쉽게 처리할 수 있는 자료형이다. 이러한 집합을 리스트나 튜플로 변환할 수 있어 유연하게 사용할 수 있다.
1. 집합의 선언:
파이썬에서 집합을 선언할 때는
set()을 사용한다.예를 들어,
set_e = set([56, 7, 2, 1])와 같은 방식으로 집합을 선언할 수 있다.
2. 파이썬 집합의 특징:
중복을 허용하지 않음: 집합에서는 중복된 값이 자동으로 제거된다. 즉, 동일한 값이 여러 번 들어가도 하나의 값으로 인식된다.
순서가 없음: 집합은 순서가 없는 자료형이므로, 리스트나 튜플처럼 인덱스를 사용해 접근할 수 있다.
수학적 연산 가능: 파이썬 집합은 수학적 연산인 교집합(&), 합집합(|), 차집합(-) 연산을 할 수 있다.
3. 파이썬 집합의 사용:
원소 추가:
add()메서드를 통해 원소를 추가할 수 있다.여러 원소 추가:
update()메서드를 사용해 여러 개의 원소를 추가할 수 있다.특정 값 제거:
remove()메서드를 통해 특정 값을 제거할 수 있다.리스트나 튜플로 변환: 집합을 리스트나 튜플로 변환하여 사용할 수도 있다.
학습정리





