Inter-Process Communication (IPC): Signals, Pipes, FIFO, and Shared Memory
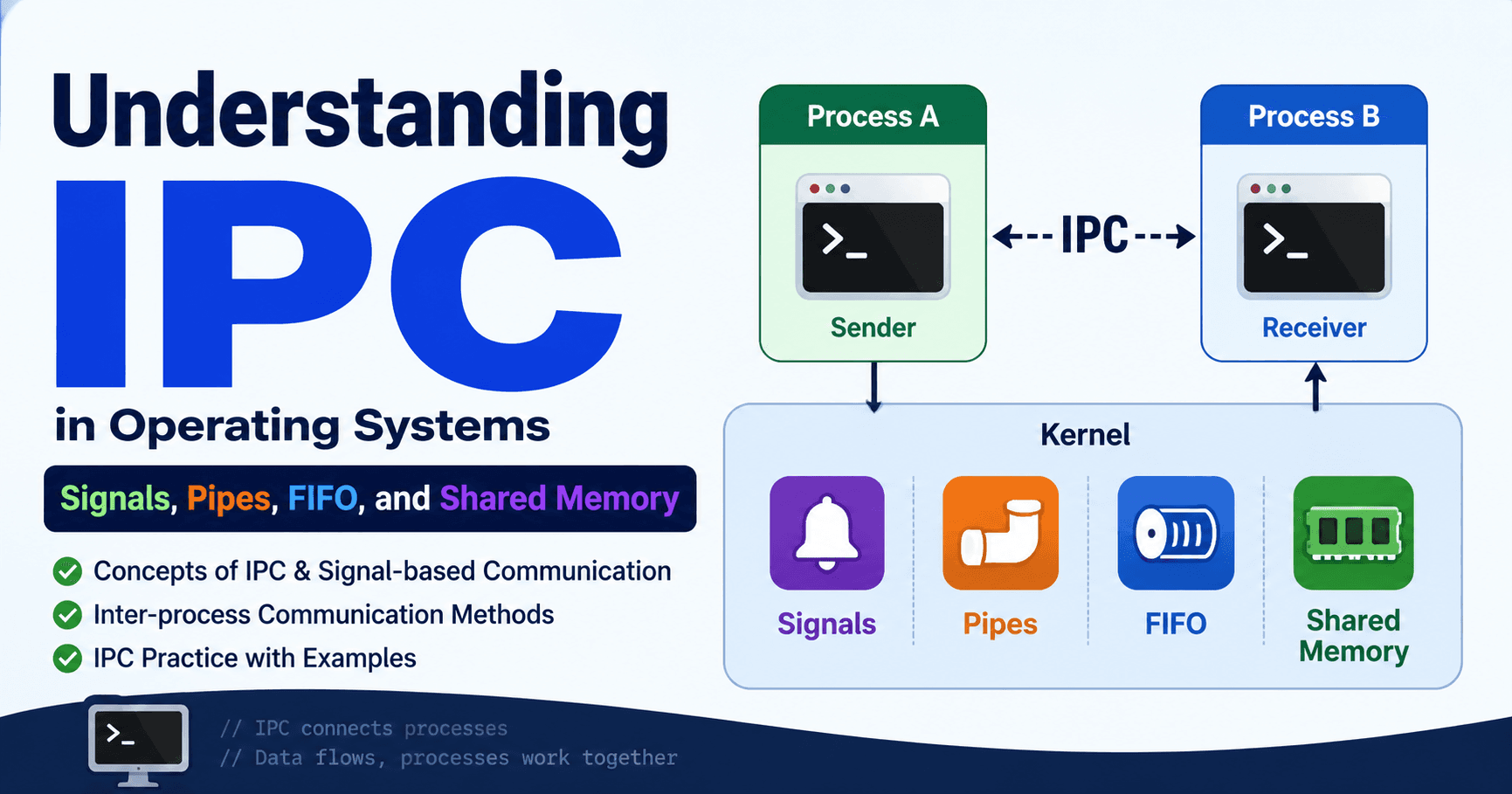
1️⃣ Concepts of Inter-process Communication and Signal-based Communication
2️⃣ Inter-process communication methods
3️⃣ Inter-process Communication Practice
프로세스 간 통신 (Inter-Process Communication, IPC)
이번 주차의 주제는 프로세스 간 통신(IPC, Inter-Process Communication)이다. 여러 프로세스가 동시에 실행될 때, 이들이 어떻게 데이터를 주고받는지, 그리고 이러한 통신이 어떤 구조와 방법으로 이루어지는지에 대해 살펴본다.
이번 주차의 목표는 다음과 같다. 먼저, 프로세스 간 통신의 개념과 필요성을 이해한다. 이어서 운영체제에서 제공하는 다양한 통신 방식에 대해 알아본다. 또한 파이프(Pipe), FIFO(Named Pipe), 공유 메모리(Shared Memory)와 같은 통신 방법의 특징과 차이점을 구분할 수 있어야 한다. 마지막으로 관련 시스템 호출(System Call)을 활용하여 간단한 통신 프로그램을 구현하고, 그 결과를 통해 실제 동작 과정이 어떻게 이루어지는지 확인한다.
오늘 학습은 이러한 내용들을 중심으로 진행된다.
프로세스 간 통신의 필요성에 대한 예시
하나의 상황을 가정해보자. 친구들과 단체 채팅방에서 과제 공지가 공유된다고 할 때, 한 사람이 과제 내용을 채팅방에 올리면 다른 사람들은 그 내용을 확인하고 과제를 준비하게 된다. 그런데 이 메시지가 누군가에게 전달되지 않는다면 어떻게 될까? 또한 각자가 따로 정보를 알고 있다면 전체 과제를 제대로 진행할 수 있을까? 이처럼 여러 사람이 정보를 공유할 때, 정보 전달이 어떻게 이루어지는지 생각해볼 수 있다.
또 다른 상황을 가정해보자. 터미널에서 어떤 프로그램이 실행 중일 때, 사용자가 컨트롤 C를 입력하면 실행 중인 프로그램이 갑자기 종료된다. 이 경우 프로그램 내부에서는 종료 명령을 직접 수행하지 않았음에도 불구하고 왜 종료되는 것일까? 또한 운영체제는 이러한 외부 입력을 프로그램에 어떻게 전달하는 것일까?
이와 같은 상황을 통해 프로그램과 운영체제 간의 통신 방식에 대해 살펴본다.

프로세스 간 통신 (IPC) 개념과 필요성
이번 챕터에서는 프로세스 간 통신의 개념과 시그널 기반의 통신에 대해 알아본다.
IPC는 Inter-Process Communication의 약자로, 여러 프로세스들이 서로 정보를 주고받기 위해 운영체제가 제공하는 기능이다. 여러 사람이 협력하여 일을 수행하기 위해 서로 정보를 전달해야 하듯이, 운영체제에서도 여러 프로세스가 협력 작업을 수행하기 위해서는 정보 교환이 필요하다.
이러한 통신이 필요한 이유는 다음과 같다. 첫째, 프로세스 간에 데이터를 전달하기 위해 필요하다. 둘째, 여러 프로세스가 협력하여 하나의 작업을 수행하기 위해 필요하다. 셋째, 특정 이벤트나 상태 변화를 다른 프로세스에 전달하기 위해 사용된다.
즉, IPC는 단순한 데이터 전달을 넘어서 프로세스 간의 협력과 제어를 가능하게 하는 핵심 기능이다.

프로세스 간 통신이 필요한 이유
프로세스는 각각 독립된 주소 공간(Address Space)을 가지기 때문에 다른 프로세스의 메모리에 직접 접근할 수 없다. 예를 들어, 어떤 프로그램이 데이터를 생성하더라도 다른 프로그램이 해당 메모리를 직접 읽어오는 것은 불가능하다.
이러한 한계를 보완하기 위해 운영체제는 프로세스 간에 정보를 주고받을 수 있는 다양한 통신 방법을 제공한다. 결국 프로세스 간의 정보 전달을 위해 IPC가 필요하게 된다.

결국 한 프로세스의 작업 결과를 다른 프로세스가 바로 사용할 수 없고, 실행 중에 발생하는 상태나 이벤트도 즉시 전달되지 않는다. 따라서 운영체제는 이러한 문제를 해결하기 위해 IPC 기능을 제공한다.


프로세스 간 통신 방법
이러한 IPC 기능은 여러 가지 방법으로 제공된다. 각 방법은 데이터를 전달하는 방식과 사용 목적에 따라 차이가 있다.
먼저 pipe는 한 프로세스에서 다른 프로세스로 데이터를 순서대로 전달하는 방식이다.
message queue는 데이터를 메시지 단위로 나누어 전달하는 방식이다.
shared memory는 하나의 메모리 공간을 사용하여 보다 빠르게 데이터를 공유하는 방식이다.
즉, 이들은 데이터 전달과 데이터 공유를 위한 대표적인 IPC 방법들이다.
이어서 signal은 어떤 이벤트가 발생했다는 것을 간단하게 알려주는 방식이다. 예를 들어, 사용자가 control + C를 누르면 프로그램이 종료되는데, 이때 signal이 전달되면서 해당 동작이 이루어진다.
마지막으로 socket은 네트워크를 기반으로 통신하는 방식이다. 이는 같은 컴퓨터뿐만 아니라 다른 컴퓨터에 있는 프로그램과도 데이터를 주고받을 수 있는 통신 방식이다.

Signal 기반 프로세스 간 통신
signal은 프로세스에 특정 이벤트 발생을 알리는 운영체제의 비동기 신호(asynchronous signal)라고 볼 수 있다. 이 신호는 주로 예외 상황이나 프로세스를 제어하기 위한 목적으로 사용된다.
여기서 중요한 점은 signal은 데이터를 전달하는 방식이 아니라, 이벤트 발생 자체를 알리는 데 목적이 있다는 것이다. 또한 signal을 받게 되면 프로세스의 흐름이 중간에 바뀔 수 있다.
이러한 신호는 운영체제가 자동으로 해당 프로세스에 전달하며, 프로세스는 해당 signal에 따라 종료되거나 특정 동작을 수행하게 된다.

Signal Delivery Mechanism
이러한 signal은 이벤트를 알려주는 방식이라고 설명할 수 있다. 이 신호가 실제로 어떻게 전달되는지를 전달 구조로 보면 다음과 같다.
한 프로세스에서 signal이 발생한다.
이 신호는 운영체제를 통해 전달되며, 운영체제가 대상 프로세스에게 signal을 넘겨준다.
signal을 받는 프로세스는 그에 맞는 처리를 수행한다.
이 과정에서 signal 상태는 프로세스의 **PCB(Process Control Block)**에 기록되어 지속적으로 관리된다.

Signal 처리 과정 (signal handling process)
앞에서 본 전달 흐름을 조금 더 구체적으로 보면, 프로세스 B에서 signal A가 발생하게 되면 이 신호는 바로 프로세스 A로 전달되는 것이 아니라 운영체제를 통해 처리된다.
운영체제는 해당 신호를 대상 프로세스, 즉 프로세스 A의 PCB(Process Control Block)에 기록하게 된다. 이후 프로세스 A는 자신에게 전달된 signal을 확인한 후, 해당 신호에 대한 처리를 수행하게 된다.

그림으로 표현하면, 오른쪽 상단의 프로세스 B에서 signal A가 발생하면 이 신호는 커널(Kernel)로 전달된다. 이후 커널은 이 signal을 프로세스 A의 PCB에 기록하게 되고, 프로세스 A는 signal을 전달받아 해당 신호에 대한 처리를 수행하는 흐름으로 진행된다.

Signal의 처리 방식
signal이 전달된 이후의 처리 방식은 하나로 정해져 있는 것이 아니라 상황에 따라 선택할 수 있다. 아무 설정을 하지 않으면 프로세스를 종료하거나, 멈추거나, 다시 실행하는 기본 동작으로 처리된다.
또한 필요에 따라 signal을 무시할 수도 있으며, 특정 signal이 왔을 때 사용자가 직접 정의한 함수로 처리하도록 설정할 수도 있다.

프로세스가 signal을 받게 되면 종료되거나, 일시적으로 멈추거나, 다시 실행되는 상태로 바뀌게 되는데 이러한 것들이 기본 동작의 예이다. 즉, signal은 데이터를 주고받는 것이 아니라 프로세스의 상태를 변경하는 역할을 한다고 볼 수 있다.
따라서 signal의 처리 방식은 프로세스가 미리 설정할 수 있다.
시그널 처리 방식의 대표적인 시그널 예시 (examples of signal handling)
아래의 Signal들은 실제로 자주 사용되는 대표적인 Signal들이다.

우리가 control + C를 누르면 발생하는 SIGINT는 실행을 중단시키는 역할을 한다.
다음으로 SIGTERM에서 TERM은 terminate를 의미하며, 프로세스에 정상적으로 종료하라는 요청을 보내는 signal이다.
그리고 SIGKILL은 프로세스를 강제로 즉시 종료시키는 signal이다.

또한 실행을 멈추거나 다시 이어가는 signal들도 있다.
SIGSTOP은 실행 중인 프로세스를 멈추는 역할을 하며,
SIGCONT는 멈춰 있던 프로세스를 다시 실행시키는 역할을 한다.
결국 Signal은 이처럼 프로세스의 상태를 직접 변경하는 역할을 한다고 볼 수 있다.

Signal 발생 원인 (causes of signal generation)
Signal은 여러 상황에서 발생할 수 있다. 사용자가 직접 입력하거나, 다른 프로세스가 신호를 보내는 경우에도 발생할 수 있으며, 프로그램 실행 중 오류가 발생할 때에도 signal이 발생할 수 있다.
예를 들어 어떤 프로그램이 접근하면 안 되는 메모리를 잘못 건드리게 되면 Segmentation Fault라는 오류가 발생하게 된다. 즉, 존재하지 않는 주소에 접근하거나 허용되지 않은 메모리 영역을 접근해서 발생하는 오류라고 볼 수 있다. 이때 운영체제는 SIGSEGV라는 signal을 보내 해당 프로세스에 문제가 발생했음을 알리게 된다.
또한 이러한 경우 외에도 운영체제 내부 이벤트에 의해 signal이 발생할 수도 있다. 예를 들어 control + C를 입력하면 SIGINT가 발생하게 되고, 프로그램 실행 중 잘못된 메모리 접근이 발생하면 SIGSEGV가 발생하게 된다.
즉, signal은 사용자의 입력에 의해서도 발생할 수 있고 프로그램의 오류에 의해서도 발생할 수 있다.

Signal 전달 명령어 (signal delivery commands)
Signal은 내부에서 자동으로 발생하는 것뿐만 아니라, 사용자가 터미널에서 직접 명령어를 입력하여 보낼 수도 있다. 여기서 명령어(command)는 운영체제에 특정 작업을 수행하도록 요청하는 입력이라고 볼 수 있다.
예를 들어 ps 명령어를 사용하면 현재 실행 중인 프로세스 목록이 출력된다. 각 프로세스에는 PID(Process ID)라는 고유 번호가 함께 표시되는데, 이 PID를 기준으로 특정 프로세스를 선택하여 signal을 보낼 수 있다.
여기서 kill 명령어는 특정 프로세스에 signal을 보내는 명령어이다. 이때 kill 뒤에는 어떤 signal을 보낼 것인지 함께 지정할 수 있다.
예를 들어 다음과 같은 명령어를 사용할 수 있다.
kill -SIGTERM 1234
이 경우 PID가 1234인 프로세스에 종료 요청 signal인 SIGTERM을 보내게 된다.
또한 다음과 같은 명령어도 사용할 수 있다.
kill -SIGINT 1234
이 명령은 control + C를 누르는 것과 같은 효과를 가지며, 실행을 중단시키는 signal을 보내게 된다.
즉, ps 명령어로 PID를 확인하고, kill 명령어로 원하는 signal을 지정하여 특정 프로세스를 제어할 수 있다.

control + C와 signal 처리 과정
사용자가 자주 사용하는 control + C를 누르면 프로그램이 바로 종료되는 것처럼 보이지만, 실제로는 signal이 전달되면서 동작이 이루어진다.
사용자가 터미널에서 control + C를 입력하면 터미널이 SIGINT signal을 생성하게 되고, 이 signal이 운영체제를 통해 해당 프로세스에 전달된다. 이후 프로세스에 등록된 signal handler가 실행되면서 그에 맞는 처리가 이루어진다.
여기서 signal handler는 signal이 전달될 때 실행되는 사용자가 정의한 함수(user-defined function)를 의미한다. 이러한 handler는 프로그램 코드 안에서 signal 함수를 사용하여 미리 등록하게 된다.
예를 들어 다음과 같이 설정할 수 있다.
signal(SIGINT, myHandler);
이 경우 SIGINT가 발생했을 때 myHandler 함수가 실행되도록 동작하게 된다.

이 과정을 그림의 흐름으로 보면 다음과 같다.
사용자가 control + C를 입력한다.
터미널에서 SIGINT signal이 생성된다.
해당 signal이 커널(Kernel)로 전달된다.
커널은 signal을 프로세스의 PCB(Process Control Block)에 기록한다.
이후 프로세스에 등록된 signal handler가 실행된다.

Signal 처리 코드 예제 (signal handling code example)
이 코드를 보면 SIGINT가 발생했을 때 어떻게 동작하는지를 확인할 수 있다.
먼저 myHandler 함수는 SIGINT signal을 받았을 때 실행되는 함수이며, 여기서는 "SIGNAL RECEIVED"라는 메시지를 출력하도록 되어 있다.
그다음 main 함수 안에서는 다음과 같이 signal(SIGINT, myHandler)를 사용하여 SIGINT가 발생했을 때 해당 함수가 실행되도록 미리 등록해둔다.
signal(SIGINT, myHandler);
이후 while 문 안에서는 pause()를 계속 호출하면서 signal이 올 때까지 대기 상태를 유지하게 된다.
따라서 실제로 control + C를 입력하게 되면 SIGINT가 발생하고, 이후 등록된 myHandler 함수가 실행되는 흐름으로 동작하게 된다.

Signal 코드 실행 흐름 (signal code execution flow)
이 과정을 순서대로 살펴보면, 먼저 signal(SIGINT, myHandler)를 통해 SIGINT 처리 함수를 등록해둔다.
그다음 사용자가 control + C를 입력하게 되면 SIGINT signal이 생성되고, 운영체제가 해당 signal을 프로세스에 전달하게 된다. 이후 미리 등록해둔 myHandler 함수가 실행되면서 signal에 대한 처리가 이루어진다.
이처럼 signal handler는 일반적인 프로그램 실행 흐름 중간에 개입하여 동작을 변경하는 방식이라고 이해할 수 있다.

Signal 정리
지금까지 살펴본 Signal을 정리해보면, Signal은 일반적인 데이터 전달 방식과는 다르게 동작한다. 즉, Signal은 데이터를 주고받는 것이 아니라 이벤트를 알리고 프로세스를 제어하기 위한 방식이다.
운영체제는 이러한 Signal의 전달을 관리하며, 필요한 시점에 프로세스의 실행 흐름을 변경하는 역할을 하게 된다.
또한 이러한 점에서 Signal은 인터럽트(Interrupt)와 비슷한 방식으로 동작한다고 볼 수 있다.
지금까지 Signal을 중심으로 이벤트 전달과 프로세스 제어 방식에 대해 살펴보았다.
2️⃣ Inter-process communication methods

데이터 전달 기반 IPC (Data-oriented IPC)
방금 배운 Signal이라는 것은 어떤 일이 발생했다는 것을 알려주는 역할이었다면, 실제 프로그램에서는 알림만으로는 부족한 경우가 많다. 예를 들어 한 프로그램이 자신이 만든 데이터를 다른 프로그램이 그대로 받아서 사용해야 하는 상황이 있을 수 있다. 이때는 이벤트가 아니라 데이터 자체를 전달해야 하는 상황이 발생한다.
그래서 프로세스 간에는 데이터를 전달하는 별도의 방법이 필요해진다. 이러한 문제를 해결하기 위해 운영체제는 여러 가지 데이터 전달 방식을 제공한다.

한 프로세스에서 만든 데이터를 다른 프로세스로 순서대로 흘려보내는 방식은 Pipe이다. 서로 관련이 없는 프로세스끼리도 이름을 통해 연결하여 데이터를 주고받는 방식은 FIFO (Named Pipe)이다. 하나의 메모리 공간을 함께 사용하면서 데이터를 직접 공유하는 방식은 Shared Memory (공유 메모리)이다.
이처럼 세 가지 모두 데이터를 전달하기 위한 IPC 방식이지만, 구조와 사용 방법, 목적이 서로 다르기 때문에 상황에 맞게 선택해서 사용하면 된다.
그래서 이러한 방식들은 다음 슬라이드에서부터 하나씩 살펴보자.

Pipe의 개념 (Concept of Pipe)
Pipe (Pipe)는 프로세스 간 통신을 위해 운영체제가 제공하는 방법 중 하나이다.
커널 공간(kernel space) 안에 데이터를 잠시 담아둘 수 있는 통로, 즉 버퍼(buffer)를 만들어두고 한 프로세스가 데이터를 써 놓으면 다른 프로세스가 그 데이터를 꺼내가는 방식이다.
즉, 두 프로세스가 직접 메모리를 공유하는 것이 아니라 운영체제가 가운데에 통신용 공간을 마련해 두고, 그 공간을 통해 데이터를 전달하는 구조이다.
이러한 Pipe는 서로 관련이 있는 프로세스 사이에서 많이 사용되며, 대표적으로 부모 프로세스와 자식 프로세스(parent-child process) 사이의 통신에서 자주 사용된다.

Pipe의 특징 (Characteristics of Pipe)
하나의 pipe 안에서는 데이터를 보내는 쪽과 데이터를 받는 쪽이 구분되어 있다. 즉 하나의 pipe에서는 한 프로세스가 데이터를 보내고, 다른 프로세스는 데이터를 받아 사용하는 구조이다.
따라서 두 프로세스가 서로 번갈아 가며 자유롭게 데이터를 주고받는 방식은 아니고, 한 방향으로만 데이터가 흐르는 단방향 구조라고 이해하면 된다.
또한 pipe 안에 들어간 데이터는 먼저 들어간 것이 먼저 나오는 방식으로 전달된다. 데이터를 넣은 순서 그대로 꺼내가는 구조이다.
이 pipe는 기본적으로 하나의 컴퓨터 내부에 있는 프로세스들 사이에서 사용하는 방식이며, 다른 컴퓨터와 통신하는 용도로는 사용되지 않는다.
만약 두 프로세스가 서로 데이터를 주고받고 싶다면 하나의 pipe만으로는 부족하며, 보내는 방향과 받는 방향을 따로 만들어야 한다. 이 경우 pipe를 2개 사용하면 된다.

Pipe의 동작 구조 (Pipe Operation Structure)
운영체제가 pipe (Pipe)를 만들면 프로세스에게 두 개의 파일 디스크립터(file descriptor)를 반환하게 된다. 여기서 파일 디스크립터는 운영체제가 열어 둔 입출력 대상(input/output resource)을 가리키기 위해 사용되는 번호라고 이해하면 된다.
pipe도 하나의 입출력 통로처럼 다루기 때문에 이러한 파일 디스크립터를 통해 접근하게 된다.
이때 두 개의 디스크립터는 역할이 구분되어 있으며, 일반적으로 다음과 같이 사용된다.
fd[0]: 데이터를 읽는 쪽 (read end)fd[1]: 데이터를 쓰는 쪽 (write end)
즉 pipe는 데이터를 쓰는 쪽과 읽는 쪽이 나눠진 구조로 이해할 수 있다.
따라서 pipe는 겉으로 보기에는 단순한 통로처럼 보이지만, 실제로는 커널(kernel) 내부에 버퍼(buffer)가 생성되고, 그 버퍼에 접근하기 위한 read(), write() 인터페이스와 연결점이 함께 제공되는 구조이다.

Pipe 사용 흐름 (Pipe Usage Flow)
다음은 pipe(Pipe)를 사용할 때의 흐름이다.
먼저 pipe()를 호출하여 프로세스 간 데이터를 주고받을 수 있는 통신 통로를 생성한다. 그다음 fork()를 통해 부모 프로세스(parent process)와 자식 프로세스(child process)를 생성하게 된다.
이렇게 되면 부모와 자식 프로세스는 pipe() 호출로 생성된 파일 디스크립터(file descriptor)를 공유하게 되며, 두 프로세스 모두 읽기용과 쓰기용 디스크립터를 모두 가지게 된다.
하지만 실제로는 한쪽은 데이터를 보내는 역할, 다른 한쪽은 데이터를 받는 역할을 해야 하기 때문에 각 프로세스는 자신이 사용하지 않는 방향의 디스크립터를 닫아 읽기(read)와 쓰기(write)의 역할을 명확하게 나누게 된다.
이렇게 역할이 정리되면 한 프로세스는 write()를 통해 데이터를 pipe에 쓰고, 다른 프로세스는 read()를 통해 해당 데이터를 읽는 구조로 동작하게 된다.

그림의 흐름으로 보면 부모 프로세스와 자식 프로세스가 각각 파일 디스크립터를 가지고 있으며, 한쪽에서는 write()를 통해 데이터를 보내고 다른 한쪽에서는 read()를 통해 데이터를 받아가는 구조로 이루어진다.
이때 데이터는 프로세스 사이를 직접 이동하는 것이 아니라 커널(kernel) 내부에 있는 pipe 버퍼(pipe buffer)를 거쳐 전달된다.
즉, pipe는 프로세스끼리 직접 연결되는 구조가 아니라 커널을 통해 데이터를 주고받는 구조라고 이해할 수 있다.

FIFO의 개념 (Concept of FIFO)
FIFO는 Pipe와 비슷하지만 가장 큰 차이점은 이름(name)을 가지고 있다는 점이다.
Pipe는 부모 프로세스(parent process)와 자식 프로세스(child process)처럼 서로 관계가 있는 프로세스 사이에서 주로 사용된다. 그러나 FIFO는 파일처럼 이름이 존재하기 때문에 서로 관련이 없는 프로세스라도 같은 이름을 알고 있으면 연결하여 사용할 수 있는 구조이다.
즉, 파일 시스템(file system) 안에 특수한 형태의 파일로 만들어두고, 해당 파일을 통해 데이터를 주고받는 방식이라고 볼 수 있다.
다시 말해, 통신 통로를 미리 만들어두고 필요한 프로세스들이 그 통로에 연결하여 데이터를 주고받는 방식이라고 이해할 수 있다.
따라서 FIFO는 Pipe를 확장한 형태이며, 이름을 통해 접근할 수 있는 통신 방식이라고 할 수 있다.

FIFO의 특징 (Characteristics of FIFO)
FIFO는 겉으로는 일반 파일(file)처럼 보이기 때문에 open(), read(), write(), close()와 같은 파일 입출력(file I/O) 방식을 그대로 사용한다.
하지만 실제로는 파일에 데이터를 저장하는 것이 아니라 커널(kernel) 안에 있는 버퍼(buffer)를 통해 데이터를 전달하는 구조이다. 따라서 응용 프로그램(application program) 입장에서는 파일처럼 보이지만, 실제로는 커널 내부 큐(queue)에 저장되어 메모리 기반으로 동작한다고 볼 수 있다.
또한 중요한 점은 여러 프로세스가 하나의 FIFO를 공유하여 통신할 수 있다는 점이다. 이때 데이터는 FIFO 방식과 마찬가지로 먼저 들어간 것이 먼저 나오는 방식으로 처리된다.

FIFO의 동작 구조 (FIFO Operation Structure)
FIFO를 사용할 때 한쪽은 데이터를 보내는 역할로 연결하며, 이는 쓰기 모드(write mode)이다. 다른 한쪽은 데이터를 받는 역할로 연결하며, 이는 읽기 모드(read mode)이다.
이렇게 연결이 이루어지면 한쪽에서 데이터를 쓰고(write), 다른 한쪽에서는 해당 데이터를 읽는(read) 흐름으로 데이터 전달이 이루어진다.
겉으로 보면 파일을 읽고 쓰는 것처럼 보이지만, 실제로 확인해보면 파일 크기는 0바이트로 보이게 된다. 즉, 데이터가 실제 파일에 저장되는 것이 아니라 커널(kernel) 내부 버퍼(buffer)에 임시로 저장되었다가 전달되는 구조이다.
따라서 FIFO는 데이터를 저장하는 파일이라기보다는 프로세스가 접근하기 위한 통신 통로 역할을 한다고 이해할 수 있다.

그림의 흐름으로 보면 한 프로세스는 FIFO를 쓰기 모드로 열고(open), 다른 프로세스는 읽기 모드로 열어서 연결하게 된다. 이후 한쪽에서 write()를 통해 데이터를 보내면 커널 내부의 FIFO 버퍼에 데이터가 저장되고, 다른 한쪽에서는 read()를 통해 데이터를 읽어가는 구조로 동작한다.
여기서 중요한 점은 FIFO가 파일 시스템(file system) 안에 존재하기 때문에 open(), read(), write()처럼 파일을 다루는 방식 그대로 접근할 수 있다는 점이다.
즉, 사용하는 입장에서는 일반 파일을 열고 읽고 쓰는 것처럼 보이지만, 실제로는 데이터가 파일에 저장되는 것이 아니라 커널 내부 버퍼를 통해 바로 전달되고 있다는 점을 이해해야 한다.

FIFO와 Pipe의 비교 (Comparison of FIFO and Pipe)
Pipe와 FIFO는 모두 프로세스 간에 데이터를 전달하는 방식이라는 점에서 비슷하며, 커널 버퍼(kernel buffer)를 통해 데이터를 주고받는 구조도 동일하다. 또한 겉으로는 파일 입출력(file I/O) 방식으로 접근한다는 점에서도 유사하게 보일 수 있다.
하지만 실제로는 차이점이 존재하며, 이를 기준으로 Pipe와 FIFO를 구분할 수 있다.
Pipe는 이름(name)이 없기 때문에 일반적으로 pipe()와 fork()를 통해 생성된 부모 프로세스(parent process)와 자식 프로세스(child process) 사이에서 파일 디스크립터(file descriptor)를 공유하여 사용하는 경우가 많다.
반면 FIFO는 파일 시스템(file system)에 이름을 가진 형태로 생성되기 때문에 서로 관련이 없는 프로세스라도 같은 이름의 FIFO를 열어(open) 연결할 수 있다.
즉, Pipe와 FIFO는 동작 방식은 비슷하지만, 이름을 통해 접근할 수 있다는 점에서 FIFO는 Pipe를 확장한 형태라고 정리할 수 있다.

IPC 방식 비교 (Comparison of IPC Mechanisms)
Signal은 데이터를 전달하는 방식이 아니라 이벤트(event)를 알리고 프로세스를 제어(control)하는 데 사용하는 방식이다.
Pipe와 FIFO는 모두 커널 버퍼(kernel buffer)를 통해 데이터를 전달하는 방식이라는 공통점이 있다. 하지만 Pipe는 주로 부모 프로세스(parent process)와 자식 프로세스(child process) 관계에서 사용되며, FIFO는 이름(name)을 통해 서로 관련 없는 프로세스끼리도 사용할 수 있다는 차이가 있다.
그리고 Shared Memory는 다른 방식과 달리 데이터를 복사하여 전달하는 것이 아니라 하나의 메모리 공간(memory space)을 직접 공유하는 방식이다. 따라서 동기화(synchronization)가 반드시 필요하다.
데이터 전달 속도를 비교하면 일반적으로 Shared Memory가 가장 빠르며, 그다음이 Pipe와 FIFO이다. Signal은 데이터를 전달하는 방식이 아니기 때문에 제한적인 형태의 IPC라고 볼 수 있다.
결국 어떤 IPC 방식을 사용할지는 구조와 목적에 따라 달라진다. 데이터를 얼마나 빠르게 주고받아야 하는지, 프로세스 간 관계가 있는지, 그리고 동기화가 필요한 상황인지를 고려하여 적절한 IPC 방식을 선택해야 한다.
3️⃣ Inter-process Communication Practice
IPC 실행 예제 소개 (Introduction to IPC Execution Examples)
지금까지 Signal과 다양한 IPC 구조 및 특징에 대해서 살펴보았다.
이제부터는 실제 실행 예제를 통해 프로세스 간 통신(Process Communication)이 어떻게 이루어지는지 확인해볼 예정이다.
특히 Signal, Pipe, FIFO, Shared Memory가 실제 코드에서 어떻게 동작하는지, 그리고 데이터가 어떤 흐름으로 전달되는지를 함께 살펴보게 된다.
Signal 처리 실습 내용 안내 (Signal Handling Practice)

1) Signal의 역할 (Role of Signal)
signal() 함수는 특정 signal이 발생했을 때 어떤 함수를 실행할지를 미리 등록(register)하는 역할을 한다. 즉 signal이 발생하면 운영체제가 단순히 기본 동작(default action)을 수행하는 것이 아니라, 사용자가 지정한 함수(handler function)가 실행되도록 설정하는 것이다.
2) 함수 형태 (Function Prototype)
signal() 함수의 형태는 다음과 같다.
void (*signal(int signum, void (*handler)(int)))(int);
이 함수는 첫 번째 인자로 signal 번호(signal number)인 signum을 받고, 두 번째 인자로는 해당 signal 발생 시 실행할 함수(handler function)를 받는다.
여기서 void (*handler)(int) 부분은 “정수 하나를 입력으로 받는 함수”를 의미한다.
즉 사용자가 정의하는 handler 함수는 signal 번호를 인자로 받는 함수 형태로 작성해야 한다.

3) 주요 매개변수 (Main Parameters)
signum은 어떤 signal이 발생했는지를 나타내는 값이다. handler는 해당 signal이 발생했을 때 실행되는 함수이다.
따라서 signal() 함수는 “특정 signal이 발생하면 지정된 함수를 실행하라”라고 등록하는 역할을 수행한다고 이해할 수 있다.
4) signal(SIGINT, myHandler);
다음 코드를 보면:
signal(SIGINT, myHandler);
SIGINT signal이 발생했을 때 myHandler 함수가 실행되도록 연결해두는 의미가 된다.

5) 핵심 동작 (Core Behavior)
실제 동작 흐름을 보면 사용자가 control + C를 입력하면 SIGINT signal이 발생하게 된다.
이때 미리 등록해둔 myHandler 함수가 실행된다. 그리고 handler 실행이 끝나면 프로그램은 다시 원래 실행 흐름으로 돌아가 계속 진행된다.
signal() 예제 코드 (signal() Example Code)

예제 코드를 살펴보면, main() 함수 안의 다음 코드가 먼저 실행된다.
signal(SIGINT, myHandler);
이 코드는 SIGINT signal이 발생했을 때 myHandler 함수가 실행되도록 등록(register)하는 역할을 한다. 그 아래에는 while(1) 반복문이 있으며, 프로그램이 계속 실행되면서 다음 문장을 반복 출력한다.
printf("프로그램 실행중..\n");
그리고 sleep(3)을 통해 3초씩 대기하게 된다.
즉 이 프로그램은 종료되지 않고 계속 실행되면서 signal이 들어오기를 기다리는 상태라고 볼 수 있다. 그런데 이 상태에서 control + C를 입력하면 SIGINT signal이 발생하고, 등록해두었던 myHandler 함수가 실행된다.
void myHandler(int sig) {
printf("\nSIGINT received!\n");
}
실행 결과를 보면 "프로그램 실행중.."이 계속 출력되다가, control + C를 누르는 순간 "SIGINT received!" 문장이 출력된다.
그리고 handler 실행이 끝나면 프로그램이 종료되는 것이 아니라 다시 while 반복문으로 돌아가 "프로그램 실행중.."을 계속 출력하게 된다.
즉 여기서는 control + C가 프로그램을 종료시키는 것이 아니라, 사용자가 정의한 함수만 실행하고 다시 원래 흐름으로 복귀하는 동작을 하게 된다.
따라서 이 프로그램을 완전히 종료하려면 터미널에서 control + \를 눌러 SIGQUIT signal을 보내거나, 다른 터미널에서 kill 명령어를 통해 프로세스를 종료해야 한다.
결국 이 예제는 signal이 발생했을 때 프로그램이 즉시 종료되는 것이 아니라, 등록된 handler 함수가 먼저 실행된 뒤 다시 원래 실행 흐름으로 돌아간다는 점을 보여주는 예제라고 할 수 있다.

Signal 처리 실행 결과 (Signal Handling Execution Result)
코드를 실행하면 프로그램은:
프로그램 실행중..
이라는 메시지를 반복적으로 출력하면서 계속 동작한다. 이 상태에서 사용자가 Control + C를 입력하면 프로그램이 바로 종료되지 않고:
SIGINT received!
라는 메시지가 출력된다.
이 동작은 Control + C 입력으로 인해 SIGINT 시그널(signal)이 발생하고, 미리 등록해두었던 myHandler() 함수가 실행되었기 때문이다. 그 이후 프로그램은 종료되지 않고 다시 반복문(loop)으로 돌아가 계속해서:
프로그램 실행중..
을 출력하게 된다. 즉 여기서는 Control + C 입력이 기본 동작(default action)처럼 프로그램을 종료시키는 것이 아니라, 사용자가 직접 정의한 동작(user-defined handler)으로 변경된 상태라고 이해하면 된다. 따라서 이 상태에서 프로그램을 완전히 종료하려면: Control + \ 를 입력하여 SIGQUIT 시그널(signal)을 보내거나 다른 터미널에서 kill 명령어를 사용하여 프로세스를 종료해야 한다.
결국 이 실습은 동일한 Control + C 입력이라도, 시그널 처리 방식(signal handling)을 어떻게 설정하느냐에 따라 프로그램 동작이 달라질 수 있다는 점을 보여주는 예제라고 볼 수 있다.
Pipe 통신과 pipe() 함수 (Pipe Communication and pipe() Function)

1) 함수의 역할 (Role of the Function)
pipe() 함수는 프로세스 간 데이터를 주고받기 위한 통신 통로(communication channel)를 생성하는 역할을 한다.
**
2) 함수의 형태 (Function Prototype)**
pipe() 함수의 형태는 다음과 같다.
int pipe(int fd[2]);
이 함수가 실행되면 두 개의 파일 디스크립터(file descriptor)를 배열 형태로 반환하게 된다.

3) 주요 매개변수 (Main Parameters)
이때 각 파일 디스크립터의 역할은 다음과 같다.
fd[0]: 데이터를 읽는 쪽 (read end)fd[1]: 데이터를 쓰는 쪽 (write end)
즉 하나의 pipe 안에서 읽기와 쓰기 역할이 구분되어 있다고 이해할 수 있다.
- 핵심 동작 (Core Behavior)
pipe()를 호출하면 해당 통로는 커널(kernel) 내부에 생성된다. 그리고 읽기용(read end)과 쓰기용(write end)이 구분된 pipe 구조가 만들어지게 된다.
이 pipe는 커널 내부에서 생성되기 때문에 프로세스끼리 직접 데이터를 주고받는 것이 아니라, 커널 내부 버퍼(kernel buffer)를 통해 데이터를 전달하게 된다.
또한 fork() 이후에는 부모 프로세스(parent process)와 자식 프로세스(child process)가 파일 디스크립터를 그대로 공유하게 되므로, 두 프로세스는 같은 pipe를 이용하여 통신할 수 있게 된다. 따라서 하나의 pipe를 통해 두 프로세스가 데이터를 주고받을 수 있게 된다.
또한 pipe는 한 방향으로만 데이터가 흐르기 때문에 읽기와 쓰기가 분리된 단방향 통신(unidirectional communication) 구조라고 볼 수 있다.

5) read()와 write()
write() 함수는 fd[1]을 통해 pipe에 데이터를 쓰는 역할을 한다.
반면 read() 함수는 fd[0]을 통해 pipe로부터 데이터를 읽어오는 역할을 한다.
따라서 일반적으로는 부모 프로세스가 데이터를 쓰고(write), 자식 프로세스가 데이터를 읽는(read) 구조로 많이 사용된다.
즉, pipe 통로를 먼저 만들고, 이후 fork()로 프로세스를 분리한 다음, 한쪽은 쓰기(write), 다른 한쪽은 읽기(read)를 수행하는 방식으로 데이터가 전달된다. 결국 pipe는 데이터가 한 방향으로 흐르는 IPC 방식이라고 정리할 수 있다.

Pipe 예제 코드 (Pipe Example Code)
먼저 다음 코드 부분을 보면:
if (pipe(fd) == -1) {
perror("pipe");
exit(1);
}
pipe(fd)를 호출하여 프로세스 간 데이터를 주고받기 위한 pipe를 생성한다.
이때:
fd[0]: 읽기용(read end) 파일 디스크립터(file descriptor)fd[1]: 쓰기용(write end) 파일 디스크립터 로 설정된다.
그다음에는:
pid = fork();
를 통해 부모 프로세스(parent process)와 자식 프로세스(child process)로 분리된다.
자식 프로세스 부분을 보면 다음과 같다.
else if (pid == 0) { // 자식: 읽기
close(fd[1]);
read(fd[0], buf, sizeof(buf));
printf("자식 프로세스가 받은 메시지: %s\n", buf);
close(fd[0]);
}
여기서 close(fd[1]);은 쓰기용(write end) 디스크립터를 닫는 동작이다. 자식 프로세스는 데이터를 읽기만 하기 때문이다.
그다음 read(fd[0], buf, sizeof(buf));를 통해 pipe로 전달된 데이터를 읽어서 buf에 저장하게 된다.
이후 printf()를 사용하여 읽은 데이터를 출력한다.
반대로 부모 프로세스 부분은 다음과 같다.
else { // 부모: 쓰기
close(fd[0]);
char msg[] = "Hello from parent!";
write(fd[1], msg, strlen(msg) + 1);
close(fd[1]);
wait(NULL);
}
부모 프로세스는 읽기용(read end) 디스크립터인 fd[0]을 닫고, write()를 통해 "Hello from parent!" 문자열을 pipe에 기록한다.
이렇게 되면 부모 프로세스가 작성한 데이터가 커널(kernel) 내부의 pipe buffer를 통해 전달되고, 자식 프로세스는 해당 데이터를 읽어서 출력하게 된다.
따라서 실행 결과에서는 자식 프로세스가 부모 프로세스가 보낸 메시지를 받아 "Hello from parent!"를 출력하는 것을 확인할 수 있다.
즉 이 예제는 pipe를 이용하여 부모 프로세스가 데이터를 보내고(write), 자식 프로세스가 해당 데이터를 읽는(read) IPC 구조를 보여주는 예제라고 볼 수 있다.

Pipe 예제 코드 실행 결과 (Pipe Example Execution Result)
다음은 Pipe를 이용한 IPC 예제 코드의 실행 결과이다. 이 예제는 부모 프로세스(parent process)와 자식 프로세스(child process)가 데이터를 주고받는 구조를 확인하기 위한 프로그램이다. 프로그램을 실행하면 부모 프로세스가:
Hello from parent!
라는 메시지를 pipe에 기록(write)하게 되고, 자식 프로세스는 해당 메시지를 pipe로부터 읽어(read) 출력하게 된다. 실행 결과에서는 자식 프로세스가 부모 프로세스로부터 전달받은 메시지를 출력하는 화면을 확인할 수 있다. 겉으로 보면 부모 프로세스와 자식 프로세스가 각각 독립적으로 동작하는 것처럼 보이지만, 실제로는 커널(kernel) 내부의 pipe buffer를 통해 데이터가 전달되고 있다.
또한,
부모 프로세스(parent process)는 write 역할
자식 프로세스(child process)는 read 역할
로 나뉘어 동작하게 된다.
즉 Pipe는 데이터를 한 방향(one-way direction)으로 전달하는 단방향(unidirectional) 통신 구조라는 것을 확인할 수 있다. 결국 이 실습은 Pipe가 부모-자식 프로세스 간(parent-child process)의 통신에서 사용되며, 커널 내부 버퍼(kernel buffer)를 이용하여 데이터를 전달하는 IPC 방식이라는 점을 보여주는 예제라고 볼 수 있다.
FIFO 통신과 mkfifo() 함수 (FIFO Communication and mkfifo() Function)

1) mkfifo()의 역할 (Role of mkfifo())
mkfifo() 함수는 이름 있는 파이프(named pipe), 즉 FIFO 파일을 생성하는 역할을 한다.
일반적인 Pipe는 프로그램 내부에서 생성되지만, FIFO는 파일 시스템(file system) 안에 실제 파일 형태로 생성된다는 특징이 있다.
- 함수 형태 (Function Prototype)
mkfifo() 함수의 형태는 다음과 같다.
int mkfifo(const char *pathname, mode_t mode);

3) 주요 매개변수 (Main Parameters)
pathname: FIFO 파일 이름(path)mode: 접근 권한(permission)을 설정하는 값
을 의미한다. 즉 이 함수를 실행하면 파일 시스템 안에 통신용 FIFO 파일이 생성된다고 볼 수 있다.
- 핵심 동작 (Core Behavior)
이렇게 생성된 FIFO는 일반 파일처럼 한 번 생성해두면 여러 프로그램에서 반복해서 사용할 수 있다.
또한 FIFO는 파일 이름(name)을 기준으로 접근하기 때문에 부모 프로세스(parent process)와 자식 프로세스(child process) 관계가 아니더라도 서로 관련 없는 프로세스끼리 통신할 수 있다. 즉 Pipe가 프로세스 관계 기반으로 연결된다면, FIFO는 “이름(name)” 기반으로 연결되는 구조라고 볼 수 있다.

5) open(), read(), write()
FIFO를 실제로 사용할 때는 open()을 이용하여 FIFO 파일을 열고 통신을 준비하게 된다.
송신 프로세스(sender process)는
O_WRONLY모드로 open수신 프로세스(receiver process)는
O_RDONLY모드로 open 하여 역할을 나누게 된다.
그 후 write()를 통해 데이터를 보내고, read()를 통해 데이터를 읽는 방식으로 통신이 이루어진다.
겉으로 보면 일반 파일 입출력(file I/O)처럼 보이지만, 실제로는 프로세스 간 데이터 전달이 이루어지는 IPC 구조라고 이해하면 된다.

FIFO 송신 예제 코드 (FIFO Sender Example Code)
FIFO 통신에서는 한쪽은 데이터를 보내는 송신(sender) 역할을 하고, 다른 한쪽은 데이터를 받는 수신(receiver) 역할을 하도록 각각 코드를 작성해야 한다.
먼저 데이터를 보내는 송신 측 코드를 보면 다음과 같다.
int main() {
const char *fifo = "myfifo";
mkfifo(fifo, 0666);
int fd = open(fifo, O_WRONLY);
char msg[] = "Hello FIFO!";
write(fd, msg, strlen(msg) + 1);
close(fd);
return 0;
}
먼저:
mkfifo(fifo, 0666);
는 "myfifo"라는 이름의 FIFO 파일을 생성하는 코드이다. 여기서 0666은 FIFO 파일의 접근 권한(permission)을 의미한다. FIFO는 파일 시스템(file system)에 생성되기 때문에 다른 프로그램에서도 동일한 이름으로 접근할 수 있다.
실제로 터미널에서 실행 후 ls 명령어로 확인해보면 "myfifo"라는 파일이 생성된 것을 볼 수 있다. 하지만 이 파일은 일반 파일(regular file)이 아니라 FIFO 형태의 특수 파일(special file)이다. 즉 디스크에 데이터를 저장하는 파일이 아니라, 프로세스 간 통신(IPC)을 위한 통로 역할을 하는 파일이라고 이해하면 된다.
따라서 겉으로 보기에는 파일처럼 보이지만 실제로는 커널(kernel) 내부 버퍼(buffer)와 연결된 입출력 통로이다.
그다음:
int fd = open(fifo, O_WRONLY);
를 통해 FIFO를 O_WRONLY 모드(write-only mode)로 열게 된다. 이는 해당 프로세스가 데이터를 보내는 역할을 수행하겠다는 의미이다. 이후:
write(fd, msg, strlen(msg) + 1);
를 통해 "Hello FIFO!" 문자열을 FIFO에 기록하게 된다. 마지막으로:
close(fd);
를 호출하여 FIFO 파일을 닫게 된다. 즉 이 예제는 FIFO를 생성하고, 송신 프로세스가 데이터를 write()를 통해 FIFO에 전달하는 구조를 보여주는 예제라고 볼 수 있다.

FIFO 수신 예제 코드 (FIFO Receiver Example Code)
다음은 데이터를 받는 쪽인 수신(receiver) 프로그램이다. 수신 측에서도 동일하게 "myfifo"라는 이름의 FIFO를 사용하게 된다. 이번에는 FIFO를 읽기 전용(read-only) 모드로 열어 데이터를 읽는 역할을 수행한다.
예를 들면 다음과 같은 형태이다.
int main() {
const char *fifo = "myfifo";
mkfifo(fifo, 0666);
int fd = open(fifo, O_RDONLY);
char buf[100];
read(fd, buf, sizeof(buf));
printf("수신한 메시지: %s\n", buf);
close(fd);
return 0;
}
여기서:
int fd = open(fifo, O_RDONLY);
는 FIFO를 O_RDONLY 모드(read-only mode)로 열어 데이터를 읽겠다는 의미이다. 그다음:
read(fd, buf, sizeof(buf));
를 통해 FIFO로 들어온 데이터를 읽어서 buf에 저장하게 된다. 이후:
printf("수신한 메시지: %s\n", buf);
를 통해 송신 측에서 전달한 "Hello FIFO!" 문자열이 출력되는 것을 확인할 수 있다.
이 두 프로그램은 서로 독립된 프로그램처럼 보이지만, 동일한 "myfifo"라는 이름의 FIFO를 사용하기 때문에 서로 연결되어 있는 구조이다.
즉 한쪽에서 write()를 통해 데이터를 쓰면, 해당 데이터는 커널(kernel) 내부 FIFO buffer를 통해 전달되고, 다른 한쪽에서는 read()를 통해 그 데이터를 읽어오게 된다.
따라서 실행 결과에서는 "Hello FIFO!"가 출력되는 것을 확인할 수 있다.

FIFO 예제 코드 실행 결과 (FIFO Example Execution Result)
이 코드는 FIFO(named pipe)를 이용하여 두 프로세스가 데이터를 주고받는 과정을 확인하기 위한 예제이다. 여기서는 송신(sender) 프로그램과 수신(receiver) 프로그램을 함께 실행해야 하므로, 10-3 파일과 10-4 파일을 같이 확인해야 한다. 즉 송신과 수신이 동시에 이루어지는 구조이다.
실습에서는 송신 프로그램과 수신 프로그램을 각각 실행해야 하기 때문에 터미널(terminal)을 두 개 사용하였다. 예를 들어 터미널을 우클릭하여 새 창(new terminal window)을 열고, 각각의 터미널에서 해당 폴더로 이동한 뒤 프로그램을 컴파일하고 실행한다.
송신(sender) 프로그램 10-3 을 실행하면:
Hello FIFO!
메시지를 FIFO 파일에 write() 하게 된다.
반면 수신(receiver) 프로그램에서는 FIFO 파일로 전달된 데이터를 read()로 읽고:
printf(...)
를 통해 "Hello FIFO!" 문자열이 출력되는 것을 확인할 수 있다.
여기서 중요한 점은 두 프로그램 중 하나만 실행해서는 정상적으로 동작하지 않는다는 점이다.
예를 들어 송신 프로그램만 실행하면 데이터를 받을 대상(receiver)이 없기 때문에 대기(blocking) 상태가 된다. 수신 프로그램도 마찬가지로 데이터가 들어올 때까지 기다리게 된다.
따라서 이 실습에서는 반드시 두 개의 터미널을 열어서:
송신(sender) 프로그램
수신(receiver) 프로그램
을 각각 실행해야 한다. 이렇게 두 프로그램이 동시에 실행되면:
송신 측은
write()를 통해 데이터를 FIFO에 기록하고커널(kernel) 내부 FIFO buffer를 통해 데이터가 전달되며
수신 측은
read()를 통해 해당 데이터를 읽어오게 된다.
또 하나 확인할 수 있는 점은 ls 명령어를 실행하면 "myfifo"라는 파일이 생성된다는 점이다. 하지만 이 파일은 일반 파일(regular file)이 아니다.
예를 들어 일반 파일처럼 내용을 확인하려고 하면, 실제 데이터가 저장되어 있는 구조가 아니기 때문에 아무 내용도 출력되지 않거나 대기 상태(blocking state)가 될 수 있다.
즉 myfifo는 데이터를 저장하는 파일이라기보다는, 프로세스 간 통신(IPC)을 위한 연결 통로(communication channel) 역할을 하는 특수 파일(special file)이라고 이해하면 된다.
결국 이 실습은 FIFO가 파일 형태(file-like interface)를 사용하지만, 실제로는 커널 버퍼(kernel buffer)를 이용하여 프로세스 간 데이터를 전달하는 IPC 방식이라는 점을 보여주는 예제라고 볼 수 있다.
Shared Memory 통신 (Shared Memory Communication)

1)shm_open()의 역할 (Role of shm_open())
shm_open() 함수는 여러 프로세스가 함께 사용할 공유 메모리 객체(shared memory object)를 생성하거나 여는 역할을 한다.
여기서 중요한 점은 공유 메모리를 변수처럼 바로 사용하는 것이 아니라, 먼저 파일 디스크립터(file descriptor) 형태로 받아온다는 점이다.
즉 shm_open()을 호출하면 공유 메모리에 접근할 수 있는 핸들(handle)을 하나 반환받는 구조라고 이해할 수 있다.
2) 함수 형태 (Function Prototype)
shm_open() 함수의 형태는 다음과 같다. int shm_open(const char *name, int oflag, mode_t mode);

3) 주요 매개변수 (Main Parameters)
name : 공유 메모리(shared memory)의 이름
oflag : 생성 여부 및 읽기/쓰기 옵션 설정 값
mode : 접근 권한(permission) 설정 값
즉 FIFO처럼 이름(name)을 기준으로 여러 프로세스가 동일한 자원(resource)에 접근할 수 있는 구조이다.

4) 핵심 동작 (Core Behavior)
shm_open() 함수로 생성된 공유 메모리는 파일 디스크립터(file descriptor) 형태로 반환된다. 하지만 이것은 실제 디스크 파일(disk file)이 아니라, 공유 메모리 영역(shared memory region)에 접근하기 위한 권한(handle)을 받은 상태라고 이해하면 된다.
따라서 여러 프로세스가 동일한 이름(name)으로 shm_open()을 호출하면 같은 공유 메모리 객체(shared memory object)에 접근할 수 있게 된다.

5) ftruncate()와 mmap()
여기서 중요한 단계가 하나 더 존재한다. shm_open()만으로는 공유 메모리를 바로 사용할 수 있는 상태가 아니다. 먼저:
ftruncate()의 역할 (Role of ftruncate()): ftruncate() 함수를 사용하여 공유 메모리의 크기(size)를 설정해야 한다.
mmap()의 역할 (Role of mmap()): 그다음 mmap() 함수를 사용하여 공유 메모리를 프로세스의 주소 공간(address space)에 연결(mapping)하게 된다.
즉 이 과정을 통해 포인터(pointer)로 접근 가능한 상태를 만들게 된다.

6) 핵심 동작 (Core Behavior)
이렇게 매핑(mapping)이 완료되면 이제는 read()나 write() 함수를 사용하는 것이 아니라, 포인터(pointer)를 이용하여 메모리에 직접 데이터를 쓰고 읽게 된다.
즉 Pipe나 FIFO처럼 중간에서 데이터를 복사하여 전달하는 구조가 아니라, 동일한 메모리 공간을 여러 프로세스가 직접 공유하는 방식으로 동작한다.
따라서 Shared Memory는 매우 빠른 IPC 방식이라고 할 수 있다.
Shared Memory 쓰기 예제 코드 (Shared Memory Writer Example Code)

다음 코드는 공유 메모리(shared memory)에 데이터를 쓰는(write) 예제 코드이다. Shared Memory 통신에서는 데이터를 기록하는 쓰기 프로그램(writer)과 데이터를 읽는 읽기 프로그램(reader)이 각각 필요하다.
먼저 쓰기 코드를 보면 다음과 같은 흐름으로 동작한다.
#define SHM_NAME "/myshm"
#define SIZE 128
위 코드는: 공유 메모리 이름(shared memory name)을 "/myshm"으로 지정하고 공유 메모리 크기(size)를 128 바이트(byte)로 설정한 것이다. 그다음 main() 함수 안을 보면 다음 코드가 나온다.
int shm_fd = shm_open(SHM_NAME, O_CREAT | O_RDWR, 0666);
ftruncate(shm_fd, SIZE);
여기서: shm_open()은 "/myshm"이라는 이름의 공유 메모리 객체(shared memory object)를 생성하거나 여는 역할을 한다. O_CREAT | O_RDWR는 공유 메모리를 생성(create)하고 읽기/쓰기(read/write)가 가능하도록 설정하는 옵션이다. 0666은 접근 권한(permission)을 의미한다.
그다음: ftruncate(shm_fd, SIZE);
를 통해 공유 메모리의 크기를 128 바이트로 설정하게 된다. 이후 다음 코드가 실행된다.
char *ptr = mmap(0, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, shm_fd, 0);
여기서는 mmap() 함수를 사용하여 공유 메모리를 현재 프로세스의 주소 공간(address space)에 연결(mapping)하게 된다. 따라서 이후에는 ptr 포인터(pointer)를 통해 공유 메모리에 직접 접근할 수 있게 된다.
그다음: strcpy(ptr, "Hello Shared Memory!");
를 사용하여 "Hello Shared Memory!" 문자열을 공유 메모리 공간에 직접 기록하게 된다.
즉 Pipe나 FIFO처럼 write()를 사용하는 것이 아니라, 메모리 공간에 직접 문자열을 복사하는 방식으로 동작하는 것이다.
마지막으로:
printf("공유메모리 데이터 저장 완료\n");
와 같은 출력이 나타난다면, 공유 메모리 객체 생성 메모리 크기 설정 메모리 매핑(mapping) 문자열 기록(write) 과정이 정상적으로 완료되었다는 의미가 된다.
즉 이 출력은 단순한 문자열 출력이 아니라, "Hello Shared Memory!" 데이터가 실제 공유 메모리 영역(shared memory region)에 정상적으로 저장되었음을 확인하는 결과라고 볼 수 있다.
Shared Memory 읽기 예제 코드 (Shared Memory Reader Example Code)

다음은 동일한 공유 메모리(shared memory)를 읽는(read) 예제 코드이다.
여기서 중요한 부분은 shm_open()이다. 이 코드는 새로운 공유 메모리를 생성하는 것이 아니라, 이미 존재하는 "/myshm" 이름의 공유 메모리를 열어서 접근하는 코드이다.
즉 앞선 쓰기(writer) 프로그램에서:
O_CREAT | O_RDWR
옵션으로 생성해두었던 공유 메모리를, 읽기(reader) 프로그램에서는 동일한 이름으로 다시 열어서 사용하는 구조이다. 예를 들면 다음 코드가 사용된다.
int shm_fd = shm_open(SHM_NAME, O_RDONLY, 0666);
여기서:
SHM_NAME : 공유 메모리 이름 O_RDONLY : 읽기 전용(read-only) 모드 0666 : 접근 권한(permission) 을 의미한다.
즉 읽기 프로그램은 기존에 생성되어 있는 공유 메모리를 읽기 모드로 열어서 접근하게 된다.
그다음에는 mmap() 함수를 사용하여 해당 공유 메모리를 자신의 주소 공간(address space)에 연결(mapping)하게 된다. 예를 들면 다음과 같은 형태이다.
char *ptr = mmap(0, SIZE, PROT_READ, MAP_SHARED, shm_fd, 0);
이렇게 되면 ptr 포인터(pointer)를 통해 공유 메모리에 직접 접근할 수 있게 된다.
즉 읽기 프로그램도 쓰기 프로그램이 사용했던 동일한 공유 메모리 공간(shared memory region)을 그대로 바라보는 상태가 된다고 이해할 수 있다.
그다음: printf("읽은 데이터: %s\n", ptr);
를 통해 공유 메모리 안에 저장되어 있는 데이터를 출력하게 된다.
실행 결과에서 "Hello Shared Memory!"가 출력되는 이유는 앞서 쓰기 프로그램(writer program)이 동일한 공유 메모리 공간에 해당 문자열을 미리 저장해두었기 때문이다.
즉 읽기 프로그램이 새로운 데이터를 만든 것이 아니라, 공유 메모리에 이미 저장되어 있는 내용을 그대로 읽어오는 구조이다.
정리하면 이 두 프로그램은 서로 다른 독립 프로세스(independent process)이지만, 동일한 이름의 공유 메모리를 사용하기 때문에 서로 연결되어 있다.
따라서:
쓰기 프로그램(writer)은 공유 메모리에 데이터를 저장하고 읽기 프로그램(reader)은 동일한 메모리를 직접 읽게 된다.
즉 Pipe나 FIFO처럼 write()와 read()를 통해 데이터를 전달하는 구조가 아니라, 하나의 메모리 공간(shared memory space)을 여러 프로세스가 동시에 공유하여 접근하는 구조라고 이해하면 된다.

Shared Memory 예제 코드 실행 결과 (Shared Memory Example Execution Result)
다음 실습은 Shared Memory를 이용하여 데이터를 저장하고 읽어오는 과정을 확인하기 위한 예제이다. 여기서는:
10-5.c : 쓰기(writer) 프로그램
10-6.c : 읽기(reader) 프로그램이 사용되었다.
먼저 10-5.c 쓰기 프로그램(writer program)을 실행하면 문자열을 공유 메모리(shared memory) 공간에 직접 기록하게 된다.
즉 화면에 데이터를 출력하는 것이 아니라, 눈에 보이지 않는 공유 메모리 영역(shared memory region)에 데이터가 저장되는 구조이다.
실행 결과에서는 예를 들어:
공유메모리 데이터 저장 완료
와 같은 메시지가 출력된다. 겉으로 보기에는 단순한 출력처럼 보이지만, 실제로는 그 이전 단계에서:
Hello Shared Memory!
문자열이 공유 메모리 공간에 이미 저장된 상태가 된다. 즉 여러 프로세스가 접근 가능한 동일한 공유 메모리(shared memory object)에 데이터가 기록된 것이다.
그다음 10-6 읽기 프로그램(reader program)은 앞서 저장된 공유 메모리 데이터를 읽어오는 과정을 확인하기 위한 예제이다. 쓰기 프로그램(writer)은 데이터를 저장만 했기 때문에, 실제 저장된 내용을 확인하려면 읽기 프로그램(reader)을 실행해야 한다.
읽기 프로그램을 실행하면 다음과 같은 결과가 출력된다.
읽은 데이터: Hello Shared Memory!
여기서 중요한 점은 이 문자열이 현재 읽기 프로그램(reader)이 새로 만든 데이터가 아니라는 점이다. 이 값은 앞서 쓰기 프로그램(writer)이 공유 메모리(shared memory)에 이미 저장해두었던 데이터를 그대로 읽어온 결과이다.
즉 두 프로세스가 동일한 공유 메모리 공간(shared memory space)을 함께 바라보고 있기 때문에, 별도의 데이터 복사(copy) 과정 없이 데이터를 직접 읽을 수 있게 된다.
결국 이 실습은 Shared Memory가 데이터를 전달(transfer)하는 방식이 아니라, 메모리 공간(memory space) 자체를 여러 프로세스가 공유(shared)하는 IPC 방식이라는 점을 보여주는 예제라고 볼 수 있다.




